
I'll be straight with you: when NVIDIA dropped Nemotron 3 Super on March 11, 2026, my first reaction was skepticism. Another massive model, another benchmarks table. But then I looked at the SWE-Bench Verified number — 60.47% on OpenHands harness, compared to GPT-OSS-120B's 41.90% — and I actually had to double-check the source. That's not a marginal improvement. That's a different category of result for an open-weight model, delivered at speeds that make it deployable in real multi-agent stacks, not just in research demos.
If you're building coding agents, evaluating model routing decisions, or leading a team that's asking "which open model do we actually run?" — this article covers what you need to know. No fluff.
What Is Nemotron 3 Super?

30-second answer for developers
NVIDIA Nemotron 3 Super — that's the official name — is a 120-billion-parameter, open-weight model built specifically for agentic AI workloads. It uses a hybrid Mamba-Transformer Mixture-of-Experts architecture, activates only 12B parameters per token during inference, supports a 1-million-token context window, and was released under the NVIDIA Nemotron Open Model License with fully open weights, training datasets, and recipes.
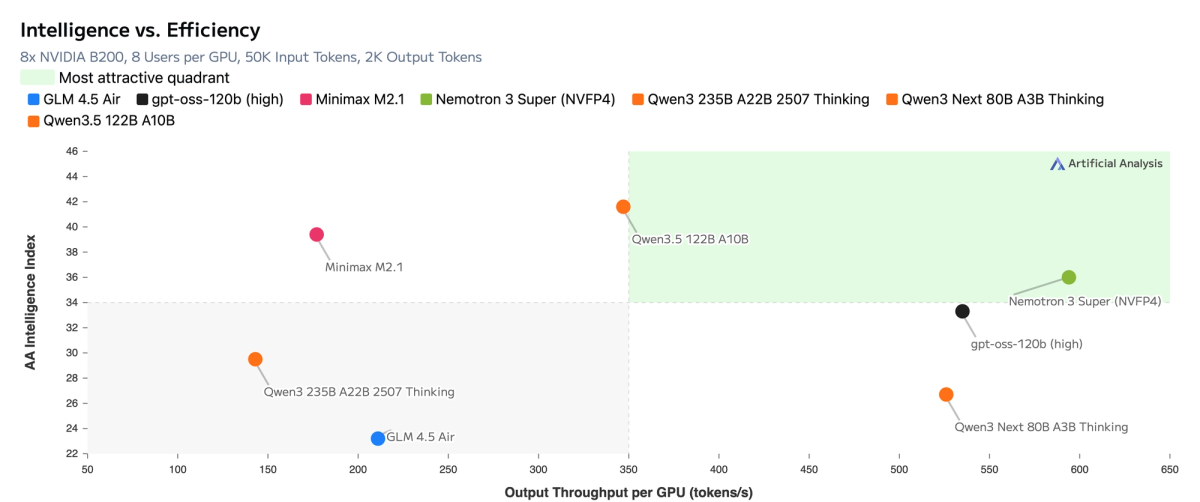
It's the second model in the Nemotron 3 family — following Nemotron 3 Nano (30B, December 2025) — and positions explicitly between Nano (targeted tasks) and the upcoming Nemotron 3 Ultra (500B, not yet released). The target use case is complex, multi-step agentic workflows: software development, cybersecurity triage, financial analysis.
Available now on build.nvidia.com, Hugging Face, OpenRouter, Perplexity, Google Cloud Vertex AI, Oracle Cloud Infrastructure, CoreWeave, Together AI, and more.
The Specs That Actually Matter
120B total, 12B active
The parameter split is the first thing to understand. Most engineers hear "120B" and assume the serving cost of a 120B dense model. That's not how this works.
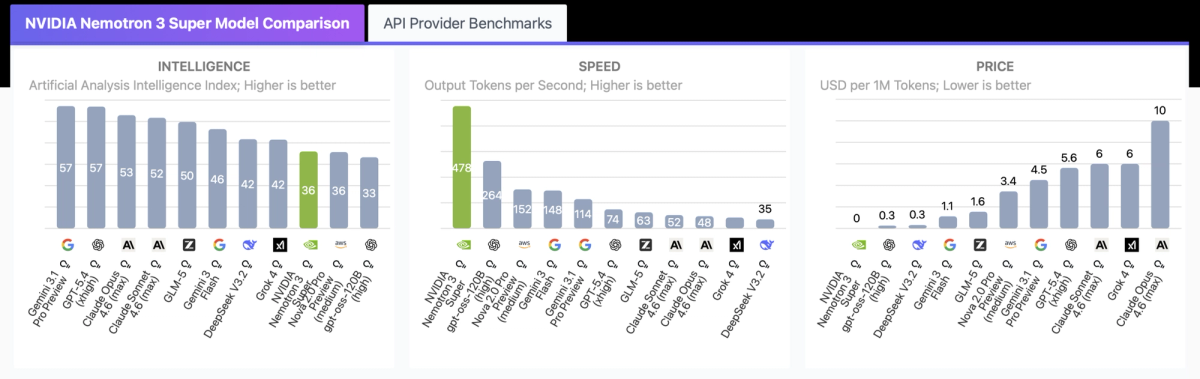
Nemotron 3 Super uses a hybrid Mixture-of-Experts architecture: 120B total parameters, but only 12B are active during any given forward pass. This is what makes the throughput numbers possible. NVIDIA reports up to 2.2x and 7.5x higher inference throughput than GPT-OSS-120B and Qwen3.5-122B respectively, on an 8k input / 16k output setting.
Third-party validation from Artificial Analysis puts it at 478 output tokens per second — the fastest result they've recorded at this model class as of March 2026. GPT-OSS-120B, the second fastest, clocks in at 264 tokens/sec.
The architecture doing this work has three innovations stacked together:
| Feature | What it does | Why it matters for agents |
|---|---|---|
| LatentMoE | Compresses tokens to latent space before routing — activates 4x more experts at the same compute cost | Better reasoning capacity per FLOP |
| Mamba-2 layers | State space model with linear-time complexity vs. sequence length | Makes 1M context practical, not theoretical |
| Multi-Token Prediction (MTP) | Predicts multiple future tokens per forward pass; built-in speculative decoding | Reduces generation latency, especially for long sequences |
The model was pretrained natively in NVFP4 — NVIDIA's 4-bit floating-point format optimized for Blackwell GPUs — from the first gradient update, not quantized after the fact. That distinction matters: the model learned to be accurate within 4-bit arithmetic throughout training.
1M token context
The 1-million-token context window lets agents retain full workflow state in memory and prevents goal drift. For software development agents specifically, a coding agent can load an entire codebase into context at once, enabling end-to-end code generation and debugging without document segmentation.
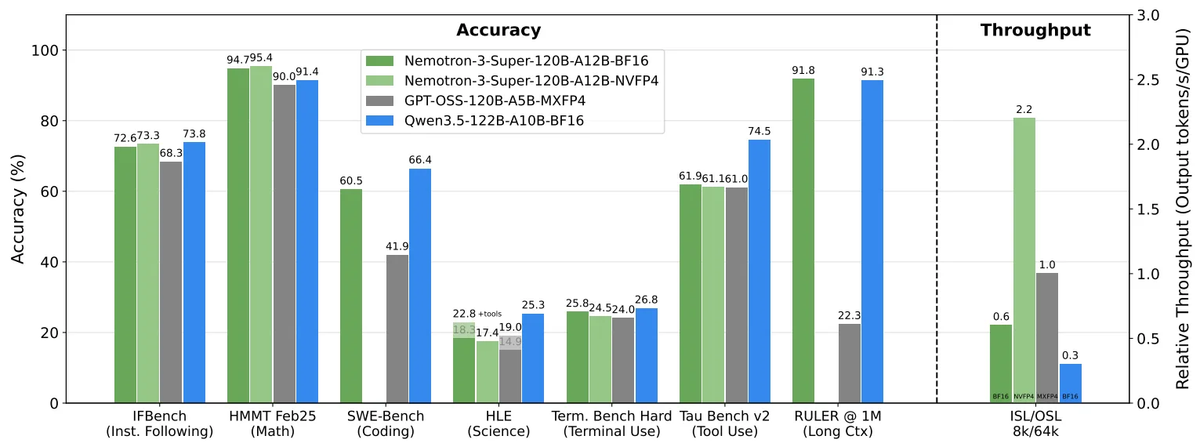
The context retention holds up under benchmarks too. On RULER at 1M tokens, Nemotron 3 Super scores 91.75% versus GPT-OSS-120B's 22.30%. GPT-OSS-120B drops from 52% to 22% accuracy between 256K and 1M tokens — Nemotron 3 Super loses fewer than 5 points across the same 4x context increase.
For multi-agent systems, this is the number that should catch your attention.
What It Is Built For
Coding, planning, tool calling, and agent workflows
The model is trained in three sequential phases: pretraining on 25 trillion tokens using NVFP4, supervised fine-tuning across the task types it will encounter in deployment, and reinforcement learning refined against verifiable outcomes across diverse agentic environments. The RL phase is the primary driver of improvements over Nano on software engineering and tool use benchmarks.
On coding benchmarks specifically:
- SWE-Bench Verified (OpenHands harness): 60.47% — vs. GPT-OSS-120B at 41.90%
- SWE-Bench Multilingual (OpenHands): 45.78% — vs. GPT-OSS-120B at 30.80%
- PinchBench (OpenClaw agent benchmark): 85.6% — top open model in class
For tool calling specifically, the model delivers high-accuracy performance that ensures autonomous agents can reliably navigate massive function libraries, which prevents execution errors in high-stakes environments like autonomous security orchestration.
The model supports 43 programming languages and was trained with explicit agentic scenarios: multi-step tool use, terminal use, planning, and software engineering tasks.
Here's what the quick-start for a coding agent integration looks like, using the OpenAI-compatible endpoint:
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="YOUR_API_KEY"
)
response = client.chat.completions.create(
model="nvidia/nemotron-3-super-120b-a12b",
messages=[
{
"role": "user",
"content": "Refactor this function to handle edge cases: ..."
}
],
temperature=1.0,
top_p=0.95,
extra_body={
"chat_template_kwargs": {"thinking": True} # enable reasoning mode for coding agents
}
)
print(response.choices[0].message.content)Note: NVIDIA recommendstemperature=1.0andtop_p=0.95across all tasks — reasoning, tool calling, and general chat. Thethinkingflag inchat_template_kwargsenables the full reasoning trace for coding agents.
Where It Fits in an AI Coding Stack
Orchestrator vs worker role
Nemotron 3 Nano is well suited for executing targeted individual steps within an agentic workflow. But when multi-agent applications escalate to complex, multi-step activities, they require a higher-capacity model for planning and reasoning — this is where Nemotron 3 Super is the right fit.
Concretely, NVIDIA and Baseten both frame the stack the same way:
| Role | Model | When to use |
|---|---|---|
| Orchestrator / planner | Nemotron 3 Super | Complex task decomposition, multi-step reasoning, routing decisions, deep code understanding |
| Worker / executor | Nemotron 3 Nano | Individual steps within a pipeline: simple PRs, targeted completions, isolated subtasks |
| Deep reasoning | Nemotron 3 Ultra (coming) | Highest-stakes decisions where throughput is secondary to reasoning depth |
For software development, simple merge requests can be addressed by Nano, while complex coding tasks requiring deeper understanding of the codebase are handled by Super.
Real-world integrations that went live on day one include CodeRabbit, Factory, and Greptile — all software development agent platforms integrating Nemotron 3 Super alongside proprietary models to reduce cost while maintaining accuracy.
Deployment options for on-prem or private cloud:
# SGLang serving (recommended for development/testing)
python3 -m sglang.launch_server \
--model PATH/TO/CHECKPOINT \
--served-model-name nvidia/nemotron-3-super \
--trust-remote-code \
--tp 8 \
--ep 4 \
--tool-call-parser qwen3_coder \
--reasoning-parser super_v3Self-hosting requires 8x H100-80GB GPUs at BF16 precision. The model is also packaged as an NVIDIA NIM microservice with support for vLLM, TensorRT-LLM, and SGLang.
Limits and Trade-offs
Let me be honest about where this model isn't the right call.
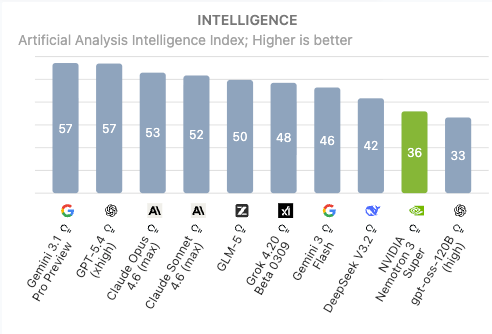
Intelligence ceiling is real. On the Artificial Analysis Intelligence Index v4, Nemotron 3 Super scores 36. That puts it above gpt-oss-120B (33), but meaningfully behind Gemini 3.1 Pro and GPT-5.4 (both at 57). It's also behind newer models like Qwen3.5-122B, DeepSeek V3.2, and GLM-5 on raw intelligence benchmarks. If your use case requires frontier-level reasoning on open-ended problems, this model isn't that.
Verbosity. During Artificial Analysis's Intelligence Index evaluation, the model generated 110M tokens — against an average of 7.3M across comparable models. That verbosity means output token costs add up quickly at scale. API pricing at the time of writing: $0.30/1M input tokens and $0.80/1M output tokens (via DeepInfra as low as $0.10/$0.50). Plan your cost model accordingly.
Blackwell optimization. The NVFP4 pretraining delivers best results on NVIDIA Blackwell hardware. On Hopper or other hardware, expect degraded throughput gains — though FP8 and BF16 checkpoints are available.
SWE-Bench gap vs. Qwen3.5. At 60.47% on SWE-Bench Verified, Nemotron 3 Super sits roughly 6 points behind Qwen3.5. That gap may matter for pure coding accuracy benchmarks. The counterpoint: Nemotron 3 Super delivers 2.2x the throughput of GPT-OSS-120B at comparable accuracy — and for multi-agent systems running dozens of concurrent agents, that throughput-per-accuracy tradeoff often wins.
Context window practical limits. The 1M token window is native and well-benchmarked, but full 1M context runs require sufficient GPU memory. Plan infrastructure accordingly before assuming the full window is available in your deployment environment.
Who Should Evaluate It First
Quick gut-check:
You should run a serious evaluation if you are:
- A senior developer or tech lead building multi-agent software pipelines where throughput and cost matter alongside accuracy
- Running open-weight models in on-prem or private cloud environments (financial services, healthcare, defense) where model control matters
- Evaluating model routing strategies — Super as orchestrator, Nano as worker — for agent cost optimization
- Already using CodeRabbit, Factory, Greptile, or similar coding agent platforms that have already integrated it
You can probably wait if:
- Your priority is single-model, highest-accuracy reasoning on open-ended tasks — Gemini 3.1 Pro or GPT-5.4 are ahead on overall intelligence
- You're on non-Blackwell infrastructure and can't capture the NVFP4 performance gains
- You're cost-optimizing at the individual query level rather than high-volume concurrent agent workloads
The technical report is publicly available, and the full training recipe — weights, datasets, RL environments — is on the Nemotron Developer Repository. For a model at this capability level, that level of openness is unusual and worth taking seriously.
If you're already using multi-agent coding pipelines, this is worth a structured benchmark against your actual workloads. The numbers suggest it'll hold up.
Related Articles
- Best AI Coding Model in 2026: Sonnet 5, GPT-5, Codex, Gemini 3 Compared
- Multi-Agent Coding Tools: How to Build a Real Agent Stack
- Best AI Coding Assistant in 2026: What Senior Devs Are Actually Using
- How to Run Parallel Claude Code Agents in Your Workflow
- AI Coding Tools Predictions 2026: What's Actually Changing
