
You're building a high-volume pipeline — translation, moderation, document triage — and the cost math on your current model doesn't work at scale. Sound familiar? Gemini 3.1 Flash-Lite launched on March 3, 2026, and it's Google's answer to exactly that problem: 2.5x faster than its predecessor, priced at $0.25 per million input tokens, and smart enough to handle real production workloads. I've been testing it against translation pipelines, content queues, and UI generation tasks since launch. Here's what actually matters.
What Is Gemini 3.1 Flash-Lite?

Gemini 3.1 Flash-Lite is Google's fastest and most cost-efficient model in the Gemini 3 series, built specifically for high-volume developer workloads. Think of it as the workhorse of the Gemini 3 family — not the brain (that's Gemini 3.1 Pro), but the reflexes.
It's currently rolling out in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI. Worth noting: it's not available in the consumer Gemini app — this is a developer-facing release.
The model handles text, image, speech, and video input, outputs text, and has a 1 million token context window with knowledge up to January 2025.
Where It Fits in the Gemini 3.1 Family
Here's the honest picture of how the family breaks down:
| Model | Best For | Input Price | Output Price | Context Window |
|---|---|---|---|---|
| Gemini 3.1 Pro | Deep reasoning, research, complex coding | $2.00/1M tokens | $18.00/1M tokens | 2M tokens |
| Gemini 3.1 Flash | Balanced tasks, agentic workflows | ~$0.30/1M tokens | ~$2.50/1M tokens | 1M tokens |
| Gemini 3.1 Flash-Lite | High-volume execution, translation, tagging | $0.25/1M tokens | $1.50/1M tokens | 1M tokens (32K for API) |
The strategic play here is using 3.1 Pro for initial planning and architecture, then handing off high-frequency repetitive execution to Flash-Lite at a fraction of the cost. In high-context usage above 200,000 tokens, Flash-Lite is between 12x and 16x cheaper than Pro — that math changes your infrastructure budget completely.
Key Features
Speed

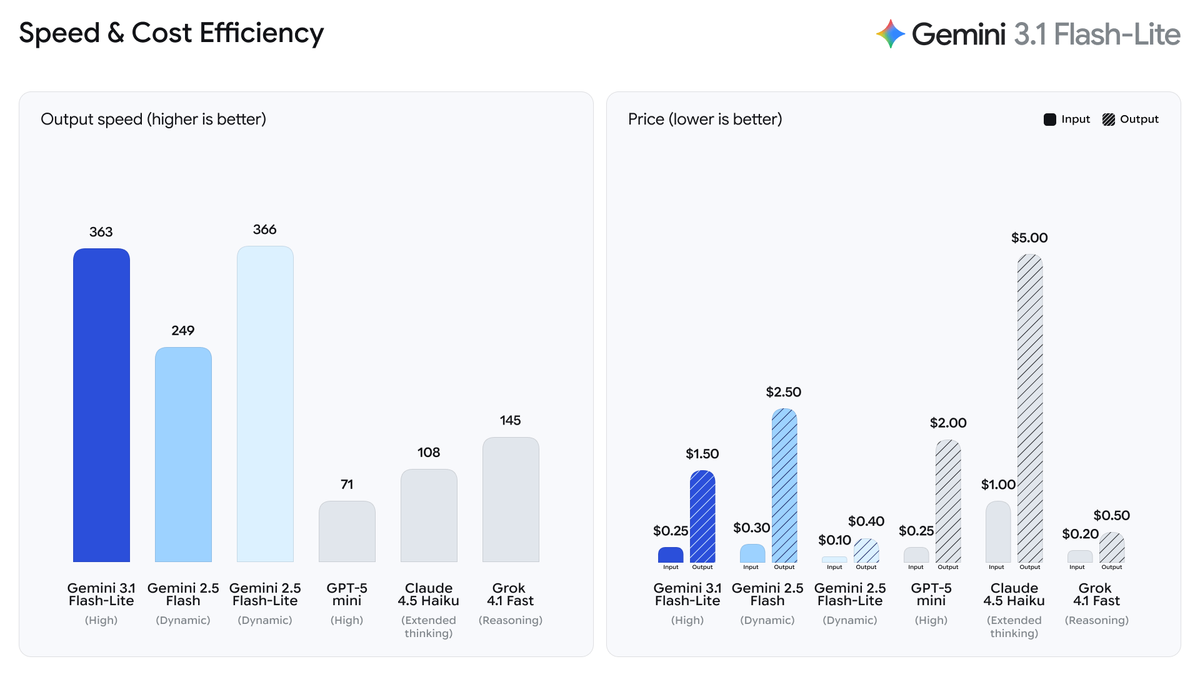
This is where Flash-Lite genuinely impressed me. Compared to Gemini 2.5 Flash:
- 2.5x faster Time to First Answer Token
- 45% faster output generation speed
- Up to 363–389 tokens per second in benchmark testing
For high-frequency workflows — imagine processing thousands of customer support tickets in real time — that latency reduction isn't a nice-to-have, it's the whole point. Early testers reported intent routing accuracy of 94% at this speed, which is the kind of number that makes you rethink how you architect a pipeline.
One caveat: the time to first token (TTFT) clocks in at around 5.18s on the Artificial Analysis benchmark, which is on the higher side compared to other models in the same price tier. For streaming use cases, factor that in.
Thinking Levels
This is the feature I found most interesting from an engineering standpoint. Flash-Lite introduces a thinking_level parameter — replacing the older thinking_budget approach from the 2.5 series — giving you four settings to trade off cost against reasoning depth:
| Thinking Level | Best For | Behavior |
|---|---|---|
| minimal | High-volume simple tasks (default for Flash-Lite) | Minimal token usage, fastest, lowest cost |
| low | Classification, tagging, routing | Slightly more reasoning |
| medium | Moderate complexity, multi-constraint problems | Balanced approach |
| high | Math, complex logic, multi-step reasoning | Most thorough, higher cost |
Here's what calling it looks like with the Python SDK:
from google import genai
from google.genai import types
client = genai.Client()
# Minimal thinking — best for translation/moderation at scale
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="Translate this review to Spanish: 'Great product, fast shipping!'",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="minimal")
),
)
# High thinking — for complex reasoning tasks
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="Analyze the logical consistency of this argument...",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="high")
),
)
print(response.text)One thing that caught me off guard: minimal is the default for Flash-Lite (unlike other Gemini 3 models which default to high). That's intentional — it keeps the model cheap and fast for the bulk tasks it's designed for. See the official thinking documentation for full details on how thought signatures work.
Multimodal Support
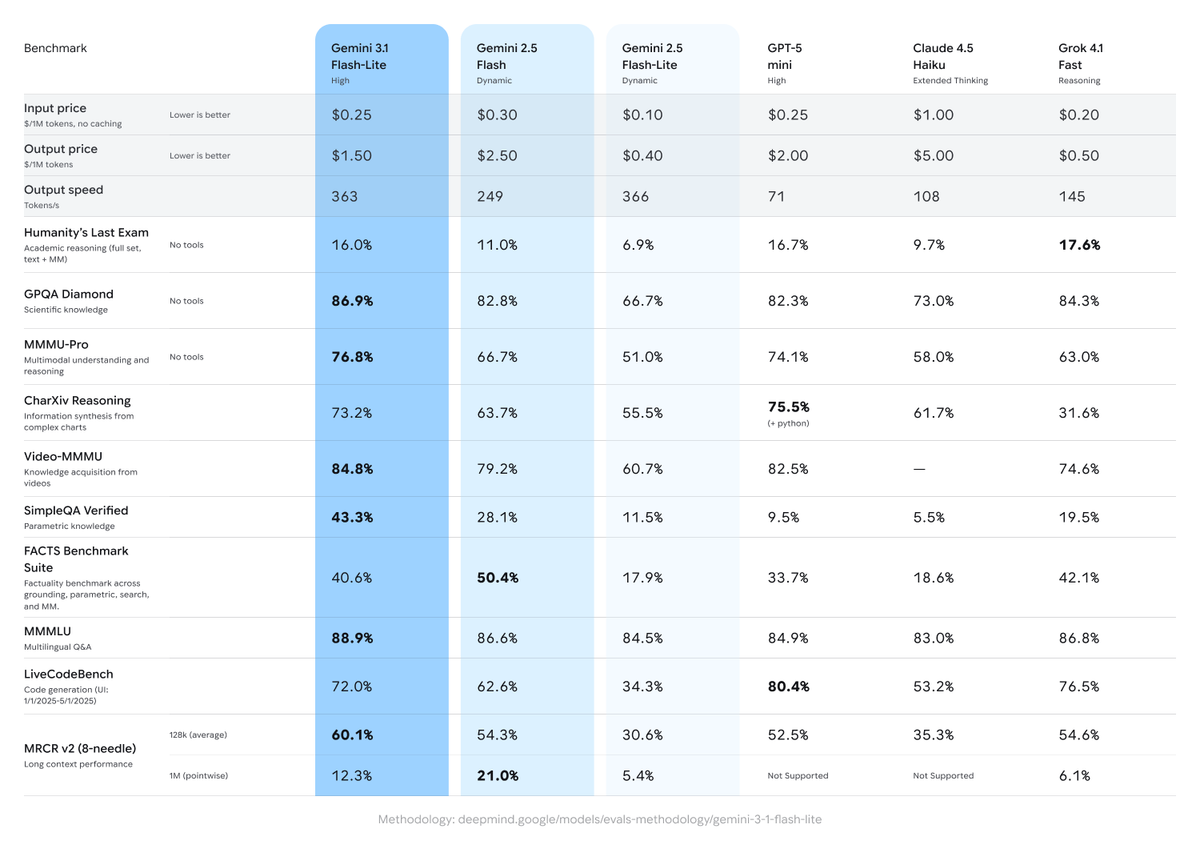
Flash-Lite handles text, image, speech, and video input — all in the same 1M token context window. On multimodal benchmarks it scored 1,432 Elo points on the Arena.ai Leaderboard and 76.8% on MMMU Pro. Solid for its price tier.
Across 11 benchmarks run by Google, it came out on top in 6, beating GPT-5 mini and Claude 4.5 Haiku. On GPQA Diamond (doctorate-level science questions), it scored 86.9%. For context, Gemini 3.1 Pro hits 94.3% on the same benchmark — so Flash-Lite holds its own in general science knowledge but isn't the right pick for frontier reasoning tasks.
Pricing
Straight to the numbers you need:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Blended (3:1 ratio) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | $0.56 |
| Gemini 2.5 Flash | $0.30 | $2.50 | $0.70 |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | $0.18 |
| GPT-5 mini | $0.25 | $2.00 | $0.69 |
| Claude 4.5 Haiku | $1.00 | $5.00 | $1.75 |
| Grok 4.1 Fast | $0.20 | $0.50 | $0.28 |
One nuance worth flagging: Flash-Lite is more expensive than its predecessor (Gemini 2.5 Flash-Lite was $0.10/$0.40), but it's also significantly more capable — it matches 2.5 Flash's quality at a lower price than 2.5 Flash. That's a better deal if you were already paying for 2.5 Flash.
The Batch API is also an option for non-time-sensitive workloads: you get 50% off standard pricing, with a target turnaround of 24 hours. For bulk processing jobs, that changes the math considerably.
There is a free tier during preview — 1 million input tokens free — so you can run real workloads before committing to a bill.
What It's Good At
No hedging here — these are the use cases where I'd reach for Flash-Lite without hesitation:
Translation at scale. Processing thousands of chat messages, reviews, or support tickets? Flash-Lite's speed and cost profile is built for exactly this. You can constrain output with a system instruction so you're not paying for extra tokens:
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
config={"system_instruction": "Only output the translated text"},
contents="Translate to Japanese: 'Your order has shipped.'",
)Content moderation. High-frequency, repetitive classification where consistent results matter more than deep reasoning. Early testers reported 94% accuracy on intent routing — good enough for production queues.
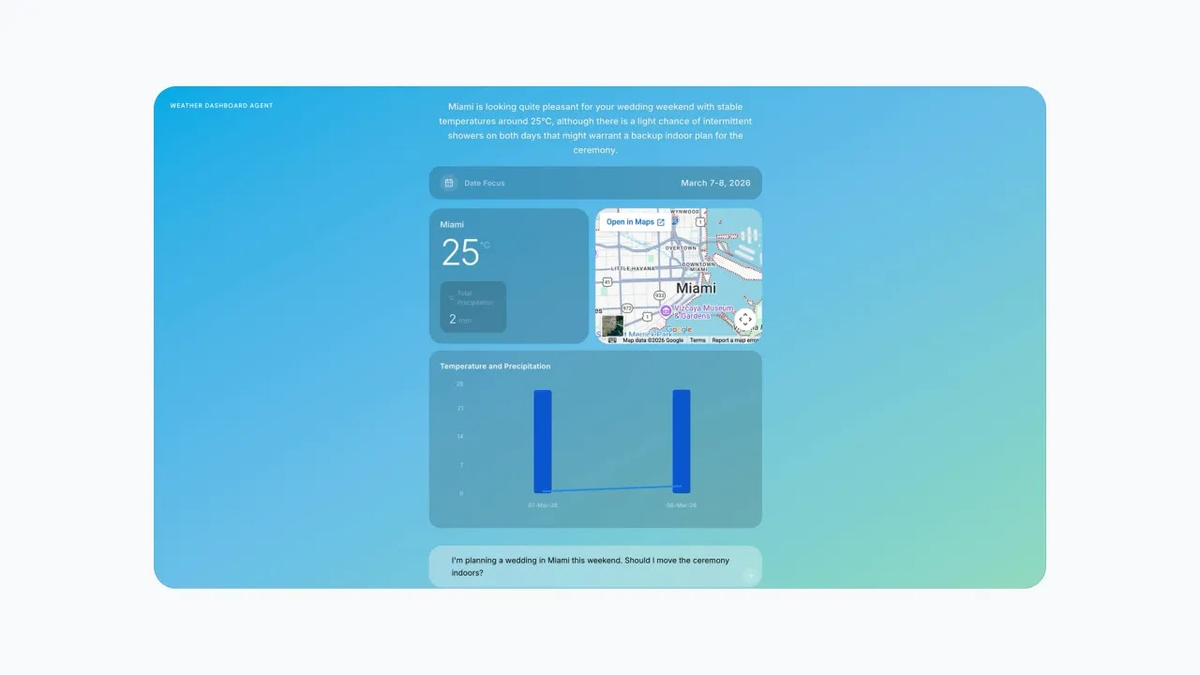
UI and dashboard generation. This one surprised me. Flash-Lite can fill an e-commerce wireframe with hundreds of products or generate a dynamic weather dashboard in real time. More capable than I expected at this price tier.
Document processing and summarization. PDF triage, incoming file parsing, quick summaries — Flash-Lite handles multimodal inputs well for these workflows.
Agentic routing and orchestration. Using Flash-Lite as the "intake" model that classifies incoming requests and routes complex ones to Pro is genuinely smart architecture. It keeps your costs down while ensuring heavy tasks still get serious compute.
What It's Not Good At
Being honest about where the edges are:
Deep, multi-step reasoning. A 16% score on the Humanity's Last Exam (HLA) benchmark tells you where the ceiling is. Gemini 3.1 Pro scores 44.4% on the same test. For complex research synthesis, legal analysis, or frontier math, Pro is the right call.
Very long context work. The API context window is 32,000 tokens — enough for most tasks, but drastically smaller than Flash's 1M or Pro's 2M. If you're working with full codebases or long document sets, this is a hard constraint.
Agent fleets. Google explicitly didn't publish agent benchmarks for Flash-Lite, stating it's intended for data processing rather than managing fleets of agents. Don't architect a complex multi-agent system around it without testing first.
Real-time streaming where TTFT matters. The ~5.18s time to first token is on the high end for a "lite" model. If you're building a chat interface where perceived speed matters, that latency might feel slow to users even though total throughput is fast.
The Bottom Line
Gemini 3.1 Flash-Lite fills a real gap: it's faster than 2.5 Flash, cheaper than 2.5 Flash at comparable quality, and smart enough — with configurable thinking levels — to handle workloads that older "lite" models would've dropped. For high-volume translation, moderation, extraction, and routing tasks, it's the most cost-effective option I've tested in this tier as of March 2026.
Get started at Google AI Studio or check the Vertex AI documentation for enterprise setup. The free preview tier is there — run your actual workload before you commit to anything.
You might also find these useful:
Gemini 3.1 Pro: Debug Workflow
