
When a coding agent lets you swap between dozens of models across half a dozen providers, something has to know what each model can do — does it call tools, how much context does it hold, who serves it and at what price. OpenCode answered that need by building Models.dev, an open-source model database, and using it internally. That relationship is a useful lens on a broader truth: an agent that's model-agnostic needs a reliable metadata layer underneath, or "pick any model" becomes "pick any model and hope it works." This is about why that layer matters for OpenCode-style tools, and what it can and can't decide for you.
Project relationships and data described here reflect Models.dev's and OpenCode's public materials as of June 2026; both are actively developed, so confirm the current behavior against the official Models.dev repository and OpenCode's documentation before relying on specifics.
Why OpenCode Needs a Model Metadata Layer
OpenCode is built to work across many models and providers rather than locking you to one. That flexibility is the feature — but it creates a problem: the moment you support many models, you need structured facts about all of them to make the flexibility usable. Without a metadata layer, "use any model" puts the burden on the user to know, for every candidate, whether it supports tool calling, what its context limit is, which providers serve it, and what it costs — facts scattered across provider docs in inconsistent formats.
A metadata layer solves this by giving the tool (and the user) one consistent source for those facts. Models.dev is that layer for OpenCode: the project's documentation states it's used internally in OpenCode, and OpenCode references the provider and model names defined there. So the metadata isn't a nice-to-have bolted on — it's the substrate that makes a model-agnostic agent practical. When you configure a model in OpenCode by its provider/model identifier, those built-in names come from the Models.dev catalog. The lesson generalizes: any coding tool that aims to be model-flexible needs a reliable metadata foundation, because flexibility without structured facts is just unmanaged complexity.
How Models.dev Fits OpenCode-Style Model Selection
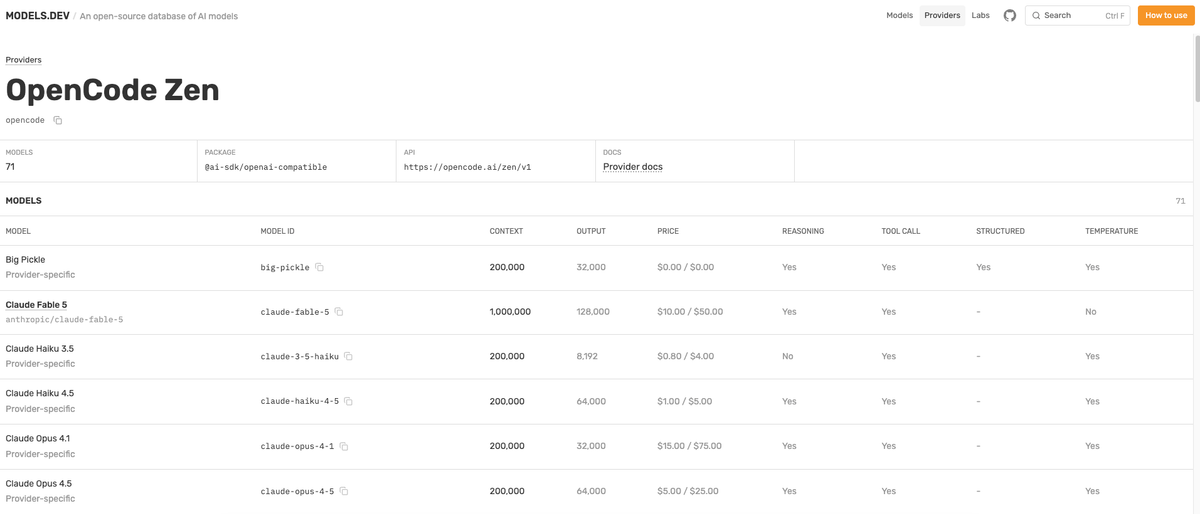
The reason a database fits this job is that model selection in a model-agnostic tool is a metadata problem at its core. When you choose or switch a model, the decisions that matter are answerable from structured facts: does this model do what my agent needs (tool calling), does it fit my task (context), can I reach it (provider availability), can I afford it (pricing). Models.dev organizes exactly these facts in a way a tool can consume — accessible through JSON endpoints (api.json, models.json, catalog.json) and stored as structured data.
A structural detail makes it especially suited to multi-provider tools: Models.dev separates facts about a model itself from facts about how a specific provider serves it. A model's inherent capabilities (does it call tools, its knowledge cutoff) are recorded once, while provider-specific serving details (pricing, context limits as served) are recorded per provider, with provider records able to inherit the shared model facts via a base_model reference and override only what differs. For an OpenCode-style tool that lets the same model be reached through different providers, this separation is what lets it present "the model" and "where you run it" as distinct, accurate choices rather than conflating them. The metadata structure mirrors the real decision: which model, and through which provider.
Decisions Metadata Can Support
Metadata can drive a specific class of decisions — the requirement-checking ones — while leaving the quality judgments to testing. Here's where it earns its place in an OpenCode-style workflow.
Choosing a model for tool-heavy agent work
For agent work, the first decision metadata supports is eligibility: can this model even drive an agent loop? Tool calling support is the gating fact — an agent that needs to run commands, edit files, and act on results requires a model that can call tools, and metadata tells you that before you waste time trying. For tool-heavy workflows, you can use the metadata to filter to models that support the agentic capabilities your loop depends on, turning "which of these many models can actually run my agent" into a filter rather than a trial-and-error search. The metadata makes the hard requirement checkable upfront.
Avoiding provider-specific blind spots
The second decision metadata supports is provider-aware: the same model can behave differently depending on who serves it. Because Models.dev records serving details per provider, it surfaces the blind spots a model-only view would hide — a provider that serves a model with a smaller context limit than the model's native maximum, different pricing, or different availability. For a tool that can route a model through multiple providers, this prevents the mistake of assuming "the model" has fixed properties when the provider you're routing through actually determines some of them. Reading the provider-specific facts, not just the model's headline specs, is how you avoid being surprised by a limit or price that's specific to where you're running it.
Knowing when metadata is not enough
The third thing metadata supports is, paradoxically, knowing its own boundary. Metadata answers what a model is — its capabilities, limits, pricing, providers — which is enough to determine eligibility but not enough to determine quality. Whether a tool-calling-capable model actually calls tools reliably on your tasks, whether its code is good, whether it handles your domain well: none of that is in the metadata, and metadata's value includes making clear where it stops. Using it well means treating it as the filter that narrows candidates to the eligible ones, then recognizing that the choice among eligible candidates is a testing question, not a metadata one. Knowing where the data runs out is part of using it correctly.
What OpenCode Users Should Still Verify
Because the metadata layer makes model-switching easy, OpenCode users should verify the things easy switching can obscure. First, freshness: model metadata changes (pricing shifts, new models launch, serving details update), and a community-maintained database can lag reality, especially for just-released models — so confirm fast-changing facts against the provider's own source before depending on them. Second, the provider-specific reality of whatever you're routing through: the limit or price you'll actually get depends on your provider, so verify it on the provider you'll use rather than the model's general entry.
Third, and most important for an easy-switching tool: actual performance on your work. The metadata tells you a model is eligible; only running it on your real tasks tells you it's good. The ease of swapping models in OpenCode is a strength, but it can tempt you to choose by specs alone — and specs don't capture how a model performs on your codebase. Treat the metadata as the entry criterion and your own testing as the decision, especially since the friction of switching is low enough that the discipline has to come from you, not from the cost of changing.

Limits, Risks, and Benchmark Gaps
The clearest limit is the gap between metadata and performance. A database of specifications can tell you what models can do in principle; it cannot tell you how well they do it on your code, and it deliberately doesn't try — it's not a benchmark or a ranking. So the risk is treating eligibility as sufficiency: assuming that because a model has the right specs, it's the right choice. It might be eligible and still underperform on your tasks, and no metadata field will warn you.
The benchmark gap is related. Metadata records capabilities and limits, not measured performance, so it won't tell you which eligible model is most capable — that requires evaluation on representative tasks, and the result is specific to your work rather than universal. There's also the maintenance risk inherent to any community-contributed dataset: coverage and accuracy depend on contributors, so freshness varies and specific values warrant verification. None of this makes the metadata less useful for what it's for — it makes clear that its job is narrowing the field by hard requirements, after which the performance question remains yours to answer through testing. The metadata is the start of the decision, not the end.
FAQ
Does OpenCode use Models.dev internally?
According to the project's public materials, yes — Models.dev's documentation states it's used internally in OpenCode, and the two share an origin (Models.dev was created by the OpenCode team). In practice, OpenCode references the provider and model identifiers defined in Models.dev, so the model and provider names you configure in OpenCode trace back to that catalog. That said, the exact nature and extent of the internal use is a project detail that can evolve, so for current specifics, check the official repositories and documentation rather than treating the relationship as fixed. The accurate framing is that Models.dev provides model metadata that OpenCode draws on, not that one is rigidly welded to the other.
Can Models.dev decide which model OpenCode should run?
No — Models.dev provides the facts, not the decision. It's a metadata database that tells you what each model is (capabilities, limits, pricing, providers), which lets you or a tool determine which models meet a set of requirements. But it doesn't select a model for you, automatically route between models, or rank models as "best." Choosing which model to run is a decision you make using the metadata as input, combined with your requirements and — for the quality question — your own testing. Treating Models.dev as an automatic decision system would overstate what it is; it's a structured source of facts that informs selection, while the selection itself (and any routing logic in a tool) is a separate layer that consumes those facts.
What model facts still require hands-on testing?
Everything about quality and reliability on your actual work. Metadata tells you a model supports tool calling; testing tells you whether it calls tools reliably and correctly on your tasks. Metadata tells you the context limit; testing tells you whether the model actually reasons well across a large context or degrades. Metadata gives you pricing; testing reveals the real cost per completed task once you account for how many attempts and corrections a model needs on your work. In short, metadata covers the checkable specifications, while the performance characteristics — code quality, tool-use reliability, behavior on your domain and conventions, effective cost — only emerge when you run the model on representative tasks. The specs filter the candidates; hands-on testing decides among them.
How should teams avoid switching models too often?
The risk of easy model-switching is that constant changes make evaluation unreliable — you never gather enough experience with any one model to judge it, and you can't attribute outcomes cleanly when the model keeps changing. To avoid that, set a deliberate evaluation period: when you adopt a model for a kind of work, commit to it long enough to build a real signal across enough real tasks before reconsidering, rather than swapping on impulse or each new release. Change the model on evidence — a measured problem with the current choice, or a tested improvement from a candidate — not on novelty. The metadata makes switching technically trivial, which is exactly why the discipline to not switch reflexively has to be deliberate; otherwise the low friction quietly undermines your ability to evaluate any model.
Conclusion
The Models.dev–OpenCode relationship illustrates a general principle: a model-agnostic coding tool needs a reliable metadata layer, or its flexibility becomes a burden rather than a feature. Models.dev provides that layer — structured, provider-aware facts about model capabilities, limits, pricing, and availability — and OpenCode draws on it to make model selection a matter of checkable requirements rather than guesswork. The right way to use this is to let metadata do what it's good at: filtering models by hard requirements (tool calling, context, provider, cost), surfacing provider-specific details a model-only view would miss, and making clear where its data ends. Then carry the decision past where metadata stops — because eligibility isn't quality, and only testing on your own tasks tells you which eligible model is actually right. And because the metadata makes switching easy, bring the discipline to switch deliberately, so easy changes don't undermine your ability to evaluate. Used that way, the metadata layer turns model-agnostic flexibility into a manageable, evidence-driven decision.
Related Reading
