
Okay, I'll be honest — when I first saw "Hyperagents" trending on Hacker News last week, I assumed it was another breathless AI rebranding exercise. Then I actually read the paper. As someone who spends most of her time evaluating AI coding tools against real production workloads, I can tell you this one is genuinely different — not because you should run it tomorrow, but because of what it signals about where agentic coding architecture is heading. Let me break down exactly what Meta's Hyperagents are, what the benchmark numbers actually mean, and — critically — why you can't use this in your codebase today even if you wanted to.
What Are Meta's Hyperagents?
From Darwin Gödel Machine to DGM-H
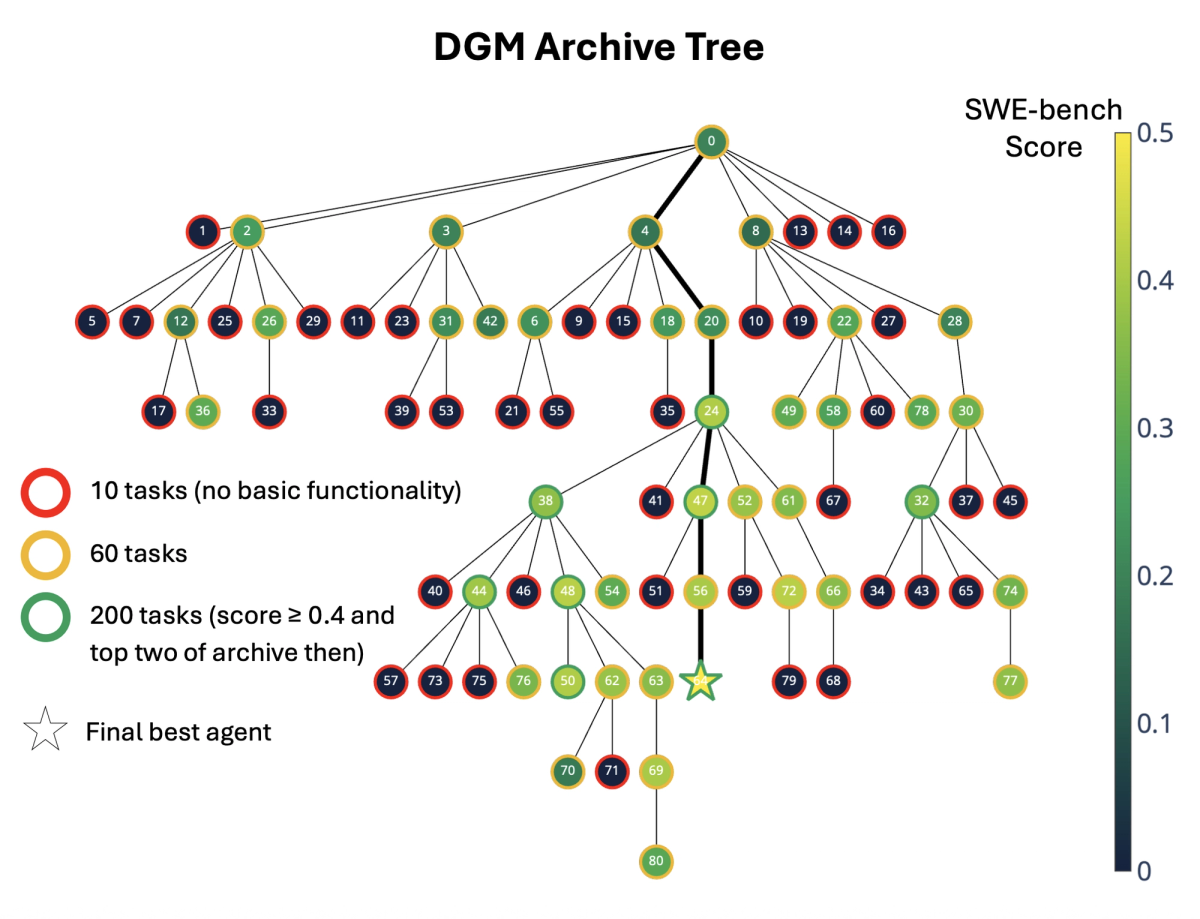
To understand Hyperagents, you need thirty seconds of background on its predecessor. The Darwin Gödel Machine (DGM) — published by researchers at Sakana AI and collaborators in 2025 — proved that an AI agent could iteratively rewrite its own code and measurably improve on coding benchmarks. On SWE-bench, DGM self-improved from 20% to 50% resolution rate. On the。Polyglot multi-language benchmark, it jumped from 14.2% to 30.7%. Genuinely impressive.
But DGM had a hard constraint baked in: it only worked well in coding domains. The reason is almost elegant in its specificity. In coding tasks, the evaluation task and the self-modification task are naturally aligned — getting better at code means getting better at rewriting yourself. Take DGM into paper review or robotics, and that alignment breaks down. The meta-agent (the part that decides how to improve) was fixed, human-written, and off-limits to modification.
DGM-Hyperagents (DGM-H) is an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. That's the core architectural shift: the meta-agent is no longer sacred, hard-coded logic. It's just another function in hyperagent.py — and it can rewrite itself.
The paper was submitted to arXiv on March 19, 2026 and has been accepted by ICLR 2026. The research team includes Jenny Zhang (UBC, first author, interning at Meta), alongside collaborators from Vector Institute, University of Edinburgh, NYU, Canada CIFAR AI Chair, FAIR at Meta, and Meta Superintelligence Labs.
What "Metacognitive Self-Modification" Actually Means in Plain Terms
Here's where I think a lot of the AI media coverage goes wrong: it describes this as "AI that rewrites its own code" and leaves it there. That's technically true but misses what's architecturally new.
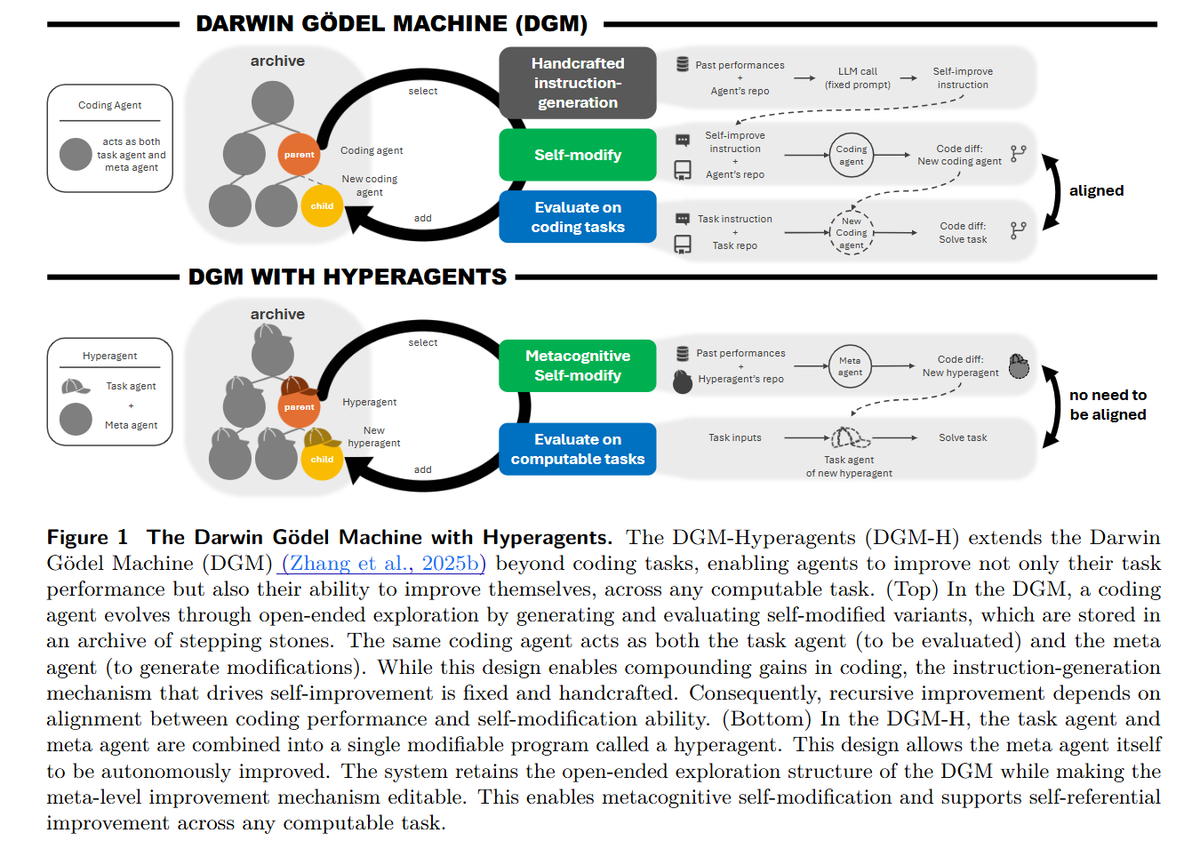
Previous self-improving systems had two layers:
- Layer 1 (Task Agent): Solves the actual problem (write code, review a paper)
- Layer 2 (Meta Agent): Decides how to improve Layer 1
The trick in DGM-H is that Layer 2 is now editable too. The hyperagent doesn't just search for a better solution; it improves the mechanism responsible for generating future improvements. The research team calls this metacognitive self-modification.
Think of it this way: the original DGM trains athletes. DGM-H trains athletes and trains the coaches to become better coaches. Then the coaches rewrite the coaching curriculum. The compounding effect is what makes this architecturally meaningful.
How DGM-H Differs from Standard Multi-Agent Systems
Task Agent + Meta Agent Merged into One Editable Program
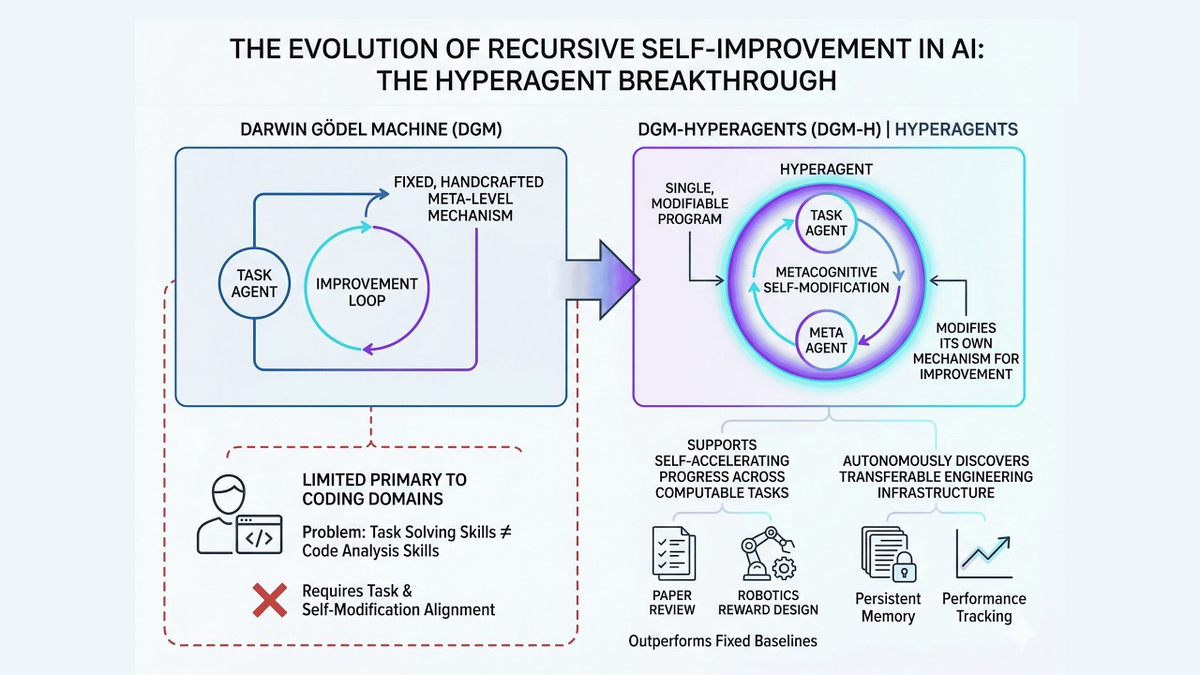
Standard multi-agent coding systems — think the four-agent architectures you see in tools like Verdent, with separate planner, navigator, editor, and executor roles — keep those roles distinct. The agents coordinate, but none of them rewrites another agent's fundamental logic at runtime.
DGM-H collapses this. It integrates the task agent (which solves the target task) and the meta agent (which modifies itself and the task agent) into a single editable program. Because both parts live in the same code, the second component can rewrite itself too.
Here's a simplified illustration of what the self-modification loop looks like at the code level:
# Simplified illustration of DGM-H's modify_self() loop
# (not production code — for conceptual understanding only)
def modify_self(current_agent_code: str, task_performance: dict) -> str:
"""
The meta agent calls the foundation model to propose
improvements to the *entire* agent file, including
this very function. The result is evaluated on benchmark,
kept if it scores above threshold, added to archive.
"""
prompt = f"""
You are modifying a Python agent to improve its performance.
Current code: {current_agent_code}
Recent performance: {task_performance}
Output the complete modified Python file.
"""
new_code = foundation_model_call(prompt)
return new_code # This function itself can be rewritten in new_codeWhen DGM-H ran on the paper review task without being instructed to, it autonomously developed a JSON-based persistent memory structure, started logging past reviews to compare against new papers, and introduced explicit checklists — none of which were in the original scaffold. That's the metacognitive loop in action.
Why This Alignment Only Held in Coding Domains Before DGM-H
This is the part that's genuinely non-obvious. The DGM's self-improvement relied on one implicit assumption: improving at the task also improves the agent's ability to modify itself. In coding, this holds naturally — better code reasoning means better self-modification reasoning. In poetry, math grading, or paper review, it doesn't. Improving at reviewing ML papers doesn't make you better at rewriting Python agent code.
DGM-H removes this dependency entirely by making the meta-level evolvable. The improvement procedure can now adapt to whatever domain it's operating in, developing domain-appropriate meta-strategies rather than relying on the coding-domain heuristics baked into the original DGM.
The Benchmark Results: What the Numbers Actually Show
All results below come from the paper (arXiv:2603.19461) and reflect research/experimental conditions, not production performance. These are not numbers you can expect to replicate by deploying the tool on a work project.
Polyglot Coding: 8.4% → 26.7% (Research Conditions, Not Production)
| Metric | Initial Agent | DGM-H Final | Notes |
|---|---|---|---|
| Polyglot (training split) | 14.00% | 34.00% | pass@1 |
| Polyglot (test set) | 8.40% | 26.70% | pass@1, held-out |
| Paper review accuracy | 0 | 0.710 (CI: 0.590–0.750) | vs. AI-Scientist-v2 baseline of 0.630 |
| Robotics reward design | 0.06 | 0.372 | quadruped locomotion in Genesis simulator |
On the Polyglot coding benchmark, DGM-H jumps from 0.084 to 0.267, putting it on par with the original DGM, even though the system wasn't built specifically for coding. That last clause matters — DGM-H wasn't tuned for coding, yet it matched a system that was.
Cross-Domain Transfer: Paper Review and Robotics Results
The most striking finding isn't the per-domain numbers. It's the transfer experiment. Hyperagents optimized on paper review and robotics transferred to Olympiad-level math grading, achieving an imp@50 score of 0.630, while traditional DGM meta-agents scored 0.0.
The system hadn't seen Olympiad math grading before. It applied meta-strategies it had developed in completely different domains and still generated measurable improvement. Fixed-procedure systems couldn't move at all on the same transfer test.
In robotics, something unexpected happened: DGM-H almost always generates reward functions that get the robot jumping instead of leaving it stuck in the local optimum of just standing upright. The agent discovered complex behavior not specified in the original reward structure.
What the imp@50 Metric Measures and Its Limits
The paper introduces imp@50 (improvement@50) to quantify transfer quality: it measures the performance gain a fixed meta-agent achieves after 50 modification steps in a new domain.
A few important caveats on this metric:
- It measures relative improvement from a starting point, not absolute task performance
- 50 iterations with frontier models is computationally expensive at scale — not a free lunch
- The metric captures trajectory, not ceiling — a high imp@50 could still land at a mediocre absolute score depending on where the agent starts
Treat imp@50 as a signal about meta-learning quality, not as a direct comparison to production coding agent benchmarks like SWE-bench Verified.
What You Cannot Do With It Today
CC BY-NC-SA License — Commercial Use Is Off the Table
The facebookresearch/HyperAgents repository is released under Creative Commons BY-NC-SA 4.0. This is a non-commercial license. You can study it, adapt it, and share adaptations — but commercial use requires a separate agreement with Meta.
For anyone evaluating this for a startup product, internal enterprise tool, or anything customer-facing: you can't without reaching out to Meta's licensing team first. Full stop.
Docker Sandbox + Three API Keys Required
This isn't a pip install situation. Running DGM-H requires:
# Environment setup (from official repo)
sudo dnf install -y python3.12-devel graphviz graphviz-devel cmake ninja-build
python3.12 -m venv venv_nat
source venv_nat/bin/activate
pip install -r requirements.txt
pip install -r requirements_dev.txt
# Build the Docker container
docker build --network=host -t hyperagents .
# Required API keys (all three needed for full functionality)
export OPENAI_API_KEY='...'
export ANTHROPIC_API_KEY='...'
export GOOGLE_API_KEY='...'The GitHub repository currently has approximately 1,830 stars — researcher-level interest, not developer-adoption-level interest. This is a research artifact that requires comfort with Docker environments, Python 3.12, and managing multi-provider API billing simultaneously.
Official Safety Warning: Executes Untrusted Model-Generated Code
This is not marketing boilerplate. From the official repository README:
"This repository involves executing untrusted, model-generated code. We strongly advise users to be aware of the associated safety risks. While it is highly unlikely that such code will perform overtly malicious actions under our current settings and with the models we use, it may still behave destructively due to limitations in model capability or alignment."
The sandbox is Docker-based, which provides a meaningful layer of isolation. But "behave destructively" is the team's own language in their own repo. They sandboxed experiments for a reason. If you're evaluating this for anything involving production data or systems, that warning should be the first thing you read.
Not an IDE Plugin, Not a Drop-In Coding Agent
To be direct: DGM-H is not a VS Code extension. It's not a CLI you install and point at a repo. It's a research framework you run as a Python process inside Docker, watching it iterate over hundreds of self-modification cycles on a benchmark. The workflow is:
- Initialize with a target task and minimal agent scaffold
- Let the system run modification iterations (each iteration = multiple FM API calls)
- Monitor the archive of generated agent variants
- Evaluate results against your benchmark
This is a laboratory instrument, not a developer tool. The gap between "research framework" and "IDE plugin" is about three to five years of engineering work, safety evaluation, and productization.
What This Research Signals for AI Coding Tool Development
Self-Optimizing Agent Loops as an Emerging Architectural Direction
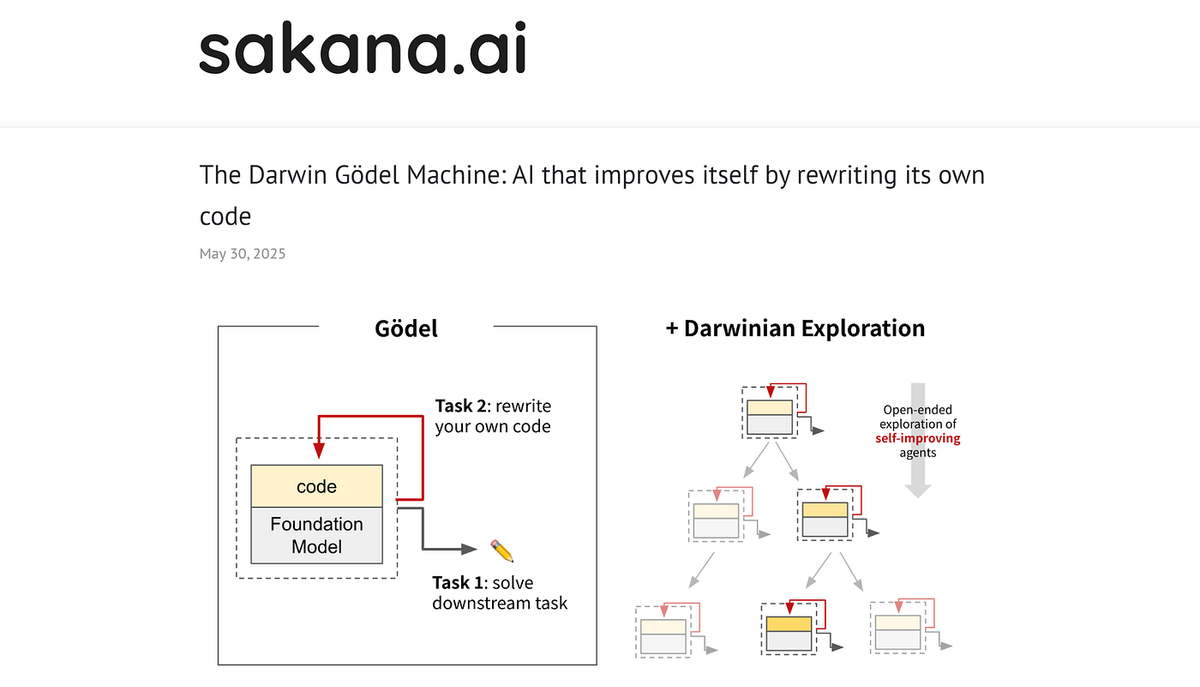
Here's why this matters to developers who aren't researchers: it validates a specific architectural direction that production AI coding tools are already moving toward, even in more constrained forms.
The improvement@k pattern from the Hyperagents paper — generate → evaluate → keep best → iterate — is structurally similar to what verification loops in tools like Verdent already do at the task level. The difference is DGM-H applies that loop to the agent architecture itself, not just to the code it produces.
What this signals for near-term tool development:
- Verification loops will become richer. Code verification agents that run, test, and self-correct are table stakes in 2026. The next generation will likely verify and improve the verification strategy itself.
- Archive-based agent memory is coming. DGM-H's growing archive of stepping-stone agents maps conceptually to the persistent context and skill libraries emerging in production tools.
- Multi-model routing will get smarter. DGM-H uses foundation model calls (Claude, GPT-4o) as the reasoning substrate. The meta-agent learning which model to call for which subtask is a tractable next step for commercial tooling.
Why Code Verification and Isolated Execution Become More Critical as Agents Gain Autonomy
The safety warning in the DGM-H repo isn't just a legal disclaimer. It's pointing at a real engineering constraint: as agents gain more autonomy to modify their own behavior, the blast radius of a bad modification grows.
This is why isolated execution environments — git worktrees, Docker sandboxes, containerized agent workspaces — aren't nice-to-haves in autonomous coding tools. They're architectural prerequisites. All experiments in the Hyperagents research were conducted with safety precautions including sandboxing and human oversight. A research team with full awareness of what the system does still sandboxed every run.
For developers evaluating AI coding tools today: the presence of real isolation mechanisms (not just "we don't send your code anywhere" marketing claims) is a meaningful signal about how seriously a tool takes autonomous agent safety. As agents get more capable, isolation becomes more important, not less.
FAQ
Is this the same as the 2024 "HyperAgent" multi-agent SE system?
No — and this confusion is everywhere. HyperAgent (2024) from FPT Software AI4Code is a multi-agent software engineering system with four specialized roles: Planner, Navigator, Code Editor, and Executor. It focuses on handling diverse SE tasks across programming languages. Meta's Hyperagents (2026) is a self-referential self-improvement framework where the agents rewrite their own improvement logic. Different research groups, different architectures, different goals. The naming overlap is unfortunate.
Can I use Meta's Hyperagents in a production codebase right now?
No. The framework requires Docker, three API keys, Python 3.12, and comfort with running hundreds of model-generated code iterations in a sandboxed environment. There's no IDE integration, no CLI wrapper for existing repos, and the official team explicitly warns the system may behave destructively in unsandboxed conditions. This is a research artifact.
What license does Hyperagents use, and does it allow commercial use?
Creative Commons BY-NC-SA 4.0. Non-commercial. You can study, adapt, and share under the same license. Commercial use requires a separate agreement. Check the LICENSE.md in the repo directly before making any licensing decisions.
What AI models does DGM-H run on?
The architecture is initialized with a frozen foundation model (FM; e.g., Claude, GPT-4o) and minimal task/meta agent scaffolding; only tool invocation (bash, file editor) is provided. In practice, running the full framework requires API access to OpenAI, Anthropic, and Google simultaneously, as different experimental configurations use different providers.
What does this mean for developers evaluating AI coding tools today?
The practical signal is architectural, not immediately actionable. When evaluating tools, look for: (1) genuine isolated execution environments, not just privacy claims; (2) verification loops that run, test, and repair — not just generate; (3) agent memory that persists across tasks, not just within a session. These are the capabilities that the Hyperagents research validates as meaningful for autonomous coding work. Tools that have them built properly today are better positioned as the underlying model capabilities compound.
Want to see how current AI coding tools handle parallel agent execution and isolated environments in real projects? Explore Verdent's multi-agent architecture →
Related Reading
- Best Claude Code Alternatives for Agentic Workflows in 2026
- Claude Code vs Verdent: Multi-Agent Architecture Compared
- Claude Skills vs MCP vs Agents: Key Differences
- What Is Model Context Protocol?
- Claude Code Pricing 2026: Plans, Token Costs, and Real Usage Estimates
Data sources: Zhang et al., "Hyperagents," arXiv:2603.19461 (March 2026). GitHub repo: facebookresearch/HyperAgents. DGM background: Sakana AI DGM blog. ICLR 2026 acceptance confirmed via multiple sources (March 2026).
