
Claude Opus 4.7 went generally available on April 16, 2026. The headline is real: SWE-bench Verified jumped from 80.8% to 87.6%, CursorBench climbed from 58% to 70%, and the model now processes images at over 3× the resolution of Opus 4.6. The price didn't move. The tokenizer did — and that's the part that affects your actual bill.
This is what changed, what didn't, and where the model genuinely falls short.
What Is Claude Opus 4.7?

Claude Opus 4.7 is Anthropic's most capable generally available model as of April 16, 2026. It's a direct upgrade over Opus 4.6 continuing Anthropic's roughly two-month release cadence. The official Anthropic announcement describes it as "a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks."
API identifier: claude-opus-4-7
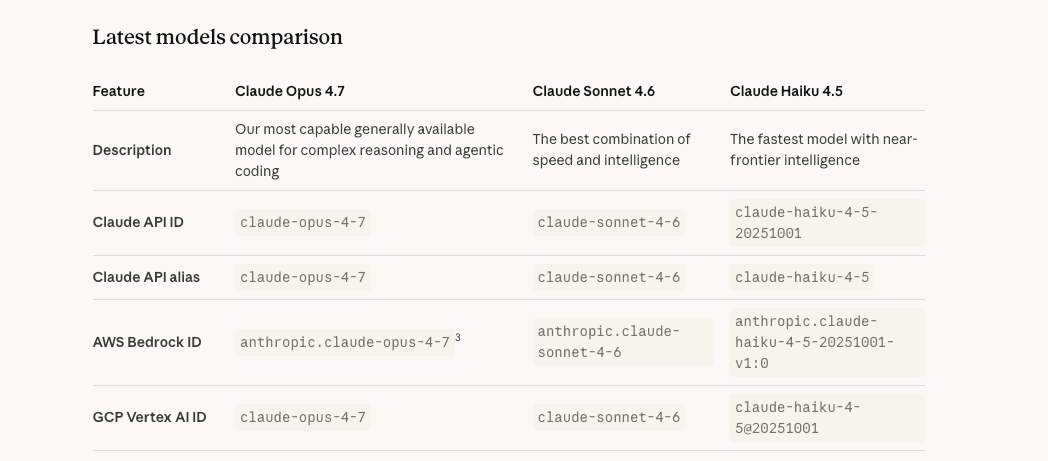
Available via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Drop-in model ID switch from claude-opus-4-6 — though Anthropic's migration guide flags two breaking changes worth checking before you flip the switch in production (more below).
Where it sits: most capable GA model, below Mythos Preview
Anthropic is explicit about this: Opus 4.7 is "less broadly capable than our most powerful model, Claude Mythos Preview." Mythos Preview, announced April 7 under Project Glasswing, remains restricted to a limited set of enterprise platform partners and is not generally available. If you're reading this, Opus 4.7 is the ceiling you can actually deploy.
The Four Changes That Matter for Coding Agents
Coding benchmarks — SWE-bench Verified 87.6%, CursorBench 70%
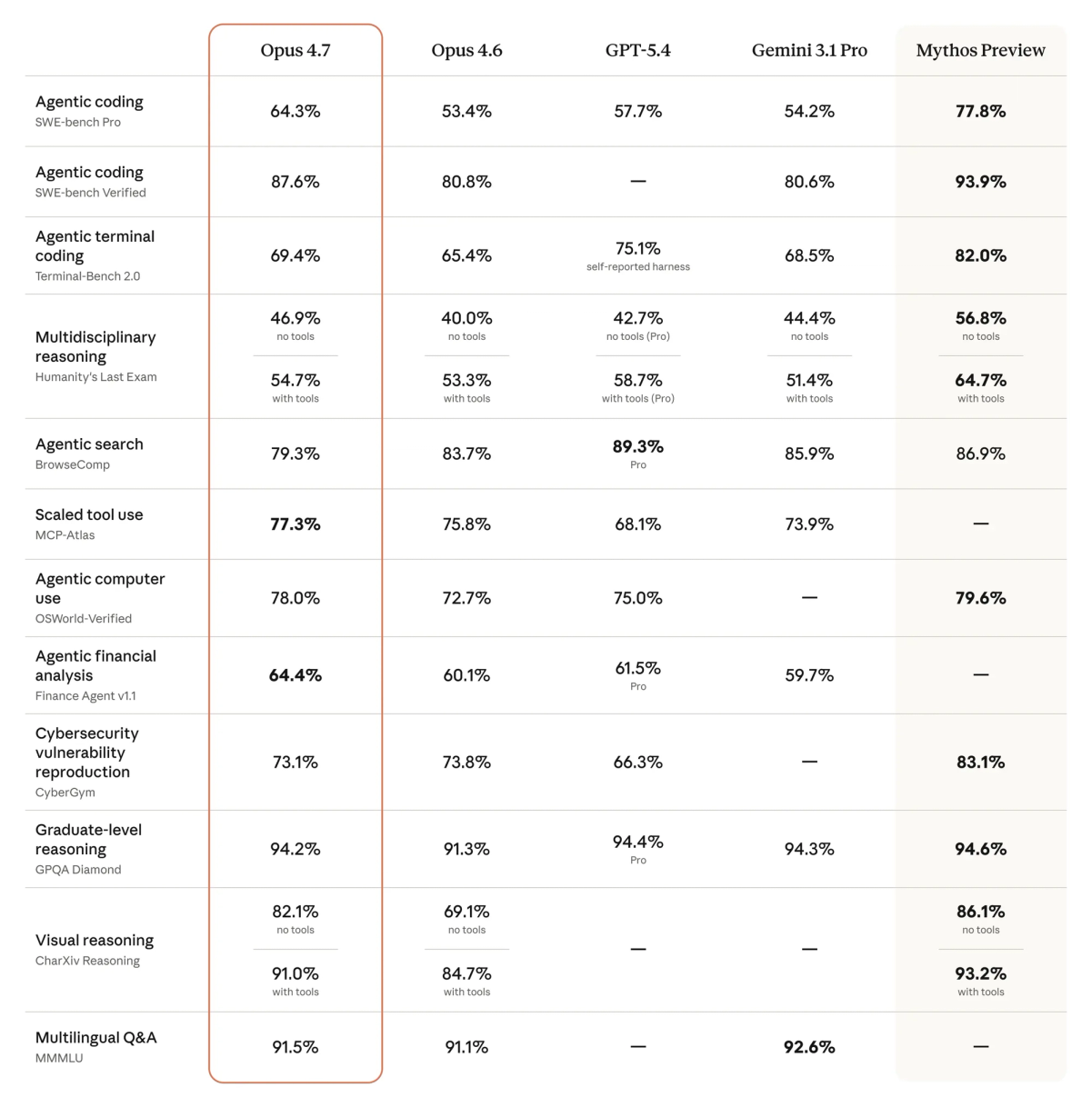
Anthropic's April 16 release reports the following benchmark shifts — all Anthropic-conducted unless otherwise noted:
| Benchmark | Opus 4.6 | Opus 4.7 | GPT-5.4 | Notes |
|---|---|---|---|---|
| SWE-bench Verified | 80.80% | 87.60% | — | Anthropic-conducted; memorization screens applied |
| SWE-bench Pro | 53.50% | 64.30% | 57.70% | Multi-language real-world tasks |
| CursorBench | 58% | 70% | — | Source: Cursor CEO Michael Truell (partner eval) |
| Terminal-Bench 2.0 | — | 69.40% | 75.10% | GPT-5.4 leads; Terminus-2 harness, thinking disabled |
| BrowseComp | 83.70% | 79.30% | 89.30% | Regression vs Opus 4.6 |
| XBOW Visual Acuity | 54.50% | 98.50% | — | Computer use / screenshot tasks |
| GPQA Diamond | 91.30% | 94.20% | 94.40% | Effectively tied at frontier |
The coding gains are validated across partner benchmarks, not just Anthropic's own evals. Cursor's CEO reported directly: 70% on CursorBench vs 58% for Opus 4.6. Rakuten reported 3× more production tasks resolved. CodeRabbit reported recall improved over 10% on complex PRs with stable precision. These are real-workload signals, not synthetic benchmarks.
On SWE-bench, Anthropic notes memorization screens were applied — the margin of improvement holds after excluding flagged problems.
Self-verification behavior — model checks its own work before reporting
Opus 4.7 proactively verifies outputs before declaring a task complete. In agentic coding contexts, this means the model writes tests, runs them, and fixes failures before surfacing results to the orchestrator. Notion AI reported it's "the first model to pass our implicit-need tests" — tasks where the model must infer required actions rather than being told what tools to invoke. Hex's CTO observed the model "correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks."
This is a behavior change, not just a capability change. It reduces the rate at which agents surface confidently wrong output.
xhigh effort level — new tier between high and max; Claude Code defaults to xhigh
Prior effort levels were low, medium, high, max. Opus 4.7 adds xhigh between high and max. Anthropic's API docs recommend starting with xhigh for coding and agentic use cases. Claude Code has been updated to default to xhigh across all plans.
Set it explicitly in Claude Code:
/effort xhigh
# or
claude --effort xhigh
# or via environment variable
export CLAUDE_CODE_EFFORT_LEVEL=xhighHex noted that "low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6" — which means if you were using high on Opus 4.6, xhigh on Opus 4.7 is the appropriate starting point for comparable task quality.
Also new: task budgets (public beta). A task budget gives the model a rough token target for an entire agentic loop — thinking, tool calls, tool results, and final output combined. The model sees a running countdown and wraps gracefully as the budget approaches. Use the task-budgets-2026-03-13 beta header to enable.
Vision upgrade — 3.75 MP, XBOW Visual Acuity 98.5% vs 54.5%
Maximum image resolution jumped from 1,568 px / ~1.15 MP to 2,576 px / ~3.75 MP on the long edge — a 3.3× increase in pixel count. This is a model-level change with no API parameter to toggle. All images are now processed at higher fidelity automatically.
The practical difference: pixel coordinates from Opus 4.7 map 1:1 with actual screen coordinates for computer use tasks. Opus 4.6 required a scale-factor correction step. Dense screenshots, technical diagrams, scanned documents, and design mockups all come through at actual fidelity. XBOW Visual Acuity — the computer use screenshot task benchmark — jumped from 54.5% to 98.5%.
Caveat: higher resolution = more tokens per image. If you're passing screenshots where the extra detail doesn't matter, downsample before sending.
The One Catch: Same Price, Different Token Count
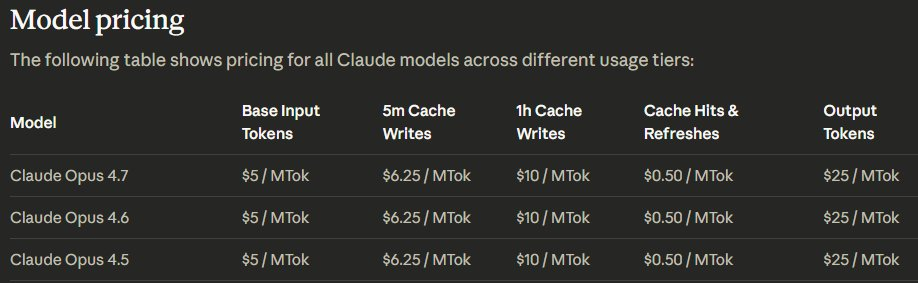
Pricing is unchanged: $5 per million input tokens, $25 per million output tokens, across API, Bedrock, Vertex AI, and Foundry. The Batch API 50% discount and prompt caching also carry over unchanged.
The catch is the tokenizer. Anthropic's migration guide is specific: the new tokenizer produces roughly 1.0–1.35× more tokens for the same input text. Up to 35% more tokens at the same per-token price is effectively a 35% cost increase for that content type.
What the range means in practice
The 1.0–1.35× range is not uniform:
| Content type | Token increase tendency | Notes |
|---|---|---|
| English prose | Low end (~1.0–1.05×) | Minimal impact for most chat |
| Clean code (English identifiers) | Low end (~1.05–1.1×) | Common for most API codebases |
| Technical/mixed content | Mid range (~1.1–1.2×) | Config files, logs, mixed text |
| Multilingual text | Upper end (~1.2–1.35×) | CJK, Arabic, Cyrillic content |
| Structured data (JSON, XML) | Mid to upper range | Varies by schema verbosity |
Anthropic explicitly says: measure on your actual production traffic. /v1/messages/count_tokens now returns different counts for Opus 4.7. Don't assume your token estimates carry over — run a representative sample before migrating at volume.
Additionally, the model "thinks more at higher effort levels," generating more output tokens during reasoning. At xhigh or max, Anthropic recommends setting max_tokens to at least 64K as a starting point.
What's Unchanged
- Context window: 1M tokens, same as Opus 4.6, no long-context premium
- Output limit: 128K tokens per response
- Adaptive thinking and Agent Teams: both carry forward
- Prompt caching: up to 90% cost reduction on cached content
- Pricing structure: $5/$25 per million tokens across all platforms
One notable removal: prefilling assistant messages now returns a 400 error on Opus 4.7. If your prompts use prefill, this is a breaking change that needs handling before migration.
Where Opus 4.7 Does Not Lead
Terminal-Bench 2.0: 69.4% vs GPT-5.4 at 75.1%
Terminal-Bench 2.0 tests command-line task execution — the kind of work coding agents do when running shell commands, managing processes, and operating across terminal sessions. Opus 4.7 scores 69.4%; GPT-5.4 scores 75.1%. That's a 5.7-point gap. Anthropic used the Terminus-2 harness with thinking disabled, and the evaluation methodology is documented in the benchmark footnotes.
For teams running agents that do significant terminal work — CI/CD pipeline management, shell scripting, system administration tasks — this is worth benchmarking on your specific workload before committing.
BrowseComp softened vs Opus 4.6
BrowseComp measures multi-step web research: browse, synthesize, and reason across multiple pages. Opus 4.7 dropped from 83.7% to 79.3% — a 4.4-point regression. GPT-5.4 Pro sits at 89.3%; Gemini 3.1 Pro at 85.9%. Both lead Opus 4.7 on this benchmark.
If your agent pipeline does significant web research, test both Opus 4.7 and GPT-5.4 on representative tasks. Anthropic's own migration guide acknowledges that tool usage at lower effort levels is reduced by default on Opus 4.7 — for agentic search workloads, run at high or xhigh effort and evaluate whether the BrowseComp regression is visible in your actual workload.
FAQ
Is Opus 4.7 available on Bedrock and Vertex AI?
Yes, generally available on day one across Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry, in addition to the Claude API and Claude products.
Does it replace Opus 4.6 immediately?
It is now the default Opus model. Opus 4.6 remains available during a transition period. The migration is not strictly drop-in: the tokenizer change shifts token counts, the stricter instruction-following means prompts written for Opus 4.6 may produce different results, and the prefill removal is a hard breaking change. Anthropic's migration guide covers the full list.
What is Claude Mythos Preview and how does it compare?
Claude Mythos Preview is Anthropic's most capable model, announced April 7, 2026 under Project Glasswing. Anthropic benchmarks show it leading Opus 4.7 across essentially every evaluation category — SWE-bench, reasoning, vision, and agentic tasks. However, it is not generally available. Access is restricted to a limited set of platform partners as part of Anthropic's Project Glasswing initiative. Anthropic explicitly states it does not plan to make Mythos Preview generally available in the near term, though the lessons from its deployment inform future plans for broader Mythos-class model releases. If you don't have a Project Glasswing partnership, Opus 4.7 is the model you can actually use.
Related Reading
- Claude Managed Agents Pricing: What You Actually Pay — How Opus 4.7's tokenizer change interacts with session-hour billing in Claude Managed Agents.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — How Opus 4.7's self-verification behavior and xhigh default affect multi-agent orchestration patterns.
- Superpowers vs Vibe Coding: Structured Agents vs Freeform Prompts — Workflow-level implications of using Opus 4.7's stricter instruction-following with structured agent frameworks.
- GLM-5V-Turbo in AI Coding Agent Workflows — For teams evaluating vision-to-code models: how Opus 4.7's vision upgrade changes the comparison.
- What Is Claude Mythos Preview? — Full breakdown of the model above Opus 4.7: what it can do, who has access, and why it's restricted.
