
Claude Opus 4.7 launched April 16, 2026 at the same price as 4.6. The coding benchmarks moved significantly. The tokenizer also changed, and that gap between "same price" and "same cost" is the decision most teams need to quantify before migrating. This comparison covers the numbers you need, where they came from, and when upgrading doesn't make sense.
Quick Verdict — Who Should Upgrade and Who Should Wait

Upgrade if:
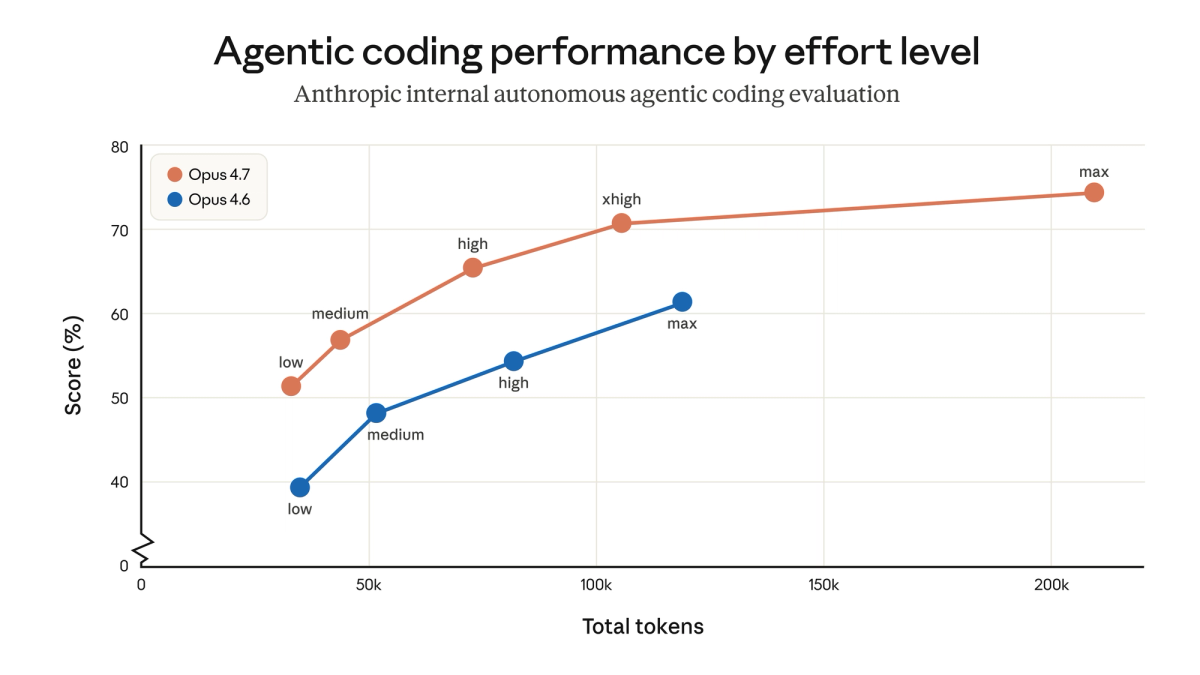
- You run autonomous coding agents on complex, multi-file tasks — SWE-bench Verified jumped 6.8 points and CursorBench 12 points
- Your workflows involve screenshots, diagrams, or UI parsing — vision resolution tripled, XBOW Visual Acuity went from 54.5% to 98.5%
- You orchestrate multi-step agent loops — tool errors dropped to one-third of Opus 4.6 levels (Notion AI data, sourced below), and the new
xhigheffort level gives finer control - You're on Opus 4.6 for terminal/command-line agentic work — Terminal-Bench 2.0 improved from 65.4% to 69.4% (though GPT-5.4 still leads at 75.1%)
Stay on 4.6 if:
- Your prompts were tuned for 4.6's looser instruction interpretation — 4.7 follows instructions more literally, which breaks some prompts that relied on the model inferring unstated intent
- You haven't measured tokenizer impact on your actual traffic — the new tokenizer produces up to 35% more tokens for the same input; for multilingual or structured content this is a real cost increase
- Your primary use case is agentic web search — BrowseComp dropped from 83.7% to 79.3% on 4.7; GPT-5.4 Pro leads at 89.3%
- You have a compliance-approved 4.6 deployment — new cybersecurity safeguards in 4.7 may produce unexpected refusals; validate before switching
Benchmark Comparison Table
All Anthropic-reported scores unless otherwise noted. Opus 4.6 scores from the February 5, 2026 Anthropic release; Opus 4.7 scores from the April 16, 2026 Anthropic release.
| Benchmark | Opus 4.6 | Opus 4.7 | Δ | GPT-5.4 | Notes |
|---|---|---|---|---|---|
| SWE-bench Verified | 80.80% | 87.60% | +6.8pp | — | Anthropic-conducted; memorization screens applied |
| SWE-bench Pro | 53.40% | 64.30% | +10.9pp | 57.70% | Multi-language real-world tasks; Scale AI benchmark |
| CursorBench | 58% | 70% | +12pp | — | Partner eval; source: Cursor CEO (see below) |
| GPQA Diamond | 91.30% | 94.20% | +2.9pp | 94.40% | Effectively at saturation; differences within noise |
| Terminal-Bench 2.0 | 65.40% | 69.40% | +4.0pp | 75.10% | 4.7 improves on 4.6; GPT-5.4 leads overall |
| BrowseComp | 83.70% | 79.30% | −4.4pp | 89.30% | Regression vs 4.6; GPT-5.4 and Gemini 3.1 Pro both lead |
| XBOW Visual Acuity | 54.50% | 98.50% | +44pp | — | Computer-use screenshot benchmark; XBOW partner eval |
| MCP-Atlas | 73.90% | 77.30% | +3.4pp | 68.10% | Scaled tool use; Anthropic-conducted |
| Finance Agent v1.1 | 59.70% | 64.40% | +4.7pp | — | Anthropic-conducted |
On partner data sources: CursorBench, Rakuten-SWE-Bench, and XBOW Visual Acuity figures are partner evaluations cited on Anthropic's official release page at anthropic.com/news/claude-opus-4-7 and anthropic.com/claude/opus. They are not independently replicated Anthropic evaluations — they are partner-run benchmarks on proprietary test sets. Treat them as strong directional signals from production use, not controlled comparisons.
On Terminal-Bench: 4.7 improved 4.0 points over 4.6. The benchmark is not a regression for Opus — the competitive gap is against GPT-5.4, not against the prior version.
The Behavior Differences That Show Up in Production
Self-verification loop — checks its own work before reporting done
Opus 4.7 proactively writes verification steps before declaring a task complete. In agentic coding this means the model writes tests, runs them, and fixes failures internally before surfacing results. Vercel's team observed it "does proofs on systems code before starting work, which is new behavior we haven't seen from earlier Claude models." This reduces the frequency of confidently wrong outputs reaching the orchestrator layer.
Instruction following is stricter — bullet lists treated as hard requirements
Opus 4.6 interpreted instructions loosely and would sometimes infer unstated intent. Opus 4.7 follows instructions precisely. Anthropic's migration guide explicitly flags this: "Opus 4.7 respects effort levels strictly, especially at the low end. At low and medium, the model scopes its work to what was asked rather than going above and beyond."
In practice: prompts with bullet lists that previously worked because the model would generalize from partial instructions may now produce narrower output. Test any prompt that relies on 4.6's generous interpretation before migrating.
Tool errors reduced to one-third
Notion AI's AI Lead Sarah Sachs, quoted in Anthropic's official release: "plus 14% over Opus 4.6 at fewer tokens and a third of the tool errors." This is a single partner's internal benchmark on their specific orchestration patterns, not a controlled cross-model evaluation. That said, several other partners reported similar reliability improvements — Factory Droids noted "fewer tool errors and more reliable follow-through on validation steps," and Genspark reported meaningful improvement in "loop resistance" (the model rate of running indefinitely on a query).
3× more production tasks resolved
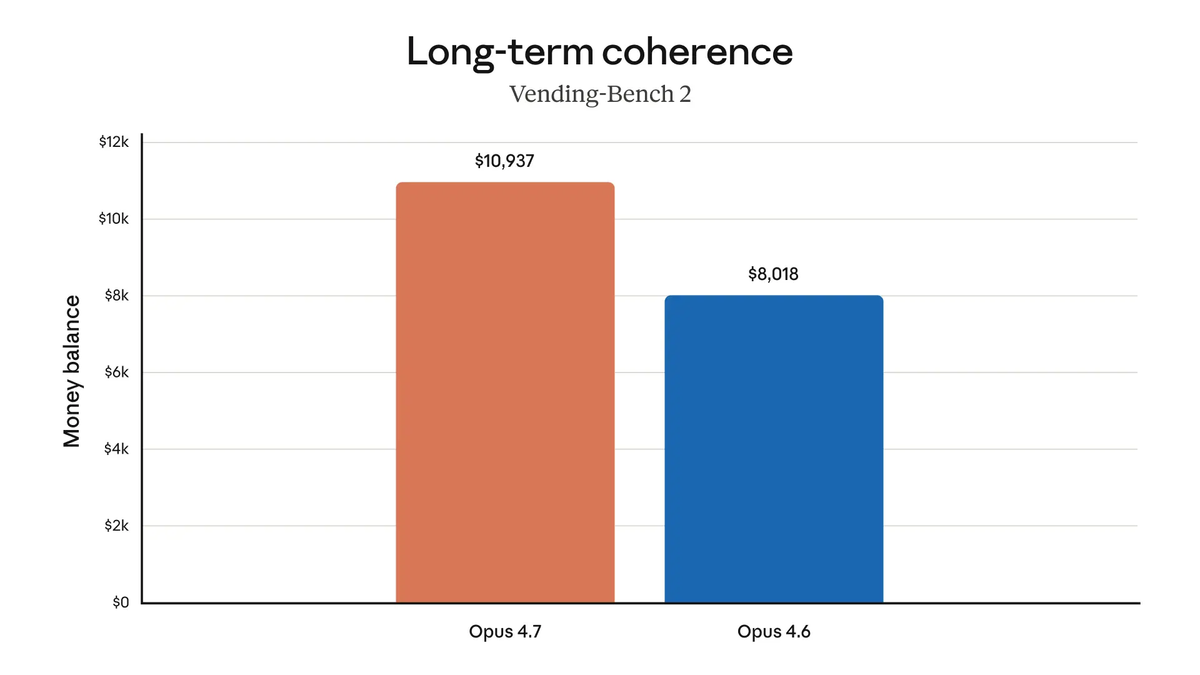
Rakuten, quoted in Anthropic's official release: "On Rakuten-SWE-Bench, Claude Opus 4.7 resolves 3x more production tasks than Opus 4.6, with double-digit gains in Code Quality and Test Quality." This is Rakuten's proprietary benchmark on their internal codebase — not SWE-bench standard. The magnitude is striking enough to be worth noting, but the right comparison is your own codebase, not Rakuten's.
New Capabilities Absent in 4.6
xhigh effort level — finer reasoning/latency tradeoff
Effort levels on 4.6: low, medium, high, max. Opus 4.7 adds xhigh between high and max. Claude Code defaults to xhigh across all plans. Hex's CTO observed that "low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6" — which means if you were using high on 4.6 for a task, xhigh on 4.7 is the appropriate comparable setting.
# Claude Code
/effort xhigh
# API
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=64000,
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "..."}]
)Task budgets (public beta) — cap token spend on long-running agentic jobs
A task budget gives the model a token target for an entire agentic loop — thinking, tool calls, tool results, and final output combined. The model sees a running count and wraps gracefully as the budget approaches. Not available in 4.6. Use the task-budgets-2026-03-13 beta header:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
betas=["task-budgets-2026-03-13"],
output_config={
"effort": "high",
"task_budget": {"type": "token_target", "token_target": 50000}
},
messages=[{"role": "user", "content": "..."}]
)Task budgets are advisory, not hard limits — the model is aware of the target but can exceed token_target. The minimum is 20K tokens. For open-ended quality-first tasks, Anthropic recommends omitting the task budget.
/ultrareview in Claude Code — multi-pass code review session
New command in Claude Code, not available in 4.6. Dedicated session for architecture, security, performance, and maintainability review in a single structured pass. Anthropic is offering three free ultrareviews at launch for Pro and Max users.
Auto Mode for Max users
Previously restricted to Enterprise plans in 4.6 configurations. Now available to Max users: the agent automatically adjusts its behavior to avoid interrupting long tasks, handling minor ambiguities independently rather than pausing for confirmation.
The Cost Reality
Sticker price unchanged: $5/$25 per million tokens
Pricing is identical on Opus 4.7 and 4.6 across the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Batch API discount (50%) and prompt caching (up to 90%) also unchanged.
Tokenizer change: same input → up to 1.35× more tokens
Anthropic's migration guide: "This new tokenizer may use roughly 1x to 1.35x as many tokens when processing text compared to previous models (up to ~35% more, varying by content)."
The range is not uniform across content types:
| Content type | Approximate multiplier | Practical implication |
|---|---|---|
| English prose | 1.00–1.05× | Negligible impact for chat workloads |
| Clean code (English identifiers) | 1.05–1.10× | Minor cost increase on typical API codebases |
| Technical/mixed content | 1.10–1.20× | Config files, logs, mixed English/code |
| Multilingual text (CJK, Arabic, Cyrillic) | 1.20–1.35× | Meaningful increase for non-English products |
| Structured data (JSON, XML) | 1.10–1.25× | Varies by schema verbosity and nesting depth |
*Note: These ranges are inferred from Anthropic's stated 1.0–1.35× overall range and content-type behavior patterns. The actual multiplier for your specific content requires direct measurement using /v1/messages/count_tokens.*
Worked example: 1,000 coding tasks/month
Assumptions:
- Average input per task: 8,000 tokens (system prompt 2K + code context 4K + user message 2K)
- Average output per task: 3,000 tokens (code changes + explanation)
- Content type: English code + technical context → estimated 1.10× tokenizer multiplier on input
Opus 4.6 monthly cost:
- Input: 1,000 × 8,000 = 8,000,000 tokens → 8M × $5/M = $40.00
- Output: 1,000 × 3,000 = 3,000,000 tokens → 3M × $25/M = $75.00
- Total: $115.00/month
Opus 4.7 monthly cost (same task volume):
- Input: 8,000,000 × 1.10 = 8,800,000 tokens → 8.8M × $5/M = $44.00
- Output: 3,000,000 tokens (output tokenizer impact is harder to isolate; assume similar) → $75.00
- Total: $119.00/month
- Increase: $4.00 (+3.5%)
For multilingual content at the 1.35× ceiling:
- Input: 8,000,000 × 1.35 = 10,800,000 tokens → 10.8M × $5/M = $54.00
- Total: $129.00/month vs $115.00 (+$14.00, +12.2%)
The real cost driver for most teams is not the tokenizer — it's xhigh** effort generating more thinking tokens on complex tasks.** If you were running at max on 4.6 and switch to xhigh on 4.7, output tokens per task may increase. Measure on representative traffic before committing at volume.
Where caching offsets the inflation
Stable system prompts and tool definitions cached via prompt caching benefit from up to 90% cost reduction regardless of tokenizer changes. If your system prompt is 4,000 tokens on 4.6 and 4,400 tokens on 4.7 (10% tokenizer inflation), the cache hit cost is still 90% lower than the uncached rate. For architectures where the system prompt is static across most requests, caching largely neutralizes the tokenizer impact on input costs.
Migration Risks
Prompts written for loose 4.6 interpretation may produce different output
Specific patterns to audit before migrating:
- Bullet lists used as guidance rather than strict requirements — 4.7 treats them as hard specifications
- Prompts that worked by providing partial constraints and relying on the model to fill gaps
- Tool use prompts that expected the model to call tools proactively — 4.7 "uses tools less often than Opus 4.6 and uses reasoning more" at default effort levels; raise to
highorxhighif tool call frequency drops - Prefill patterns: assistant message prefilling returned a 400 error starting with Opus 4.6 and continues on 4.7 — confirm this was already handled in your 4.6 migration
Token budget re-measurement required on real traffic
/v1/messages/count_tokens returns different values for 4.7 than for 4.6 on the same input. Any cost estimation, rate limit planning, or token-based routing in your infrastructure needs to be re-calibrated against actual 4.7 traffic. Anthropic's recommendation: run a representative sample of production traffic through 4.7 at your target effort level and compare input+output token totals directly.
Decision Framework: When to Split Traffic
For teams unable to commit to a full migration, routing a subset of traffic to 4.7 makes sense when:
| Condition | Routing recommendation |
|---|---|
| Autonomous coding agents (new feature work) | Route 100% to 4.7; gains are consistent across partner evals |
| Computer use / screenshot-heavy workflows | Route 100% to 4.7; vision improvement is a hard capability jump |
| Agentic web research (BrowseComp-heavy) | Keep on 4.6 or test GPT-5.4; 4.7 regressed 4.4 points |
| Terminal / shell command execution | A/B test; 4.7 leads 4.6 by 4pp but trails GPT-5.4 by 5.7pp |
| Multilingual content (CJK, Arabic) | A/B test with cost monitoring; tokenizer impact is highest here |
| Production prompts with tight formatting | Test a 10% subset first; instruction strictness change affects these most |
| Batch processing (non-time-sensitive) | Run full A/B on Batch API at 50% discount to measure quality delta before committing |
FAQ
Does 4.7 share rate limits with 4.6?
Rate limits are model-specific in Anthropic's API. Opus 4.6 and 4.7 have separate rate limit allocations. Check your current tier limits at platform.claude.com if you're near capacity — migrating to 4.7 does not inherit 4.6's rate limit headroom.
Is the tokenizer change larger for code or natural language?
Based on Anthropic's 1.0–1.35× range and content-type patterns, English code with English identifiers sits at the lower end (approximately 1.05–1.10×). English prose is similar. Multilingual text and structured data (JSON, XML) trend toward the upper end. Anthropic's official recommendation is to measure directly: /v1/messages/count_tokens on your actual inputs is the only reliable number.
Should I test 4.7 on a subset before full migration?
Yes, particularly if any of these apply: you have prompts tuned for 4.6's loose interpretation, you process multilingual content at volume, you rely on a specific tool call frequency pattern, or your workflows do significant agentic web research where BrowseComp-type tasks matter. The model ID swap is trivial; the prompt and cost impact audit is where the real migration work sits. Anthropic's migration guide at platform.claude.com/docs/en/about-claude/models/migration-guide covers the specific breaking changes and recommended validation steps.
Related Reading
- Claude Opus 4.7: What Changed for Coding Agents (April 2026) — The standalone feature breakdown, with the full benchmark table and API reference.
- Claude Managed Agents Pricing: What You Actually Pay — How session-hour billing and the 4.7 tokenizer change interact in Managed Agents workflows.
- Superpowers vs Vibe Coding: Structured Agents vs Freeform Prompts — Opus 4.7's stricter instruction following changes the calculus for which agent workflow structure works best.
- GLM-5V-Turbo in AI Coding Agent Workflows — For teams weighing Opus 4.7's vision upgrade against purpose-built vision-to-code alternatives.
- What Is Claude Mythos Preview? — The model above Opus 4.7: what it benchmarks at, who has access, and why it's restricted.
