
Z.ai dropped GLM-5V-Turbo on April 1, 2026 — timing that made some developers look twice before clicking the announcement link. It turned out to be real. What's worth understanding is not just what the model does, but where it sits in a family of releases that have been arriving quickly enough to create genuine naming confusion. This is a technical explainer for developers evaluating it as a component in agentic workflows, not a product review or launch summary.
What Is GLM-5V-Turbo?
The Three-Model Triangle
Z.ai (formerly Zhipu AI, rebranded internationally in July 2025 and listed on the Hong Kong Stock Exchange in January 2026) has built out three distinct models in its current GLM-5 generation, and conflating them will send you in the wrong direction:
GLM-5 — The open-source base model, released in February 2026, available on HuggingFace under MIT license. Text-only, with strong coding and reasoning benchmarks. This is the model you can self-host and fine-tune. When people talk about GLM-5's open-source credentials, this is what they mean.
GLM-5-Turbo — A closed-source, commercial variant released March 16, 2026. Text-only. Tuned specifically for agent execution: tool calling stability, long-chain task completion, and OpenClaw workflow integration. Think of it as an execution-optimized derivative of GLM-5, not a successor to it. It's faster, has a slightly lower per-token price than GLM-5 via API, and was built for the scenario where you need an agent to reliably complete 50-step tasks without failing on tool invocations.
GLM-5V-Turbo — Released April 1, 2026. Closed-source. The first native multimodal model in the family: it takes images, video, and text as input, not just text. Inherits the agent-optimization work from GLM-5-Turbo and adds vision. The "V" is the meaningful addition here — it's not a speed or pricing variant, it's an architecture change that adds visual perception as a first-class input.
The practical implication of this triangle: if your task starts with text and ends with text, GLM-5 or GLM-5-Turbo is the right conversation. GLM-5V-Turbo is worth evaluating only when your workflow includes visual inputs that the model needs to reason about and act on.
What Makes It Different: Native Multimodal Fusion
CogViT + MTP Architecture
The core architectural choice that distinguishes GLM-5V-Turbo from models that accept image inputs as an afterthought is the CogViT vision encoder. In many vision-language systems, a separate vision model produces a text description of the image, which is then fed to the language model as another text prompt. GLM-5V-Turbo was trained with vision as a native input modality — the CogViT encoder processes spatial hierarchies and visual detail in parallel with text, rather than compressing them into a textual intermediate.
The other architectural note is Multi-Token Prediction (MTP), which is intended to improve inference efficiency on long outputs. For vision-to-code tasks, where the model may generate hundreds of lines of frontend code from a single design image, output latency matters. MTP helps here, though see the latency section below for the honest picture.
From "Describe an Image" to "Generate Runnable Code"
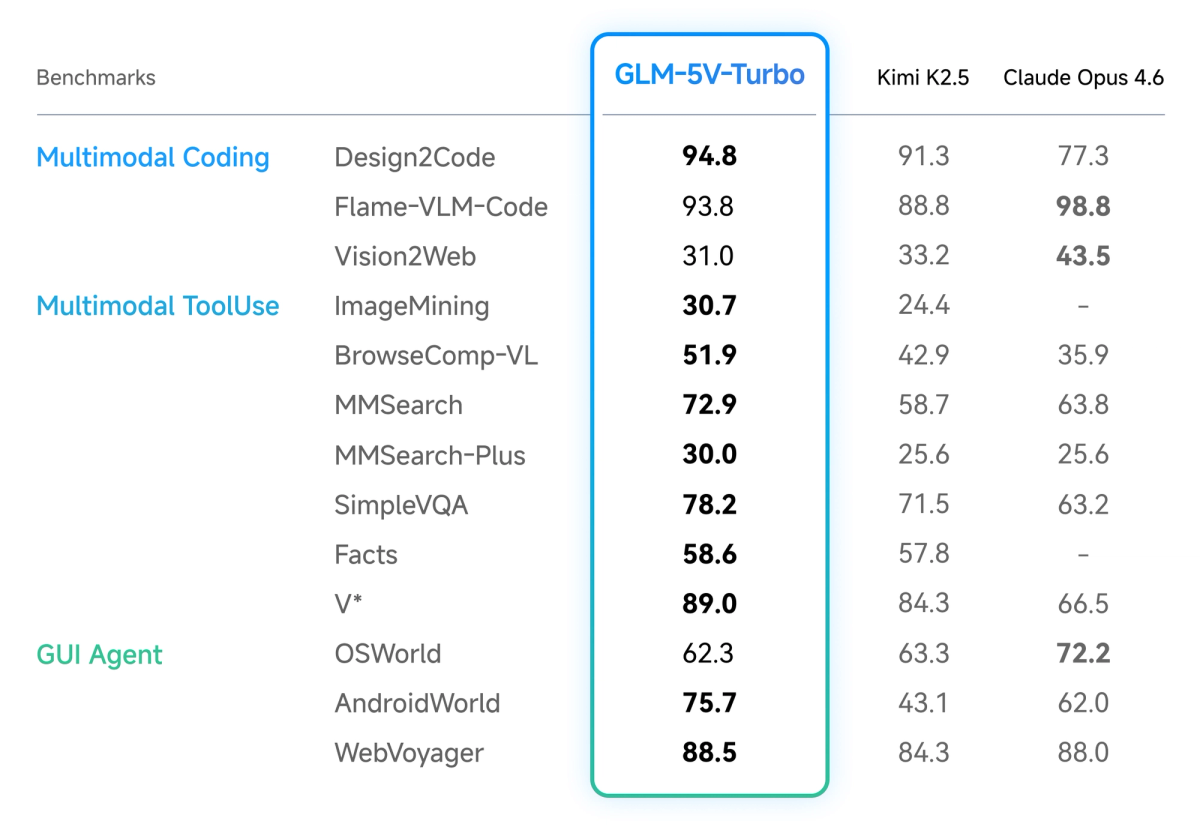
The capability claim Z.ai makes is specific: given a design mockup, screenshot, or wireframe, GLM-5V-Turbo can generate a runnable frontend project — not just describe what it sees. The model reports a Design2Code score of 94.8 versus Claude Opus 4.6's 77.3 in Z.ai's own benchmarks. That's a gap worth noting, with the major caveat that this is company-reported data; independent validation on the specific Design2Code benchmark used here hasn't been published as of this writing.
The mechanism is the 30+ Task Joint Reinforcement Learning approach. Rather than optimizing visual recognition and coding capability sequentially (which tends to create a seesaw effect where improving one degrades the other), Z.ai trained across STEM reasoning, visual grounding, video analysis, and tool use simultaneously. Whether this fully resolves the tradeoff or just shifts it is something independent testing will need to answer.
Context Window and Output Capacity
Context window: approximately 202,752 tokens. Max output: 131,072 tokens. Both figures are confirmed on Z.ai's official pricing page. For reference, 200K tokens is enough to hold a mid-sized frontend codebase plus documentation and still have room for extensive visual inputs.
Key Capabilities for Engineering Workflows
Vision-to-Code: Design Draft to Frontend Project
The headline use case is generating frontend code from visual input. Feed the model a Figma export, a screenshot of an existing UI you want to replicate, or a hand-drawn wireframe, and it produces HTML, CSS, and JavaScript. Z.ai's documentation describes both wireframe reconstruction (which recovers structure and functionality) and high-fidelity design matching (which aims for pixel-level visual consistency).
This is useful for: initial component scaffolding from design specs, UI migration projects where you have screenshots of the old interface, and generating variation explorations from a reference image. It's not a replacement for production frontend engineering, but it can eliminate significant manual translation work between design and first-draft code.
GUI Agent: WebVoyager and AndroidWorld
Beyond static image-to-code, the model demonstrates GUI agent behavior on two benchmark environments Z.ai cites from its documentation: WebVoyager (browser navigation) and AndroidWorld (Android interface interaction). Both measure whether the model can observe a UI environment, plan a series of actions, and execute them without human intervention. Strong performance on these suggests the model can operate as a subagent in workflows that require visual environment interaction — navigating a web interface to extract structured data, or completing a multi-step workflow in a desktop or mobile app.
Long-Chain Task Stability
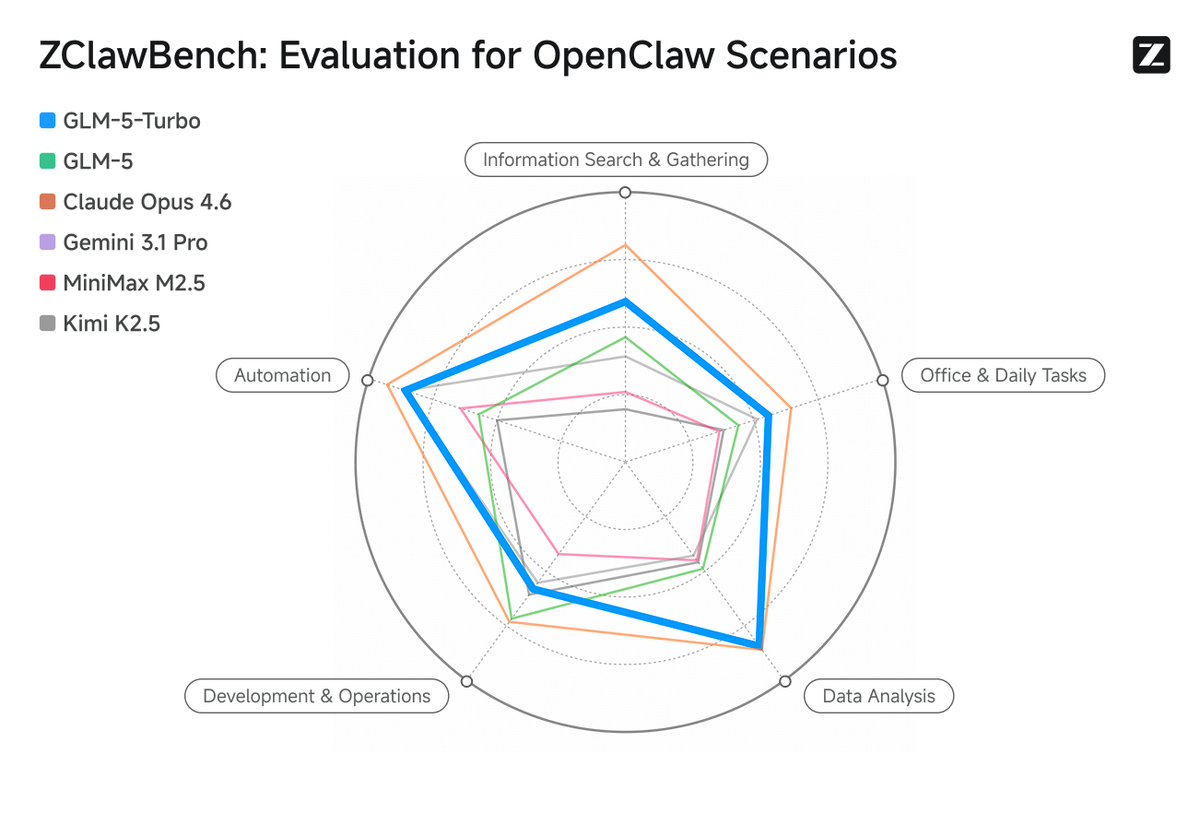
GLM-5V-Turbo inherits the long-chain stability work from GLM-5-Turbo: tool invocation reliability, command following across extended task sequences, and the perceive → plan → execute loop designed for autonomous execution without frequent failure points. For agent pipelines where a broken tool call requires restarting the entire chain, this is a meaningful engineering concern. Z.ai's own ZClawBench results (proprietary benchmark, see limitations section) show improvement over the base GLM-5 on these dimensions.
Who Is It Built For?
OpenClaw Users
GLM-5V-Turbo was explicitly designed with the OpenClaw ecosystem in mind. Z.ai has published official Skills on ClawHub for the model, covering image description, visual grounding, prompt refinement from images, and other vision-specific tools. The model's training incorporated OpenClaw task patterns, which means its tool-calling behavior and multi-step execution are tuned for that environment. If you're running OpenClaw workflows and need a subagent that can handle visual inputs as part of longer chains, this is the most directly relevant option.
Claude Code Integration Scenarios
Z.ai explicitly positions GLM-5V-Turbo as a complement to Claude Code — not a replacement. The announcement describes "deep synergy" with Claude Code workflows. The practical scenario here is task delegation: a Claude Code session that needs visual analysis or frontend code generation from a mockup could route that specific subtask to GLM-5V-Turbo via API, then receive structured output back. This is multimodal subagent architecture rather than a full swap.
Agent Engineers Handling Visual Inputs
If you're building agentic systems that process screenshots, design files, UI recordings, or document images as part of their execution loop — and you need a model that can close the loop from visual input to structured action or code output — GLM-5V-Turbo is one of the few purpose-built options available via API. The $1.20/$4.00 per million token pricing on OpenRouter makes it meaningfully cheaper than alternatives for high-volume visual processing.
Who Should Not Prioritize It
If your coding workflow is text-in, text-out — backend logic, API integration, repository exploration, refactoring — the visual encoder adds cost and latency without adding capability. GLM-5 or GLM-5-Turbo will serve those use cases better at comparable or lower cost. The model's own benchmark comparisons show Claude Opus 4.6 leading on pure text coding tasks like Flame-VLM-Code and OSWorld.
Current Limitations and What's Still Unknown
Closed-Source API Only

GLM-5V-Turbo is not open-source. This contrasts with GLM-5, which is available on HuggingFace under MIT license. You cannot self-host GLM-5V-Turbo, inspect its weights, or fine-tune it. Z.ai has stated that findings from the Turbo variants will inform future open-source releases — but that's not a commitment to open-source GLM-5V-Turbo itself. For organizations with data residency requirements or policies about using Chinese-operated AI infrastructure, this matters. Z.ai is a Chinese company subject to Chinese data law; review their privacy policy against your compliance posture before routing sensitive data through the API.
Pricing: Confirmed on OpenRouter, Additional Tiers Under Development
Per OpenRouter as of April 2026: $1.20 per million input tokens, $4.00 per million output tokens. Z.ai also offers a GLM Coding Plan subscription starting around $9/month for developers who want plan-based access, but the Coding Plan feature for GLM-5V-Turbo is currently in trial — access requires applying via a Google Form that Z.ai shared at launch. If you need Coding Plan access now, check current availability at Z.ai's documentation before planning around it.
Benchmark Provenance
The key benchmarks cited — Design2Code, CC-Bench-V2, ZClawBench, ClawEval, PinchBench — are a mix of industry-standard and proprietary evaluations. ZClawBench and ClawEval are Z.ai's own benchmarks, designed around OpenClaw task patterns. The company has released the ZClawBench dataset for community validation, which is a positive signal. But as of this writing, independent reproduction of the headline numbers hasn't been published. Design2Code is an existing benchmark, but Z.ai's specific testing methodology hasn't been externally audited. Treat the benchmark comparisons as directional, not definitive, until third-party validation catches up.
Speed: 34th Percentile
On speed relative to other available models, GLM-5V-Turbo ranks in the 34th percentile — moderately slow. For real-time interactive use cases, this is a real constraint. For batch processing, offline agent pipelines, or tasks where output quality matters more than latency (design-to-code generation, visual analysis), it's less of an issue. Factor inference speed into your architecture decisions if your use case requires responsive multi-turn agent behavior.
Parameter Count Not Publicly Disclosed
One source cites 744B parameters in a Mixture-of-Experts architecture with 40B active per token, but this is not confirmed in Z.ai's official documentation as of this writing. Do not treat this figure as authoritative. Z.ai has not published a formal model card with confirmed parameter counts for GLM-5V-Turbo.
FAQ
GLM-5V-Turbo vs GLM-5-Turbo: What's the Difference?
The "V" is the key: GLM-5V-Turbo adds native vision processing. GLM-5-Turbo is text-only, optimized for agent execution (tool calling, long chains, OpenClaw workflows). GLM-5V-Turbo inherits all of that and adds the CogViT vision encoder plus multimodal training. Both are closed-source and available via API. The pricing on OpenRouter is approximately the same: $1.20 input / $4.00 output per million tokens for both. Choose GLM-5-Turbo if your tasks are text-only; choose GLM-5V-Turbo if you need to process visual inputs as part of the agent loop.
Is GLM-5V-Turbo Open Source?
No. GLM-5V-Turbo is closed-source, API-only. This is the same situation as GLM-5-Turbo. The open-source GLM model in the current generation is GLM-5 (text-only, available on HuggingFace under MIT license). Z.ai has signaled that learnings from the Turbo models will feed into future open-source releases, but GLM-5V-Turbo itself is not and does not appear scheduled to be open-sourced.
Where Can I Call the GLM-5V-Turbo API?
Two paths: directly through Z.ai's platform at docs.z.ai (OpenAI-compatible API, requires a Z.ai API key), or via OpenRouter at z-ai/glm-5v-turbo. Both support function calling, streaming, and structured output. You can also try the model at chat.z.ai without an API key. For the Coding Plan subscription tier, trial applications are currently open via a Google Form linked from Z.ai's official announcement.
What Visual Input Types Does It Support?
Images (design mockups, screenshots, wireframes, document layouts), short video clips, and text in the same context. Z.ai's documentation specifically covers design-to-code generation from Figma-style exports, wireframe reconstruction, screenshot-based UI replication, and screen recording analysis. The model also supports bounding-box drawing and webpage screenshot reading as part of its expanded multimodal toolchain.
Is It Suitable as a Subagent in AI Coding Agent Systems?
For tasks involving visual inputs: yes, it's one of the more purpose-built options available. For text-only coding subtasks: GLM-5-Turbo or GLM-5 will perform comparably at lower or equivalent cost without the overhead of a vision encoder. The architecture fits a delegation pattern — a coordinating agent routes visually-grounded tasks to GLM-5V-Turbo, receives structured output, and continues the chain. The 34th-percentile speed ranking and the current trial status of the Coding Plan are operational constraints to evaluate before committing to it as a production component.
Related Reading
- Claude Code vs Verdent: Multi-Agent Architecture Compared — For teams evaluating how to wire multimodal subagents like GLM-5V-Turbo into a broader parallel coding workflow.
- Claude Skills vs MCP vs Agents: Key Differences — Understanding the skill and subagent architecture that GLM-5V-Turbo plugs into via ClawHub Skills.
- Best Claude Code Alternatives for Agentic Workflows in 2026 — The broader tool landscape for developers evaluating their agent stack.
- Claw Code: Claude Code, OpenClaw, and What Each Actually Does — Background on the OpenClaw ecosystem that GLM-5V-Turbo was optimized for.
- What Is Model Context Protocol? — How MCP tool integration relates to the agentic execution patterns GLM-5V-Turbo is built around.
