
When Andrej Karpathy posted about his LLM knowledge base workflow on April 3, 2026, most of the discussion treated it as a personal research productivity system. That reading is too narrow. The underlying architecture — accumulate raw material, compile it into structured markdown, query and maintain it with an LLM — maps directly onto a problem that anyone running coding agents at session scale has already hit: the context reset.
This piece applies Karpathy's pattern to engineering workflows specifically. Not knowledge management as a hobby. Knowledge management as infrastructure for multi-agent coding sessions.
What an LLM Knowledge Base Actually Is (Not a RAG System)
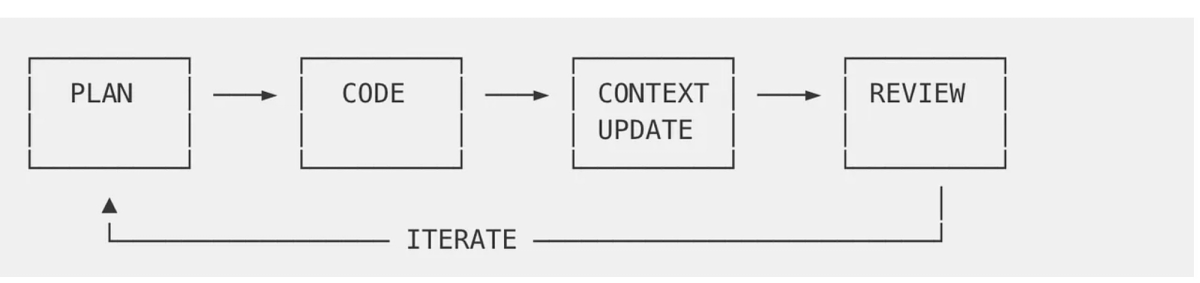
The Karpathy Pattern: Raw → Compile → Lint → Query
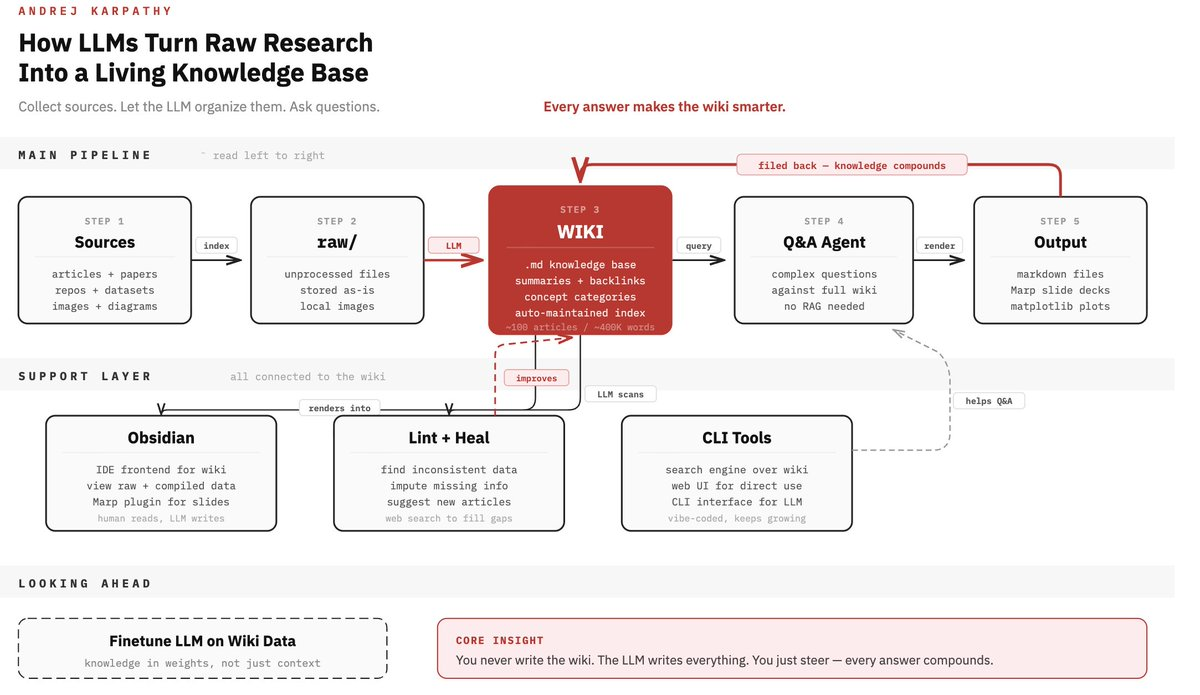
The system has four phases that run in a continuous cycle. Raw source material — in Karpathy's case articles, papers, and datasets; in a coding context, architecture docs, decision logs, API contracts, and code comments — lands in a raw/ directory. An LLM then "compiles" this into a structured wiki: a collection of markdown files organized by concept, with summaries, backlinks between related ideas, and index files that help the LLM navigate at query time. The compilation step is the architectural innovation. The LLM isn't just indexing — it's synthesizing, categorizing, and creating connections that didn't exist explicitly in the source.
Linting passes run periodically: the LLM scans the wiki for stale information, internal inconsistencies, missing links, and new connection opportunities. Karpathy describes it as health checks that "incrementally clean up the wiki and enhance its overall data integrity." Every query result, every generated output, gets filed back into the wiki. The system compounds rather than resets.
At the scale Karpathy describes — roughly 100 articles and around 400,000 words — no vector database is needed. Index files and summary pages, loaded into the LLM's context window, are sufficient for navigation. The LLM finds what it needs through structure, not embedding similarity.
Why RAG Rediscovers Knowledge from Scratch Every Time
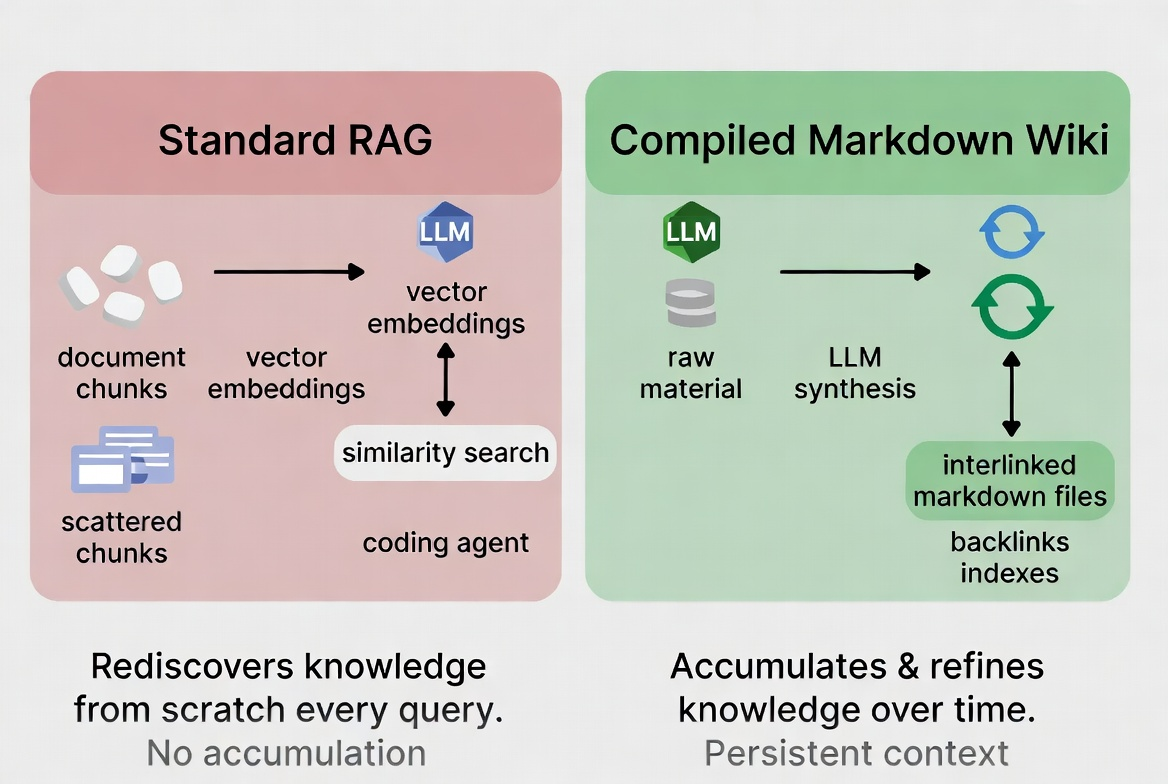
Standard RAG — as defined in Lewis et al.'s foundational 2020 paper — splits documents into chunks, converts them to vector embeddings, and runs similarity searches at query time. The chunks don't know about each other. Connections between a decision made in March and a constraint documented in January don't exist in the index unless both happen to surface in the same retrieval pass. Every query starts from scratch.
Karpathy's framing is precise: "the LLM is rediscovering knowledge from scratch on every question. There's no accumulation." For personal knowledge bases and small-to-medium codebases, this is the wrong tool. RAG was designed to scale retrieval over millions of documents with unpredictable access patterns — a design tradeoff that Agentic RAG research has since tried to address by embedding autonomous agents into the retrieval pipeline, but at the cost of significantly more infrastructure complexity. A compiled markdown wiki needs neither.
The distinction matters for coding agents because your project's architecture doesn't change arbitrarily — it evolves deliberately. A system that accumulates and refines knowledge about your codebase over time is more useful than one that re-derives it from raw files on every invocation.
The Real Problem for Coding Agents: Context Resets
What Happens When a Multi-Agent Session Hits a Context Limit
In a multi-agent coding setup — parallel worktrees, isolated subagents handling separate tasks — each agent starts with whatever context you give it and works until it either completes or hits a context boundary. When a session compacts or a new agent spins up, the project knowledge it had is gone. What survives is only what's in files on disk.
The practical consequence: the next agent, or the next session of the same agent, reads the codebase cold. It can read the code, but it can't read the reasoning. Why does the auth module use a custom token format instead of JWT? Why is the payment service isolated in its own worktree instead of living in the main repo? Why did you decide against the architecture described in the design-v1.md document that's still sitting there? None of that is in the code. It was in the conversation.
With a compiled wiki, it is in the files. The agent reads architecture/decisions/auth-token-format.md, understands the tradeoffs that were evaluated, and proceeds without asking you to re-explain.
Re-Explaining Architecture to the Agent: The Hidden Token Tax
Every time you re-establish context for a new agent session, you're spending tokens on history rather than on work. For a moderately complex project with three active subsystems, a non-trivial tech stack, and a few architectural constraints that matter, this re-establishment pass can run 5,000–15,000 tokens before any actual task begins. Multiply that across 10 agent sessions per day and the overhead becomes real — both in cost and in latency.
The deeper problem is that re-explanation is lossy. You summarize from memory, you miss the edge case you worked through last week, the agent proceeds on incomplete context and produces something subtly wrong. You correct it. That correction should be durable. In most agent workflows, it isn't.
How an LLM Knowledge Base Fixes the Context Problem

Persistent Markdown Wiki as the Agent's Memory Layer
The mechanism is straightforward: a wiki directory that lives alongside your codebase. The agent reads it at session start, updates it as decisions are made, and the next session picks up where the last one left off. No embeddings, no vector index, no separate infrastructure. Plain markdown, under version control, readable by both humans and agents.
Claude Code supports this directly. As Claude Code's official memory documentation explains, CLAUDE.md files are loaded into the context window at session start automatically. For content that's too detailed to live in CLAUDE.md itself, the @path import syntax lets you reference external markdown files — the CLAUDE.md acts as a table of contents and the wiki pages load on demand. The official Claude Code documentation recommends keeping CLAUDE.md under 200 lines and breaking larger instruction sets into .claude/rules/ subdirectory files, each scoped to relevant file paths. A wiki naturally fits this structure: domain-specific knowledge loads only when the agent is working in the corresponding part of the codebase.
Ingest → Compile → Query Cycle Applied to a Codebase
Adapted to an engineering context, the cycle looks like this:
Ingest: New architectural decisions, API contract changes, dependency updates, post-mortems, and design discussions go into raw/. You can use comments in commit messages, PR descriptions, or a lightweight daily log. The raw layer is intentionally unstructured — its only requirement is that it exists and is dateable.
Compile: The agent reads new raw entries and updates the wiki. A decision to migrate from REST to gRPC on the data service becomes an update to architecture/protocols/grpc-migration.md, with backlinks to the services affected and a cross-reference to the latency benchmarks that motivated the change. The agent writes; you review.
Query: At session start, the agent loads the relevant wiki sections via CLAUDE.md imports. When it needs to understand why the auth system works the way it does, it reads the wiki instead of asking you. Outputs — refactoring proposals, design alternatives, debugging hypotheses — get filed back as new raw entries or directly as wiki updates.
Lint: Periodically, run a maintenance pass. Ask the agent to scan for wiki pages that reference code paths that no longer exist, flag decisions whose rationale has become obsolete, and identify gaps where new raw material hasn't been compiled yet.
Where This Beats RAG and Where It Doesn't
This pattern is better than RAG when: your knowledge corpus is bounded (hundreds of documents, not hundreds of thousands), the content evolves deliberately and benefit from accumulated understanding, and you need agents across multiple sessions to share a coherent view of the project.
It's worse than RAG when: the corpus is genuinely large (millions of tokens, thousands of documents with heterogeneous access patterns), retrieval requirements are unpredictable, or the latency overhead of embedding-based search is acceptable in exchange for scale. Large engineering organizations with multiple repos and hundreds of services probably need both — a RAG layer for broad retrieval and a compiled wiki for project-specific context.
The stale content problem is real either way. A wiki that isn't maintained is worse than no wiki — it gives the agent confident wrong information. Linting passes help, but they don't replace human review of significant architectural changes.
Practical Setup for a Coding Project
Directory Structure: raw/, wiki/, Index
A minimal setup:
project-root/
├── CLAUDE.md # Loads wiki index; stays under 200 lines
├── .claude/
│ └── rules/
│ ├── backend.md # Scoped to src/api/**
│ └── frontend.md # Scoped to src/ui/**
└── wiki/
├── INDEX.md # Top-level wiki navigation
├── architecture/
│ ├── overview.md
│ ├── decisions/ # ADRs — one file per decision
│ └── protocols/
├── domains/ # Business domain glossary
├── ops/ # Deployment, environment, dependencies
└── raw/ # Uncompiled source materialCLAUDE.md contains @wiki/INDEX.md and project-level conventions. The index file maps subsystems to their wiki sections. The agent navigates the structure the same way a human engineer would.
Which Tools Fit: Obsidian, Claude Code, Local Scripts

Obsidian works well as the human-facing frontend: graph view shows link density and reveals orphaned pages, the web clipper ingests external references directly as markdown, and it renders the wiki locally without any server dependency. Karpathy uses it this way — as a read/navigate layer, not as the write layer. The agent does the writing.
Claude Code is the compilation and maintenance engine. You point it at raw/ with a prompt like "compile any new entries in raw/ into the wiki, update affected index pages, and create backlinks where appropriate." In Verdent's parallel agent setup, you can run wiki maintenance as a background task in a dedicated worktree while other agents continue coding work in isolation.
Local scripts can automate the ingest side: a git hook that appends significant PR descriptions to raw/, a cron that pulls new issues tagged arch-decision into raw/, or a simple CLI that lets you log a quick note from the terminal. The simpler the ingest friction, the more consistently the wiki gets fed.
What to Put in the Wiki vs What to Leave in the Codebase
The wiki is for reasoning that doesn't belong in code. Code documents what the system does. The wiki documents why it does it that way, what alternatives were considered, and what constraints shaped the decision.
Wiki: Architectural decisions and their rationale. Domain terminology and entity relationships. External dependency notes (why this library, what its known limits are, when to reconsider it). Environment and deployment constraints that affect development decisions. Recurring debugging patterns for known hard problems.
Codebase: API contracts, type definitions, inline comments explaining non-obvious logic, test cases, configuration. Everything that a new engineer should learn from the code itself.
If you find yourself adding explanatory context to the wiki that should really be a docstring or an inline comment, the code needs better documentation, not a better wiki.
Limitations and Trade-offs to Know Before You Build
Maintenance Cost: Who Lints the Wiki?
A wiki that isn't maintained actively misleads. The linting pass helps — the agent can identify internal inconsistencies, dead links, and references to deprecated code paths — but it can't know when an architectural assumption that was correct six months ago is now wrong because the external constraint changed. That requires human judgment.
In practice, this means someone on the team needs to own the wiki the same way someone owns the architecture. Not as a full-time job, but as a recurring responsibility: reviewing compiled entries, running linting passes after significant changes, and occasionally rewriting sections that have drifted too far from current reality. If no one owns it, it degrades faster than it accumulates value.
Scale Ceiling: Sweet Spot Is Hundreds, Not Millions of Docs
Karpathy describes his setup as around 100 articles and roughly 400,000 words — VentureBeat's coverage of the post notes that at this scale, the LLM's ability to navigate via summaries and index files is "more than sufficient" without vector database infrastructure. At that scale, index files and LLM context windows are enough to navigate without embedding infrastructure.
Beyond that — multiple large repos, years of decision history, cross-team knowledge — the context window approach starts to strain. Navigation through summaries and indexes works until the index itself becomes unwieldy. This isn't a failure of the pattern; it's a scope boundary. For larger codebases, a compiled wiki handling the most recent and most frequently accessed context, combined with a RAG layer for broader retrieval, is a more realistic architecture.
This scale ceiling is community observation, not a formally published benchmark. Your specific project's knowledge density, how often wiki sections get accessed, and how aggressively you maintain the index all affect where the practical ceiling sits.
Not a Replacement for Proper Codebase Documentation
The wiki doesn't replace documentation — it operates alongside it. A well-structured README, comprehensive API docs, and clear inline comments mean the agent needs less wiki to understand the codebase. A wiki covering what the code can't express means agents and engineers spend fewer tokens on archaeology.
Trying to use the wiki as a substitute for code documentation creates a maintenance problem with two moving parts instead of one. Keep the division of responsibility clear: code for what, wiki for why.
FAQ
What's the Difference Between an LLM Knowledge Base and RAG?
RAG retrieves relevant chunks from a document collection at query time using embedding similarity — each query starts fresh, no knowledge accumulates. An LLM knowledge base has the LLM actively compile raw sources into structured, interlinked markdown, building understanding incrementally over time. The compiled wiki reflects synthesized knowledge; RAG reflects indexed documents. For bounded corpora where context builds on itself, the compiled wiki approach produces more coherent agent behavior. For large, heterogeneous document sets where any document might be relevant to any query, RAG is more appropriate.
Does This Work with Claude Code or Other AI Coding Agents?
Yes, directly. Claude Code's CLAUDE.md system loads markdown files at session start, and the @path import syntax lets CLAUDE.md reference wiki pages without embedding their full content in the main file. The .claude/rules/ directory supports path-scoped rules that load only when the agent works in matching parts of the codebase — a natural fit for subsystem-specific wiki pages. Verdent agents running in isolated git worktrees can share a common wiki directory, giving parallel agents a consistent view of project context without conflicting writes if write access is coordinated through a dedicated compilation agent.
How Big Does a Project Need to Be to Justify This Setup?
The break-even point is roughly when re-explaining project context at session start takes longer than maintaining the wiki would. For a solo developer on a single focused project, a well-structured CLAUDE.md might be enough. For a project with multiple subsystems, several active agents, and more than a few weeks of non-trivial architectural decisions, the accumulated cost of context re-establishment makes the wiki worthwhile. The setup overhead is low — you're creating directories and markdown files, not deploying infrastructure. Start small: one architecture decisions directory, one domain glossary, and CLAUDE.md pointing at them.
Can Multiple Agents Share the Same Knowledge Base?
Yes, with coordination. The wiki is files on disk — any agent with filesystem access can read it. Write access requires care: simultaneous compilation passes from multiple agents can produce conflicting edits. The practical approach is a designated compilation agent that has write access to the wiki, while task agents have read-only access (or write access only to raw/, leaving compilation as a separate step). In git worktree setups, the wiki can live in its own worktree, ensuring task agents pull clean reads without interfering with ongoing compilation.
What Happens When Code Changes But the Wiki Isn't Updated?
The agent gets confidently wrong context, which is worse than no context. This is the central maintenance risk of the pattern. Mitigation strategies: run linting passes after significant code changes, using the agent to flag wiki pages that reference modified or removed code paths; scope wiki entries to decisions and rationale rather than implementation details (rationale ages more slowly than code); and treat wiki staleness as a real maintenance cost when evaluating whether the pattern is worth running for your project. A wiki with a clear owner and a regular lint cadence degrades gracefully. A wiki maintained only on enthusiasm degrades fast.
Related Reading
- Claude Code vs Verdent: Multi-Agent Architecture Compared — How parallel agent execution affects context management, and where a shared knowledge base fits in a worktree-isolated workflow.
- Claude Code Auto Mode and Cloud Auto-Fix — The autonomous execution patterns that make persistent project context most valuable.
- What Is Model Context Protocol? — How MCP tool integration relates to the broader context management problem in agentic workflows.
- Lark CLI: Automate Dev Notifications with AI Agents — Operational layer for multi-agent workflows — how to wire session outputs into team communication.
- Claude Code Pricing 2026: Every Plan Explained — Token costs matter when context re-establishment is eating sessions; understanding the billing model helps optimize the tradeoff.
