
Friday morning, February 20, I was mid-sprint reviewing a PR when the Slack notification came in: "Anthropic just dropped something big." I nearly dismissed it — honestly, "big AI announcements" happen every other week now. Then I saw CrowdStrike down 8%, Okta down 9.2%, SailPoint shedding over 9% in a single session. That's not hype. That's the market pricing in a genuine capability shift. I spent the weekend digging into Claude Code Security — what it actually does, where it falls short, and whether it belongs in a production security workflow today. Here's my honest breakdown.
What Is Claude Code Security? (Launched Feb 20, 2026)
Claude Code Security is a new capability built directly into Claude Code on the web. It scans your entire codebase for security vulnerabilities and suggests targeted patches — all for human review before anything gets merged. As of launch, it's available as a limited research preview for Enterprise and Team customers, with expedited free access for open-source maintainers.
The announcement itself is worth reading in full — Anthropic was unusually direct about the dual-use risk: the same AI that finds bugs for defenders can find bugs for attackers. Claude Code Security is their answer to that asymmetry.
Why It's Different from Static Analysis (SAST) Tools
Here's the thing that keeps tripping teams up when they first look at this: they think it's just a smarter Snyk or SonarQube. It's not.
Traditional static analysis tools are rule-based. They maintain a database of known vulnerability patterns and match your code against it. That catches the obvious stuff — exposed credentials, outdated crypto libraries, common SQL injection templates. But they're fundamentally blind to context. They can't tell you that your authentication logic is subtly broken because of how three separate modules interact across 40 files.
Claude Code Security doesn't scan for patterns. It reads your code the way a security researcher would — tracing data flows, mapping component interactions, following the path a real attacker would walk. That's a meaningful architectural difference, not marketing language.
What Claude Opus 4.6 Actually Does When Scanning Your Repo
The underlying model is Claude Opus 4.6, released earlier in February. Anthropic's Frontier Red Team used it to find over 500 vulnerabilities in production open-source codebases — bugs that had survived decades of expert review. In one documented case, it identified a crash-inducing flaw in Ghostscript by correlating previously patched issues with similar unaddressed logic paths. In another, it flagged a buffer overflow in OpenSC through analysis of unsafe string manipulation routines.
No task-specific tooling. No custom scaffolding. No specialized prompting. Just the model, reading code.
How It Works: The Full Scan-to-Patch Workflow
This is the part I find most interesting from an engineering workflow perspective. It's not just a scanner that dumps a findings list on you.
Step 1 — Connect Your GitHub Repository
You connect your repo through Claude Code on the web. That's the entry point. Anthropic currently restricts scanning to code your organization owns — you can't point it at third-party or open-source projects you don't have rights to scan (a sensible guardrail given the dual-use risk).
Step 2 — Claude Reasons Through Data Flows & Component Interactions
Once connected, Claude reads across the entire repository — not file by file, but holistically. It maps how data moves between modules, understands business logic, traces authentication flows across service boundaries, and builds a mental model of the attack surface. Think of it as the difference between proofreading individual sentences versus understanding an entire argument.
Step 3 — Multi-Stage Adversarial Verification (False-Positive Filter)
Here's where it gets clever. Every potential finding goes through a self-challenge loop: Claude generates a finding, then actively tries to disprove it. If it can't punch holes in its own reasoning, the finding advances. This adversarial verification is explicitly designed to reduce false positives — one of the biggest practical problems with existing SAST tools, which often bury real issues in noise.
Each validated finding gets both a severity rating (prioritization) and a confidence rating (acknowledging that some issues are genuinely ambiguous from source code alone).
Step 4 — Dashboard Review: Severity Ratings, Proposed Patches, HITL Approval
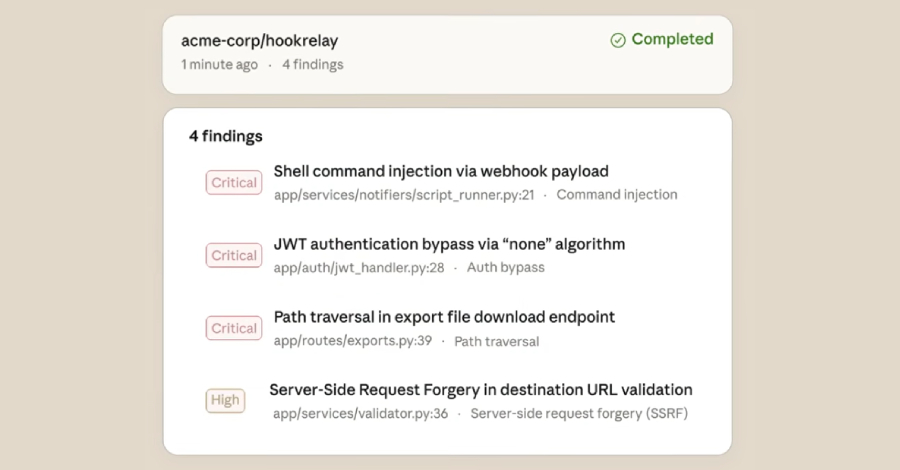
Findings surface in the Claude Code Security dashboard. For each one, you see: the vulnerability description, why it matters, and a suggested patch — written to preserve your code's existing structure and style. Nothing gets applied automatically. Every fix requires explicit human approval. Anthropic is emphatic about this: "Developers always make the call."
That human-in-the-loop requirement isn't a limitation — it's the right design choice for a research preview touching production code.
What Vulnerability Types It Catches (And What It Misses)
Confirmed Catches: Injection Flaws, Auth Bypass, Logic Errors, Memory Corruption
According to Anthropic's official product page, the tool is specifically designed for high-severity vulnerability categories:
| Vulnerability Type | Why Traditional SAST Misses It | Claude's Approach |
|---|---|---|
| Injection flaws (SQL, command, etc.) | Pattern matching misses novel injection vectors | Traces untrusted input through entire call chain |
| Authentication bypasses | Requires understanding auth logic across modules | Maps how auth state propagates across service boundaries |
| Complex logic errors | No pattern to match — emerges from interaction | Reasons about intent vs. actual behavior |
| Memory corruption | Needs understanding of algorithm + data structure interaction | Analyzed LZW/GIF interaction in CGIF heap overflow case |
The CGIF heap buffer overflow example Anthropic published is worth understanding. Identifying it required conceptual understanding of LZW compression and how it interacts with GIF format parsing — precisely the kind of cross-domain reasoning that rule-based tools can't replicate.
Current Blind Spots to Know About
I want to be honest here because I've seen some overclaiming in the coverage this week.
Claude Code Security is a static analysis tool, not a runtime security tool. It reads code. It doesn't execute your application, send requests through your API stack, or test how your auth middleware chains together in a live environment. This is worth being clear about: business logic vulnerabilities that only manifest at runtime — the ones that actually show up in incident reports — are outside its scope.
There's also a documented concern from Anthropic itself: the GitHub Actions integration for CI/CD is not hardened against prompt injection attacks and should only run on trusted PRs. If you're considering automated CI/CD deployment, that's a real constraint to plan around.
Finally: this won't catch vulnerabilities in your AI application layer — prompt injection, data exfiltration through LLM outputs, agentic action hijacking. Those are runtime, behavioral problems. Different tooling category entirely.
Real Performance: 500+ Vulnerabilities Found in Open-Source Codebases
The headline number from Anthropic's internal research: using Claude Opus 4.6, the Frontier Red Team found over 500 vulnerabilities in production open-source codebases — bugs that had gone undetected for decades despite active expert review and automated testing.
Specific documented examples from eSecurity Planet's coverage:
- Ghostscript: crash-inducing flaw identified by correlating previously fixed issues with similar unaddressed logic paths
- OpenSC: buffer overflow flagged via analysis of unsafe string manipulation routines
- CGIF: heap buffer overflow requiring understanding of LZW algorithm behavior with GIF format
Anthropic is currently working through responsible disclosure with maintainers for the broader set of findings. No evidence of active exploitation was reported, but severity justified immediate remediation given downstream software supply chain risk.
The Frontier Red Team is roughly 15 researchers. They've also been entering Claude in Capture-the-Flag competitions and partnering with Pacific Northwest National Laboratory on critical infrastructure defense research — this isn't a demo environment capability, it's been stress-tested against real-world conditions.
Access, Availability & Pricing (Enterprise / Team Preview)
Current availability (as of February 23, 2026):
| Tier | Access | Notes |
|---|---|---|
| Claude Enterprise | ✅ Limited research preview | Apply through Claude Code on web |
| Claude Team | ✅ Limited research preview | Apply through Claude Code on web |
| Open-source maintainers | ✅ Expedited free access | Apply via Anthropic's security contact |
| Individual / Pro users | ❌ Not available | Broader rollout planned for later 2026 |
Pricing for the security feature itself hasn't been disclosed separately — it's positioned as a capability within existing Enterprise/Team plans. Anthropic has said feedback from this preview will shape broader rollout later in 2026.
One practical constraint: you must agree to only scan code your organization owns and holds all necessary rights to. Third-party or licensed code is explicitly out of scope.
Claude Code Security vs CrowdStrike, Snyk & Traditional SAST — An Honest Comparison
The market reaction conflated things that shouldn't be conflated. CrowdStrike does runtime endpoint threat detection. Okta does identity and access management. Neither primarily scans application source code. The actual competitive displacement is more targeted.
| Tool | Category | Strength | Claude Code Security Overlap |
|---|---|---|---|
| Snyk | SAST + dependency scanning | Known CVEs, dependency vulns | Low — Snyk is pattern-based; Claude catches what Snyk misses |
| SonarQube | SAST | Code quality + known vuln patterns | Low-Medium — complementary, not replacement |
| Semgrep | SAST | Custom rule-based scanning | Low — rule-based by design |
| CrowdStrike | Runtime EDR | Endpoint threat detection | None — different layer entirely |
| Veracode | DAST + SAST | Enterprise AppSec platform | Medium — overlaps on SAST component |
The honest framing: Claude Code Security is most directly competitive with the reasoning gap in existing SAST tools — the complex, context-dependent vulnerabilities that pattern matching can't find. It's not trying to replace runtime security, identity tooling, or dependency scanning. Teams that already use Snyk or Semgrep would likely run both, not choose.

Is It Production-Ready? Verdent's Assessment
Here's where I'll give you a straight answer rather than hedging into uselessness.
What's clearly ready: The core scanning capability is real and well-validated. Over 500 findings in production codebases that survived decades of review isn't a demo result. If you're an Enterprise or Team customer and you can get access, running it against a security-sensitive module is a low-risk, high-value experiment.
What's not ready for full deployment: CI/CD automation without guardrails. Anthropic's own documentation says the GitHub Actions integration isn't hardened against prompt injection — that's a meaningful constraint for teams considering automated pipelines on PRs from external contributors. The human-in-the-loop requirement is also genuinely load-bearing right now, not just a legal disclaimer.
The capacity question nobody's asking: Claude can surface more issues. But your org still needs people to validate risk and approve patches. If your security backlog is already overwhelming your team, adding a tool that finds more issues faster doesn't automatically help unless you also increase review capacity.
My actual take: This is one of the more significant capability releases in AppSec in the last few years — not because it replaces anything, but because it genuinely catches a class of vulnerabilities that weren't practically findable at scale before. For Verdent, we're treating it as a complementary layer to our existing static analysis, not a replacement. Run both. Cover more ground.
The broader shift Anthropic is signaling — that a significant share of the world's code will be scanned by AI in the near future — feels accurate. The question for security teams isn't whether to engage with this category, it's how to integrate it without creating new noise or new attack surface in the pipeline itself.
Sources & Disclosure Date
All information sourced from publicly available announcements and technical coverage as of February 23, 2026.
- Anthropic Official Announcement — Claude Code Security — February 20, 2026
- Claude Code Security Product Page — Anthropic
- Claude Code Security Docs — Security — Anthropic
- The Hacker News — Anthropic Launches Claude Code Security — February 20, 2026
- Fortune — Exclusive: Anthropic Rolls Out AI Tool That Can Hunt Software Bugs — February 20, 2026
- CyberScoop — Anthropic Rolls Out Embedded Security Scanning — February 20, 2026
- eSecurity Planet — Claude Opus 4.6 Exposes Hundreds of Open-Source Vulnerabilities
- OWASP — Static Code Analysis
Disclosure: Verdent.ai builds on top of AI models including Claude. This post reflects our independent assessment of publicly available information and does not represent any commercial relationship with Anthropic.
