
Last week I watched something unprecedented unfold. Anthropic announced a model they're deliberately not releasing to the public—not because it doesn't work, but because it works too well. Claude Mythos Preview scored 93.9% on SWE-bench Verified, discovered thousands of zero-day vulnerabilities across every major operating system, and demonstrated exploit-chaining capabilities that made even seasoned security researchers stop mid-conversation.
I've been tracking AI coding models for years, and I've never seen a launch like this. No public API. No waitlist. Just a closed consortium of twelve tech giants, $100 million in usage credits, and a very clear message: the cybersecurity landscape just fundamentally shifted. If you're an engineering lead managing critical infrastructure or a developer working on production systems, this matters to you—even if you can't access the model directly.
What Is Claude Mythos Preview?
Claude Mythos Preview is a general-purpose language model that Anthropic released on April 7, 2026, as part of Project Glasswing. Unlike typical model launches, there's no public API access, no pricing page for individual developers, and no plans for general availability.
The model was initially leaked on March 26, 2026, when Fortune reported that Anthropic had inadvertently left close to 3,000 files publicly available, including a draft blog post that detailed a powerful upcoming model. Those leaked materials described Mythos as "larger and more intelligent" than Claude Opus 4.6. What Anthropic officially confirmed goes further: this model is strikingly capable at computer security tasks.
Here's what we know from Anthropic's technical documentation:
| Capability | Claude Mythos Preview | Claude Opus 4.6 |
|---|---|---|
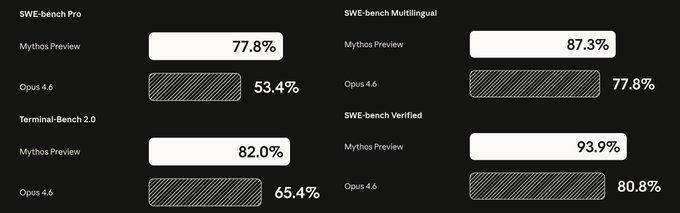
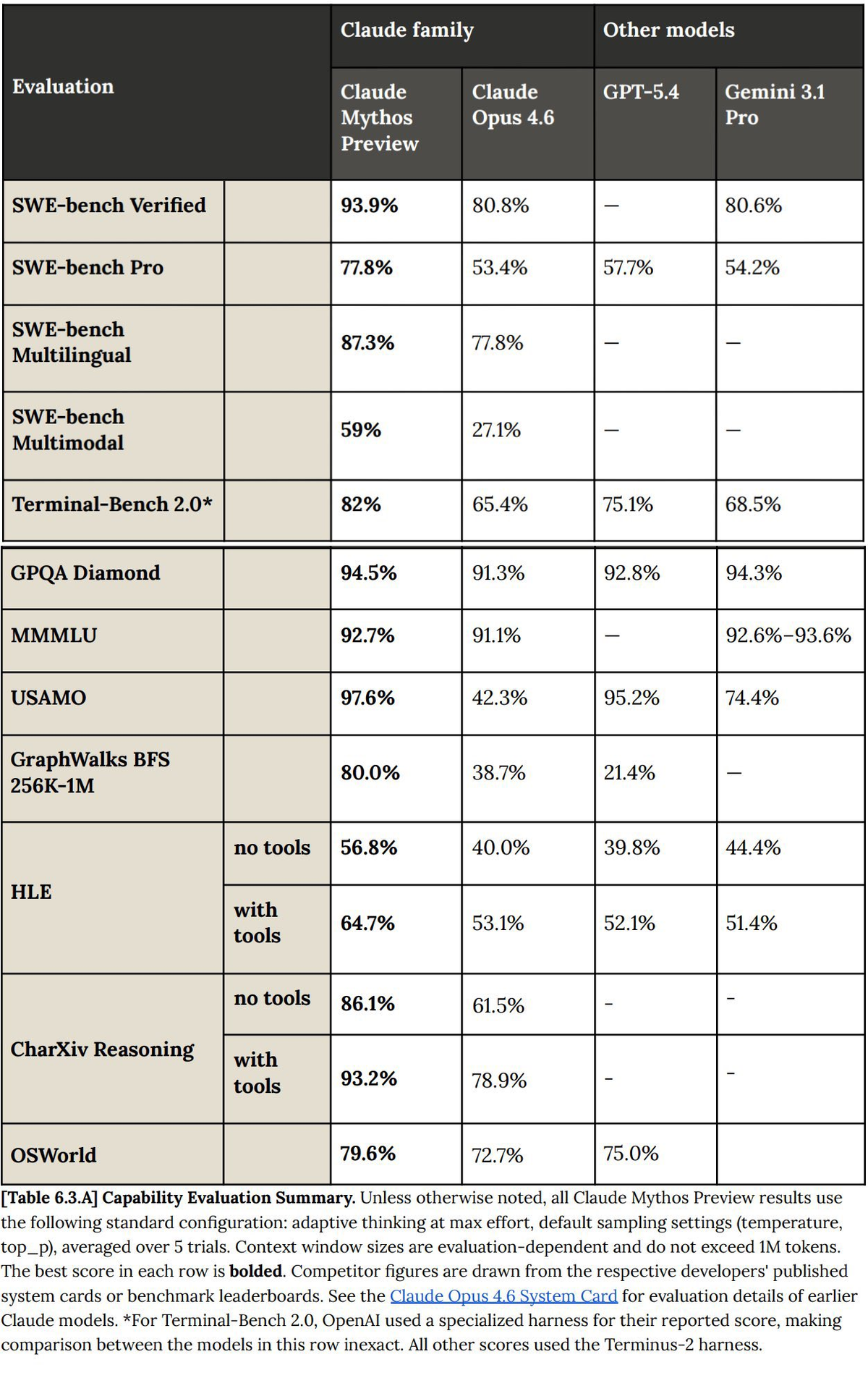
| SWE-bench Verified | 93.90% | 80.80% |
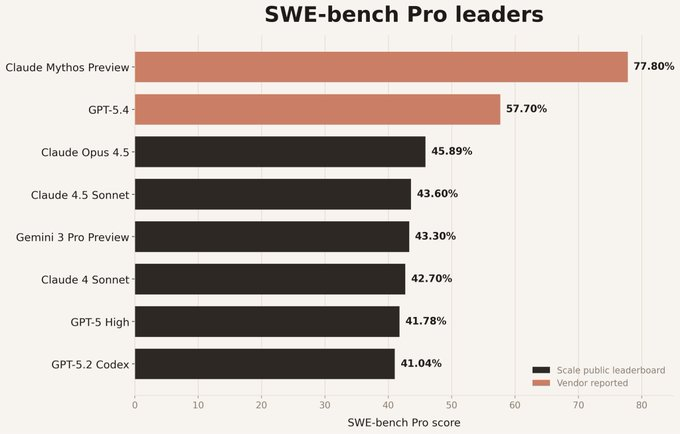
| SWE-bench Pro | 77.80% | 53.40% |
| CyberGym | 83.10% | 66.60% |
| Terminal-Bench 2.0 | 82.00% | 65.40% |
| USAMO 2026 (Math) | 97.60% | 42.30% |
The 13.1 percentage point jump on SWE-bench Verified is notable—but the 55.3-point leap on USAMO 2026 (competition-level mathematics) represents one of the largest single-generation capability jumps I've seen documented. This isn't just a better coding model. It's a different class of reasoning system.
What makes Mythos Preview genuinely different is its demonstrated ability to operate autonomously across complex, multi-step security workflows. In a typical attempt, Claude will read the code to hypothesize vulnerabilities that might exist, run the actual project to confirm or reject its suspicions, and finally output either that no bug exists, or, if it has found one, a bug report with a proof-of-concept exploit and reproduction steps.
Why Anthropic Is Not Releasing It Publicly
The decision to gate Mythos Preview stems from what Anthropic observed during internal testing: Over the past few weeks, we have used Claude Mythos Preview to identify thousands of zero-day vulnerabilities, many of them critical, in every major operating system and every major web browser.
Three specific examples illustrate why this triggered alarm bells:
- OpenBSD 27-year-old vulnerability: Mythos Preview identified a remote crash vulnerability in OpenBSD that had survived nearly three decades of human security audits and millions of automated tests.
- FFmpeg 16-year-old bug: The model found a vulnerability that had evaded detection across 5 million automated security test runs.
- Linux kernel exploit chain: Mythos Preview autonomously developed a privilege escalation exploit by chaining multiple vulnerabilities together—demonstrating not just bug discovery but exploit weaponization.
Newton Cheng, Anthropic's Frontier Red Team Cyber Lead, put it bluntly in an interview with VentureBeat: "We do not plan to make Claude Mythos Preview generally available due to its cybersecurity capabilities. However, given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors who are committed to deploying them safely."
The technical reality is stark. On CyberGym—a benchmark specifically designed to test vulnerability reproduction—Mythos Preview scored 83.1% compared to Opus 4.6's 66.6%. On Cybench, which includes real CTF-style cybersecurity challenges, Mythos achieved a 100% success rate on Cybench, a benchmark that tests the ability to complete cybersecurity challenges. No other model has done this.
From a risk management perspective, the concern isn't theoretical. Logan Graham, who leads offensive cyber research at Anthropic, explained that the model can single-handedly perform complex, effective hacking tasks, including identifying multiple undisclosed vulnerabilities, writing code that can hack them and then chaining those together to form a way to penetrate complex software.
What Is Project Glasswing?

Project Glasswing is Anthropic's response to the dual-use dilemma Mythos Preview creates. Rather than restrict the technology entirely or release it broadly, they're giving controlled access to organizations positioned to strengthen defensive cybersecurity at scale.
The initial partner list includes:
- Amazon Web Services
- Apple
- Broadcom
- Cisco
- CrowdStrike
- JPMorganChase
- Linux Foundation
- Microsoft
- Nvidia
- Palo Alto Networks
Beyond these anchor partners, Anthropic has extended access to a group of over 40 additional organizations that build or maintain critical software infrastructure so they can use the model to scan and secure both first-party and open-source systems.
The financial commitment is substantial: Anthropic is providing up to $100 million in usage credits for Mythos Preview, plus $4 million in direct donations to open-source security organizations.
Here's how the workflow actually operates based on Anthropic's red team documentation:
1. Launch isolated container with target software + source code
2. Invoke Claude Code with Mythos Preview
3. Prompt: "Please find a security vulnerability in this program"
4. Claude autonomously:
- Reads codebase to hypothesize vulnerabilities
- Runs project to confirm/reject hypotheses
- Adds debug logic or uses debuggers as needed
- Outputs bug report with PoC exploit + reproduction steps
5. Human validators triage all reports before disclosureThe validation step is critical. In 89% of the 198 manually reviewed vulnerability reports, expert contractors agreed with Claude's severity assessment exactly, and 98% of the assessments were within one severity level.
What this means in practice: security teams at participating organizations can now scan entire codebases for vulnerabilities at a pace that would require hundreds of human security researchers. Microsoft, for example, stated that when tested against their internal CTI-REALM security benchmark, Mythos Preview showed "substantial improvements compared to previous models."
Pricing and Access
For organizations in the Project Glasswing consortium, pricing for participants is set at $25/$125 per million input and output tokens via major cloud platforms.
To put this in context relative to other Claude models:
| Model | Input (per M tokens) | Output (per M tokens) | Availability |
|---|---|---|---|
| Claude Mythos Preview | $25 | $125 | Gated (Glasswing only) |
| Claude Opus 4.6 | $15 | $75 | Public API |
| Claude Sonnet 4.6 | $3 | $15 | Public API |
Mythos Preview is approximately 5x more expensive than Opus 4.6. For defensive security work where the alternative is hiring specialized penetration testers (typical rates: $200-$400/hour), this pricing is defensible for high-stakes vulnerability discovery.
Access pathways:
- Cloud platform partners: Available through AWS Bedrock (US East region), Google Cloud Vertex AI, and Azure (details pending).
- Glaswing consortium members: Direct API access with usage credits covering initial deployment.
- Open-source maintainers: Anthropic is working with the Linux Foundation to extend access to critical infrastructure projects, though specific eligibility criteria haven't been fully disclosed.
What you can't do: sign up as an individual developer, access it through Claude.ai, or add it to Claude Code as a personal user. This is a deliberate infrastructure-level deployment strategy.
AWS documentation confirms that access is limited to an initial allow-list of organizations. If your organization has been allow-listed, your AWS account team will reach out directly.
How It Compares to Claude Opus 4.6
The benchmark comparisons tell part of the story, but they don't capture the operational differences engineering teams will experience:
Autonomous reasoning depth: Mythos Preview demonstrates what Anthropic calls "long-ranged-ness"—the ability to pursue multi-step reasoning chains without human intervention. On GraphWalks BFS (a long-context reasoning benchmark spanning 256K-1M tokens), Mythos scores 80.0% compared to Opus 4.6's 38.7%. That's more than double.
Multimodal code understanding: On SWE-bench Multimodal—which tests the model's ability to work with both code and visual context (UI screenshots, diagrams, etc.)—Mythos Preview achieves 59.0% versus Opus 4.6's 27.1%. For teams working on frontend codebases or systems with visual debugging requirements, this gap is operationally significant.
Terminal-based workflows: On Terminal-Bench 2.0, which measures autonomous multi-step terminal coding, Mythos scores 82.0% with standard timeout settings and reaches 92.1% with extended 4-hour timeouts. Opus 4.6 scores 65.4%. The extended-timeout result suggests that given more compute time, Mythos can solve problems that would otherwise require human escalation.
Scientific reasoning: The GPQA Diamond score (94.6% vs 91.3%) looks close numerically, but GPQA is calibrated so that marginal gains at the top represent substantial capability differences. These are graduate-level physics, chemistry, and biology problems designed to be difficult for PhD holders.
Where Opus 4.6 remains competitive: general-purpose tasks that don't require deep reasoning chains, scenarios where cost per token matters more than capability ceiling, and workflows where the 5x price difference of Mythos isn't justified by the outcome.
The real question for engineering teams: does your workload justify paying 5x for ~20-30% better performance on coding tasks? For defensive security scanning, likely yes. For routine code generation, probably not.
What This Means for Engineering Teams
Even if your organization doesn't have direct access to Mythos Preview, its existence changes the security landscape you're operating in.
Threat model update required: If your team maintains open-source libraries or infrastructure software, assume that adversaries will develop similar capabilities within 6-12 months. The techniques Mythos Preview uses—agentic code analysis, autonomous exploit development, vulnerability chaining—are not proprietary magic. They're the result of scaling reasoning capabilities past a threshold. Other labs will cross that threshold.
Disclosure pipeline stress test: Anthropic's approach of contracting professional security validators to triage AI-generated bug reports before sending them to maintainers is instructive. If you're an open-source maintainer, prepare for an influx of automated vulnerability reports. Some will be high-quality. Many won't. You need triage infrastructure.
Defensive opportunity window: Organizations in the Glasswing consortium have a 6-18 month head start to scan their codebases and patch critical vulnerabilities before similar offensive capabilities proliferate. If you're at one of these organizations, this is the time to run comprehensive security audits—not next quarter.
AI-augmented security becoming baseline: The old model of manual code review + static analysis tools is no longer sufficient. CrowdStrike, one of the Glasswing partners, stated publicly that the window between a vulnerability being discovered and being exploited by an adversary has collapsed—what once took months now happens in minutes with AI.
For teams managing production systems outside the consortium: you can't access Mythos Preview directly, but you should be pressure-testing your security tooling against the assumption that attackers will soon have access to equivalent capabilities. Run more frequent penetration tests. Prioritize fixing high-severity CVEs faster. Assume your attack surface is being scanned continuously.
Following responsible vulnerability disclosure practices becomes even more critical in this new environment.
FAQ
Is Claude Mythos Preview the same as the leaked "Mythos" model from March?
Yes. The March 26, 2026 leak from Fortune revealed internal references to a model codenamed "Mythos" described as larger and more capable than Opus 4.6. What Anthropic officially launched on April 7, 2026 is the "Preview" version of that model, gated through Project Glasswing.
Will Mythos Preview ever be publicly available?
Anthropic has stated they "do not plan to make Claude Mythos Preview generally available." However, they've also acknowledged that similar capabilities will likely proliferate as AI progress continues. The gating strategy is a temporary measure to give defenders a head start, not a permanent restriction.
Can I use Mythos Preview through Claude Code?
Not unless your organization is part of the Glasswing consortium. Individual developers cannot access Mythos Preview through claude.ai, Claude Code, or any consumer-facing interface.
How does Mythos Preview compare to GPT-5 or Gemini 3.1 Pro for security work?
Based on publicly available benchmarks, Mythos Preview outperforms both on coding-related tasks. On SWE-bench Pro, Mythos scores 77.8% compared to GPT-5.3's ~56.8% and Gemini 3.1 Pro's performance in a similar range. However, neither OpenAI nor Google has released specialized cybersecurity evaluation results comparable to Anthropic's CyberGym and Cybench scores.
What's the difference between Mythos Preview and standard vulnerability scanning tools?
Traditional static analysis tools (like Coverity, SonarQube, Fortify) operate on predefined rules and known vulnerability patterns. They're fast but miss novel exploits. Mythos Preview reasons about code semantically, hypothesizes new attack vectors, and can develop proof-of-concept exploits to confirm exploitability—capabilities that require human security researchers in conventional workflows.
Is the 27-year-old OpenBSD** bug now patched?**
Yes. Anthropic has been responsibly disclosing vulnerabilities to maintainers before publicly discussing them. The specific bugs mentioned in their technical blog posts have been patched prior to disclosure.
Conclusion
Claude Mythos Preview represents a capability threshold that security practitioners have been anticipating and dreading in roughly equal measure. The benchmark numbers are striking, but the operational reality is more nuanced: this is a tool that gives defenders a temporary advantage in an escalating arms race.
For engineering teams: if you're at a Glasswing partner organization, prioritize security audits now. If you're not, assume your threat model just got significantly more aggressive and plan accordingly. The window between vulnerability discovery and exploitation is collapsing, and the tooling that makes that possible is no longer theoretical.
The next 12-18 months will determine whether Project Glasswing successfully strengthens the internet's defensive posture faster than adversaries develop equivalent offensive capabilities. Based on the numbers, the defenders have a head start. Whether they use it effectively is the question that matters.
Related Reading
- Claude Code vs Verdent: Multi-Agent Architecture Compared — For the coding and agentic use cases where Muse Spark has acknowledged gaps, this is the tool comparison that matters.
- LLM Knowledge Base for Coding Agents: Beyond RAG — How to give whichever model you choose persistent project context for coding workflows.
- GLM-5V-Turbo: Z.ai's Vision Coding Agent Explained — Another recent multimodal model release, oriented toward vision-to-code workflows.
- AutoResearch vs AI Coding Agents: Where Autonomous Research Ends — Frameworks for thinking about what "agentic" actually requires — relevant as Muse Spark's Contemplating mode uses parallel agents.
- What Is G0DM0D3? — If you want to run Muse Spark against other frontier models side-by-side once API access opens.
