
Most model comparisons give you a table and walk away. This one won't. I've been testing all three Gemini 3.1 tier models since launch — and the honest answer to "which one?" depends on exactly one question you need to answer about your workload before you pick anything. I'll get to that. But first, the facts.
Gemini 3.1 Pro launched February 19, 2026. Flash-Lite followed on March 3, 2026. Gemini 3.0 Flash is the incumbent, already in production across developer stacks worldwide. Three models, three very different cost-performance tradeoffs — and per Vertex AI pricing, the price gap between cheapest and most expensive is 8:1.
Quick Comparison Table
| Gemini 3.1 Flash-Lite | Gemini 3.0 Flash | Gemini 3.1 Pro | |
|---|---|---|---|
| Launch date | Mar 3, 2026 | Dec 2025 | Feb 19, 2026 |
| Status | Preview | GA | GA |
| Input price (per 1M tokens) | $0.25 | $0.30 | $2.00 |
| Output price (per 1M tokens) | $1.50 | $1.50 | $8.00 |
| Context window | 1M tokens | 1M tokens | 1M tokens |
| Max output tokens | 64K | 64K | 64K |
| Speed (tokens/sec) | ~287 t/s | ~114 t/s | Slower |
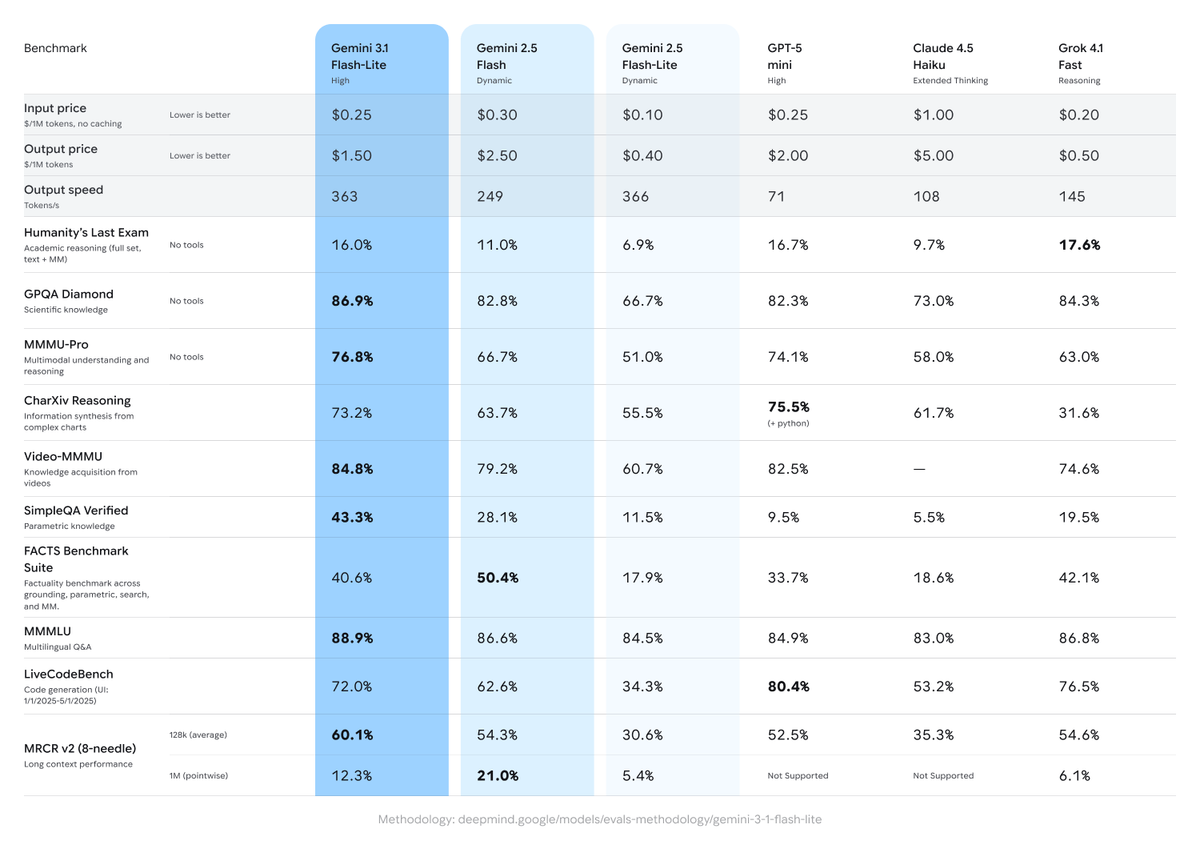
| GPQA Diamond | 86.90% | — | 94.30% |
| ARC-AGI-2 | — | — | 77.10% |
| FACTS benchmark | 40.60% | 50.40% | Higher |
| Thinking levels | Minimal / Low / Medium / High | Limited | Low / Medium / High |
| Architecture base | Gemini 3 Pro (optimized) | Gemini 3 | Gemini 3 |
Numbers are current as of March 2026 — pricing pulled from Google's API pricing page, benchmark scores from Artificial Analysis and Google DeepMind's model cards.
One thing that doesn't show up cleanly in tables: Flash-Lite is architecturally derived from Gemini 3 Pro — not from Flash. Per Google DeepMind's official model card, it's a Pro-derived model optimized for throughput and latency. That's why its benchmark scores are sometimes surprising for the price point.
Gemini 3.1 Flash-Lite

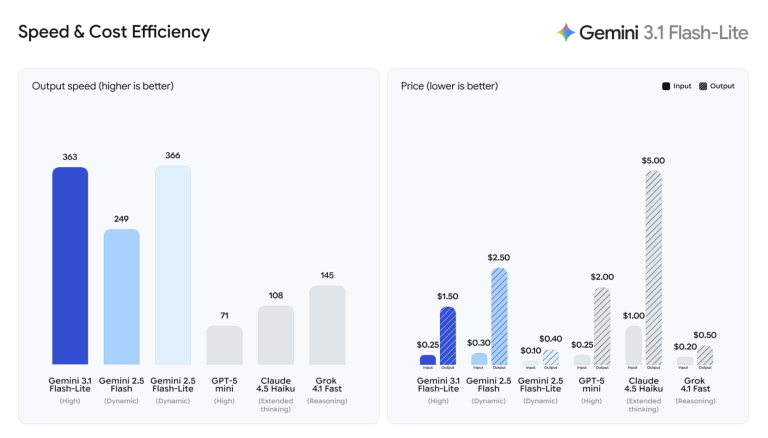
Flash-Lite is Google's answer to a specific problem: high-volume workloads where per-call cost determines whether a product is viable. At $0.25 per million input tokens, it's 1/8th the price of Pro — and according to Google's official launch post, it's 2.5x faster on time-to-first-token than Gemini 2.5 Flash.
What makes it structurally different from the other two: it's the only model in this lineup with a four-level thinking system (Minimal, Low, Medium, High). Everything else either has fewer levels or fixed reasoning depth.
Best For
- Real-time pipelines where latency is a hard constraint: live translation, streaming classification, instant UI generation
- High-volume classification: content moderation, sentiment analysis, ticket triage at thousands of calls per day
- Router/orchestrator role: Flash-Lite reads incoming requests, classifies complexity, and routes to Flash or Pro only when needed — fast and cheap enough that the routing step adds negligible cost
- Structured generation at scale: e-commerce product tagging, changelog generation, dashboard population
- Workloads where thinking level can be tuned per request: different tasks in the same pipeline can use different reasoning depth
A practical data point: using Flash-Lite as a router across a mixed batch of 100 tasks (half simple, half complex) cut total API cost by ~40% compared to running everything through Flash, with no quality loss on complex tasks.
Limitations
- FACTS benchmark gap: Flash-Lite scores 40.6% on FACTS (factuality across grounding, knowledge, and multimodal tasks), versus 50.4% for Gemini 3.0 Flash Dynamic. For applications where factual grounding matters — research tools, knowledge assistants, document Q&A — Flash-Lite loses.
- Preview status: No SLA, rate limits are more restrictive, API may change before GA. Not suitable for production deployments that need guaranteed stability right now.
- Vague prompt handling: Flash-Lite handles structured, clear instructions well. Open-ended prompts ("design something modern and clean") tend to undershoot — you get plausible output, not precise output.
- TTFT variability: At 6.15s average time-to-first-token (per Artificial Analysis), it's faster than the median for reasoning models in its tier — but in streaming applications, expect more variance than Flash.
Gemini 3.1 Flash
Gemini 3.0 Flash is the incumbent. It's been in production since December 2025, it's GA, it has mature integrations across Google AI Studio, Vertex AI, Gemini CLI, and Android Studio. It's the model most existing developer stacks are already running on.
It sits one step above Flash-Lite in the intelligence hierarchy, and the gap shows on factuality-dependent tasks. The 50.4% FACTS score versus Flash-Lite's 40.6% is meaningful if your application grounds answers in retrieved content, parametric knowledge, or multimodal inputs.
Best For
- Production applications that need stability today: GA status, proven track record, no surprise API changes
- Factuality-critical tasks: document Q&A, research assistants, knowledge base lookup — anything where "is this answer accurate?" matters more than "did this answer arrive in 300ms?"
- Moderate-complexity generation: tasks that sit above simple classification but don't need Pro's full reasoning depth
- Teams already integrated with Flash: switching to Flash-Lite or Pro requires re-testing and re-tuning. If your current Flash deployment is working, the bar to switch should be high.
Limitations
- Speed: Significantly slower than Flash-Lite. At ~114 tokens/second versus Flash-Lite's ~287, it's not a real-time model for latency-critical applications.
- Priced between Flash-Lite and Pro: At $0.30/M input, it costs more than Flash-Lite without matching Pro's reasoning. For tasks that genuinely need deep reasoning, the price delta to Pro becomes worth considering.
- Thinking level support is limited compared to Flash-Lite's full four-level system.
- Gemini 2.0 Flash is deprecated (shutdown June 1, 2026 per the API docs) — confirm which Flash version your stack is running. Gemini 3.0 Flash is the current GA version.
Gemini 3.1 Pro
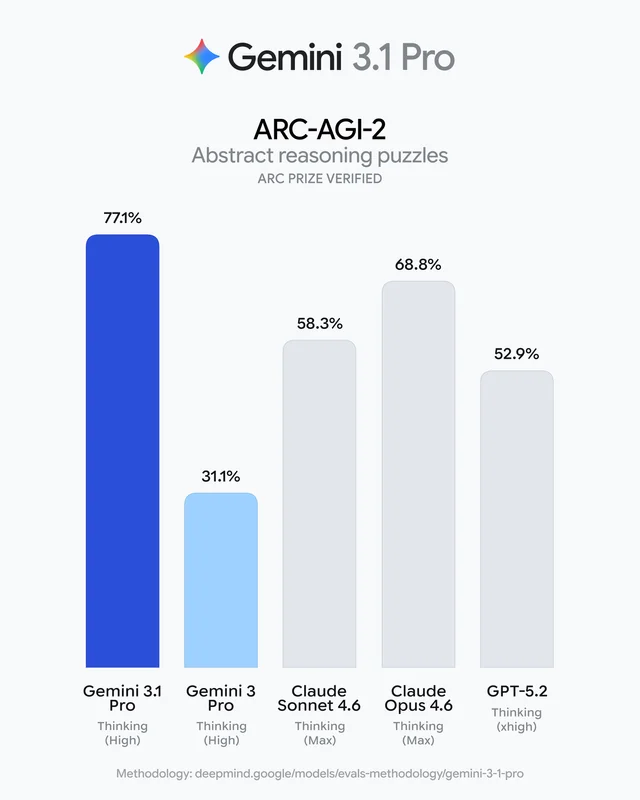
Pro is where the Gemini 3 series actually earns its name. It launched February 19, 2026, with an ARC-AGI-2 score of 77.1% — more than double what the previous generation scored — and it leads on 13 of 16 benchmarks measured by Google DeepMind. At 94.3% on GPQA Diamond (graduate-level science reasoning), it's one of the highest-scoring models on that benchmark.
The price reflects it: $2.00 per million input tokens, $8.00 per million output tokens. That's 8x Flash-Lite on input. For high-context usage above 200K tokens per interaction, the gap between Pro and Flash-Lite grows to 12–16x, per VentureBeat's analysis of the launch.
Best For
- Complex multi-step reasoning: financial modeling, scientific analysis, legal document synthesis — tasks where the model needs to hold multiple competing constraints in memory across a long chain of logic
- Long-context synthesis: research across massive documents, large codebases, legal discovery — the 1M token context window is the same across all three models, but Pro uses it better on tasks requiring retrieval + reasoning
- Agentic coding: multi-turn software engineering tasks where correctness across steps is non-negotiable. Pro handles these where Flash-Lite hits ambiguity walls.
- Advanced multimodal analysis: video, audio, and image understanding at depth — not just classification, but cross-modal reasoning
- Animated SVG and complex code generation: early-access developers found Pro consistently outperformed Flash models on code-creative tasks
Limitations
- Cost at scale is real: $2.00/M input is manageable for low-volume, high-value tasks. For pipelines running thousands of calls per day, it's prohibitive unless those calls genuinely require frontier reasoning.
- Slower than both Flash models: Pro trades latency for reasoning confidence. If your use case is time-sensitive, this is a disqualifying factor.
- Overkill for most tasks: The majority of real-world developer workloads — classification, generation, summarization, Q&A — don't need Pro-level reasoning. Paying for it anyway is a common and expensive mistake.
Decision Guide
Choose Flash-Lite If…
- Your per-call cost directly determines whether your product margin works
- Your pipeline is high-volume (thousands+ calls/day) and latency matters
- You need to tune reasoning depth per request type — not all calls need the same intelligence
- You want to use Flash-Lite as a smart router that classifies request complexity and escalates to Flash or Pro only when needed
- You can tolerate preview-stage limitations (no SLA, possible API changes)
- Your inputs are structured and prompts are specific — not open-ended
Choose Flash If…
- You need production stability with a GA model right now
- Factual accuracy and grounding quality matter more than raw speed
- You're already integrated with Flash and re-testing isn't worth the cost
- Your tasks sit in the moderate-complexity zone — above classification, below deep reasoning
- You want a battle-tested model with a long track record in real developer stacks
Choose Pro If…
- The task genuinely requires deep, multi-step reasoning that Flash models demonstrably fail at
- You're working with long documents or codebases where synthesis quality justifies the cost
- You're building agentic workflows where each step's output affects the next — and errors compound
- Budget is secondary to output quality for this specific workload
- You want access to the highest benchmark scores in the Gemini 3 lineup
The honest default: most high-volume workloads should start with Flash-Lite. Use it for routing. Escalate 10–20% of requests to Flash for factuality-sensitive tasks. Reserve Pro for the specific problem types where you've confirmed Flash can't deliver. That architecture — Flash-Lite as reflexes, Pro as brain — is how the Gemini 3 series is designed to be used, and it's significantly cheaper than picking one model and running everything through it.
You might also find these useful:
