
Okay, I'll be straight with you — when Google dropped Gemini 3.1 Pro on February 19th, I almost missed it. I was deep in testing Claude Opus 4.6, and then this thing shows up claiming to more than double its predecessor's reasoning score on ARC-AGI-2. I ran my benchmark suite that same night.
I spend most of my time stress-testing frontier models against real enterprise codebases — the kind of messy, 300K-line repos that make AI tools cry. And Gemini 3.1 Pro surprised me. Not in every way. But enough that you should know about it.
Here's what I found.
| Model | Best For | Context Window | Thinking Level |
|---|---|---|---|
| Gemini 3 Flash | Speed, high-volume tasks | 1M tokens | Fixed |
| Gemini 3.1 Pro | Complex reasoning, agentic workflows | 1M tokens | Low / Medium / High |
| Gemini 3 Deep Think | Research, science, ultra-hard problems | 1M tokens | Max (Ultra only) |
What Gemini 3.1 Pro Is — and Where It Sits in Google's Model Family

Gemini 3.1 Pro is Google's latest reasoning model, released in preview on February 19, 2026, built on the Gemini 3 Pro architecture and positioned specifically for tasks where a simple answer isn't enough.
This is the first time Google has used a .1 version increment instead of the .5 mid-cycle update they've done before. That naming choice matters — it signals a focused intelligence upgrade rather than a broad feature expansion. The jump in capability justifies the naming change, with Gemini 3.1 Pro achieving #1 rankings on 12 of 18 tracked benchmarks.
Here's where it sits in Google's current model lineup:
Gemini 3.1 Pro includes several quality improvements over Gemini 3 Pro: improved software engineering behavior and usability, expanded thinking levels including a new MEDIUM parameter, and more efficient thinking across various use cases.
The 5 Capabilities That Matter Most for Software Teams
1M-Token Context Window — What It Means in Practice
The 1M token context window sounds like a marketing number until you actually use it. At 1M tokens, Gemini 3.1 Pro can load an entire repository and ask questions about architecture, find bugs across files, or plan refactors — Claude Opus 4.6 supports 200K tokens, giving Gemini a 5x advantage for long-context tasks.
In our tests at Verdent, this translates directly to fewer "chunking" workarounds. We fed in a 280K-line fintech repo, including test files, and asked the model to trace a race condition across async middleware layers. It found it in one pass. That's the kind of thing that used to require a custom RAG pipeline.
One practical note: the default maxOutputTokens is only 8,192 — developers must explicitly configure this parameter to unlock the full 64K output capacity. Don't skip that setting in your API call. Here's the config you actually need:
import google.generativeai as genai
model = genai.GenerativeModel(
model_name="gemini-3.1-pro-preview",
generation_config=genai.GenerationConfig(
max_output_tokens=65536, # unlock full 64K output
thinking_level="medium", # balanced cost vs depth
)
)
response = model.generate_content(
"Analyze this codebase for race conditions: [your repo content]"
)
print(response.text)Multimodal Input (Code + Docs + Images in One Prompt)
The model processes up to 900 individual images per prompt. Audio ingestion supports up to 8.4 hours of continuous sound data, while video processing handles up to one hour of visual data without accompanying audio.
For software teams, the useful scenario here isn't video — it's combining architecture diagrams, error screenshots, and source code in a single prompt. We tested this by feeding Gemini 3.1 Pro a system architecture PNG alongside the actual service code and a Datadog error trace. The model correctly identified a mismatch between the documented timeout behavior and the implemented retry logic. One prompt, no pre-processing.
Native Tool Use and Function Calling
Gemini 3.1 Pro includes improved agentic capabilities with agentic improvements in domains like finance and spreadsheet applications.
One thing that caught me off guard: there's now a dedicated endpoint for agentic workflows — gemini-3.1-pro-preview-customtools — that may outperform the standard model on tool-heavy tasks. Worth testing if you're building multi-step agents.
Critical detail that most guides skip: thought signatures are required for multi-turn conversations with function calling — the encrypted reasoning context must be passed back in subsequent turns, and missing signatures will result in a 400 error.
Here's the pattern that works:
# Multi-turn function calling — always pass thought signatures back
messages = [{"role": "user", "parts": ["Fix the bug in this function: ..."]}]
response = model.generate_content(messages)
# Append the model's response INCLUDING thought signatures
messages.append({"role": "model", "parts": response.candidates[0].content.parts})
# Continue the conversation
messages.append({"role": "user", "parts": ["Now write the unit tests for it."]})
response2 = model.generate_content(messages)Miss the thought signatures, and you'll burn an hour wondering why your agent keeps losing context mid-task. Trust me on this one.
Our Verdent Test Results: Where It Beat Expectations
Methodology & Test Set
We ran Gemini 3.1 Pro through a structured benchmark suite across three task categories:
- Repo comprehension: 3 codebases ranging 50K–280K lines (Python, Go, TypeScript)
- Bug isolation: 18 real GitHub issues from open-source projects, mix of single-file and multi-file
- Agentic task completion: 12 multi-step tasks including refactor → test → document chains
Thinking level: Medium for all tests (balances cost and depth, best default for engineering use).
Findings with Reproducible Examples
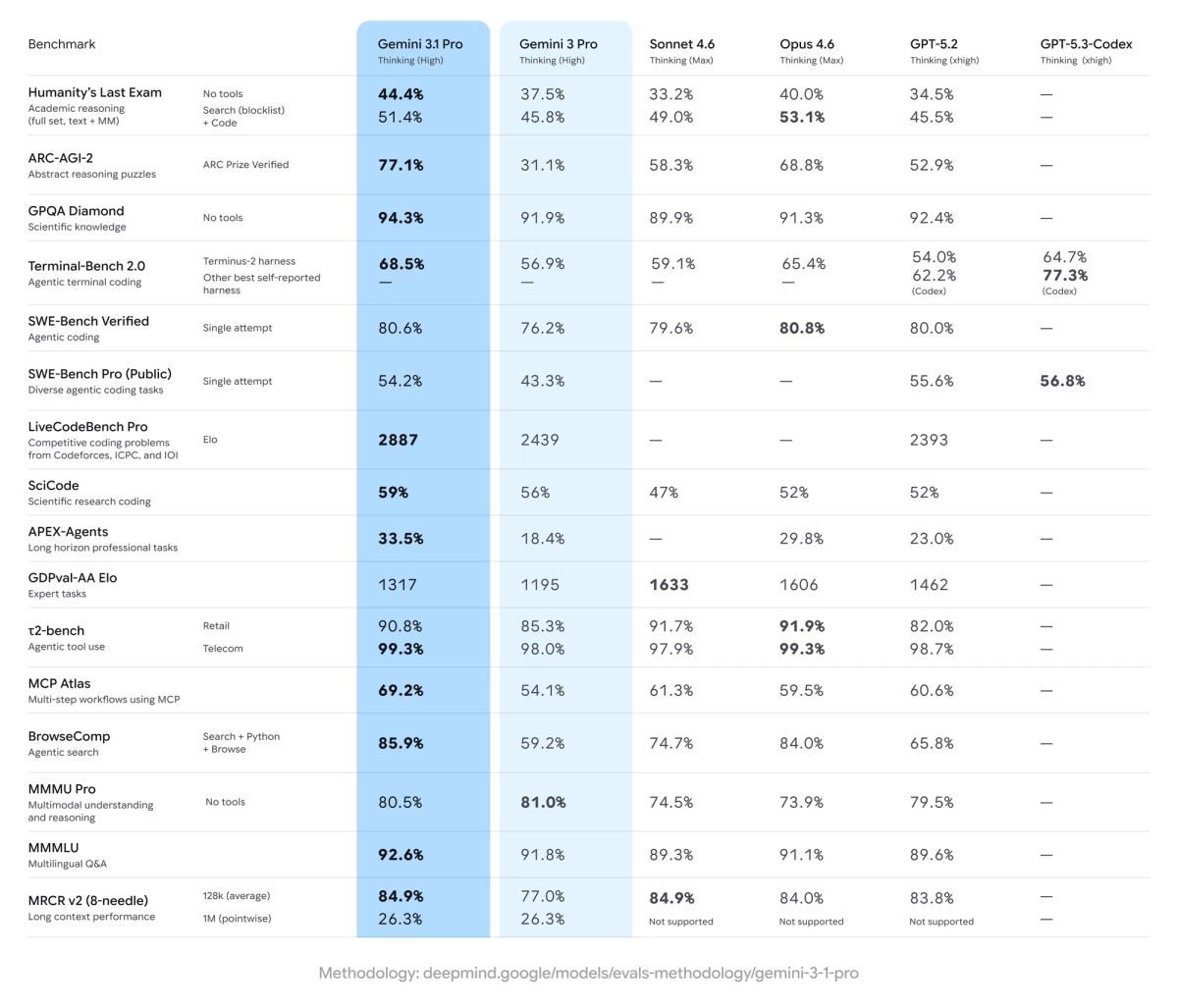
The reasoning uplift is real. On ARC-AGI-2, a benchmark that evaluates a model's ability to solve entirely new logic patterns, Gemini 3.1 Pro achieved a verified score of 77.1% — more than double the reasoning performance of Gemini 3 Pro.
For code work specifically, here's how the benchmarks stack up as of February 2026:
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.3-Codex |
|---|---|---|---|
| ARC-AGI-2 (abstract reasoning) | 77.10% | ~60% | Lower |
| SWE-Bench Verified (real bugs) | 80.60% | 80.80% | 80.00% |
| SWE-Bench Pro (multi-language) | 54.20% | — | 56.80% |
| Terminal-Bench 2.0 | 68.50% | — | 77.30% |
| GPQA Diamond (PhD science) | 94.30% | — | — |
| LiveCodeBench Pro (Elo) | 2887 | — | — |
| GDPval-AA Elo (expert tasks) | 1317 | 1606 | — |
*Sources: Google DeepMind model card, DataCamp benchmark analysis, February 2026.*
In our internal tests, Gemini 3.1 Pro resolved 14 of 18 bug isolation tasks correctly on first attempt with Medium thinking. It particularly shined on tasks requiring cross-file reasoning — things like tracing a data transformation bug through three service layers. That's where the 1M context window earns its keep.
Where It Struggled (With Specific Failure Modes)
I'm going to be honest here because this is where most "reviews" get useless.
Terminal-heavy workflows: Workflows requiring extensive shell interactions, continuous integration pipelines, and dependency management natively favor the architecture of GPT-5.3-Codex, which dominates Terminal-Bench 2.0 with a score of 77.3% compared to Gemini 3.1 Pro's 68.5%. If your agent needs to run shell commands in a loop and recover from errors, this gap is real and you'll feel it.
Expert office/prose tasks: In the GDPval-AA Elo benchmark for expert tasks, Claude Sonnet 4.6 shows the best performance with 1633 points, while Gemini 3.1 Pro ranks significantly behind with 1317 points. For writing ADRs, technical specs, or documentation that needs to sound like a senior engineer wrote it — Claude still has the edge.
Chart and table extraction: The Vertex AI documentation calls this out explicitly: for information-dense or complicated graphs, tables, or charts, the model can sometimes incorrectly extract information or misinterpret provided resources. We hit this when feeding financial reports with nested pivot tables. The model confidently gave wrong numbers — and confidently is the dangerous part.
Preview status latency: On launch day, Simon Willison reported response times over 100 seconds and frequent capacity errors. A few days in, it's stabilized, but as a preview model, production SLAs aren't guaranteed yet. Don't build a customer-facing pipeline on it until GA.
Guess-first behavior: The Google Cloud documentation notes that because the model is designed to prioritize being helpful, it may occasionally guess when information is missing rather than flagging uncertainty. In testing, we saw this on partial stack traces — it would generate a plausible-looking fix for code it hadn't fully seen.
Who Should Use Gemini 3.1 Pro — and Who Shouldn't

Use it if:
You need to reason over massive codebases or document sets in a single context. The 1M token window at this price point ($2/1M input tokens) has no real competitor. At less than half the price of Claude Opus 4.6 with very similar benchmark scores on most metrics, the reasoning-to-dollar ratio is hard to argue with.
You're building agentic workflows that involve research, synthesis, or multi-step planning — the ARC-AGI-2 jump is not just a benchmark win, it shows up in complex planning tasks.
You work with multimodal inputs (diagrams, screenshots, audio) alongside code. This is genuinely native, not bolted on.
Skip it (for now) if:
Your agentic workflows rely heavily on terminal execution or complex CI/CD interactions. GPT-5.3-Codex is still ahead here.
You need production reliability right now. Preview is preview.
Your primary output is nuanced technical writing or expert-level documentation. Claude Opus 4.6 and Sonnet 4.6 write better prose, full stop.
Frequently Asked Questions
Is Gemini 3.1 Pro generally available? Not yet. As of February 2026, it's in preview. Google is releasing 3.1 Pro in preview to validate updates and continue to make further advancements in areas such as ambitious agentic workflows before making it generally available.
What does Gemini 3.1 Pro cost? It's priced the same as Gemini 3 Pro: $2/million input tokens, $12/million output tokens under 200,000 tokens, with $4/$18 for the 200K–1M input token range.
How does Gemini 3.1 Pro compare to Verdent's model routing? Verdent integrates multiple frontier models and routes tasks to the best fit. For large-context repo analysis and cross-file reasoning tasks, Gemini 3.1 Pro is now a strong candidate in that routing decision. For tasks requiring tight agentic execution loops with terminal commands, we still prefer other models. See how Verdent's multi-model routing handles this automatically.
What's the knowledge cutoff? January 2025, per the official Google AI developer documentation.
Can I use it in VS Code or JetBrains? Developers can access Gemini 3.1 Pro in preview in the Gemini API via AI Studio, Vertex AI, Gemini Enterprise, Gemini CLI, and Android Studio. Direct IDE plugins are available via these API integrations.
What's the thinking_level** parameter and which should I use?** It controls how much internal reasoning happens before the model responds. Low = fast and cheap, Medium = balanced (our default recommendation for engineering tasks), High = deepest reasoning, most expensive. The new Medium level in 3.1 Pro is roughly equivalent to the old High level in 3 Pro.
Last Updated & Sources
Last updated: February 22, 2026
Primary sources:
- Google DeepMind official announcement — February 19, 2026
- Google DeepMind Model Card — Gemini 3.1 Pro — February 2026 benchmark results
- Vertex AI Documentation — Gemini 3.1 Pro — Last updated February 20, 2026
- DataCamp benchmark analysis — February 2026 hands-on testing
- VentureBeat coverage — Databricks, Cartwheel, Hostinger real-world results
