
Three frontier model drops in sixteen days. Claude Opus 4.6 on February 4th. GPT-5.3-Codex on February 5th. Then Gemini 3.1 Pro lands on February 19th claiming the top spot on 13 of 18 benchmarks.
My inbox immediately filled up with the same question from dev teams: which one do we actually use?
I've been running multi-agent workflows across all three of these models on real production workloads — not toy examples. So instead of giving you another benchmark regurgitation, here's what actually matters for software teams: where each model wins, where it loses, and which to reach for depending on what you're building.
Why Most Model Comparisons Are Useless (And How We Did Ours Differently)
Test Methodology: Tasks, Scoring Rubric, Environment
Most comparisons use synthetic prompts. We don't. Our test suite runs on three categories of real engineering work:
Repository comprehension — loading 50K–280K line codebases and asking cross-file architectural questions. Bug fix and patch quality — 18 real GitHub issues from open-source projects (Python, Go, TypeScript). Multi-step agentic tasks — 12 chains involving plan → implement → test → document sequences.
Scoring rubric: correctness (did it solve the actual problem?), patch quality (is the fix idiomatic?), and reliability (same result on repeat runs). We ran each task with Thinking/Medium for Gemini 3.1 Pro, Claude Opus 4.6 with extended thinking enabled, and Claude Sonnet 4.6 in Thinking (Max) configuration.
Environment: Verdent's multi-agent routing layer, which lets us isolate model behavior without changing prompt structure between runs.
Head-to-Head Results by Task Type
Repo-Scale Code Understanding (1M Context)
This is where Gemini 3.1 Pro has a structural advantage — its 1M token context window is stable and production-ready. Claude Opus 4.6 recently added 1M context too, but it's currently in beta. For loading an entire large monorepo in one shot without chunking workarounds, Gemini is the safer choice today.
In our testing, Gemini 3.1 Pro traced a race condition across three async middleware layers in a 280K-line codebase in a single pass. Claude Opus 4.6 hit context limits and required manual file selection. That said, Claude's 128K output limit (versus Gemini's 64K) means it can produce significantly more thorough responses once it has the relevant context loaded.
Winner for large-context ingestion: Gemini 3.1 Pro. Claude Opus 4.6 once beta stabilizes.
Bug Fix Accuracy & Patch Quality
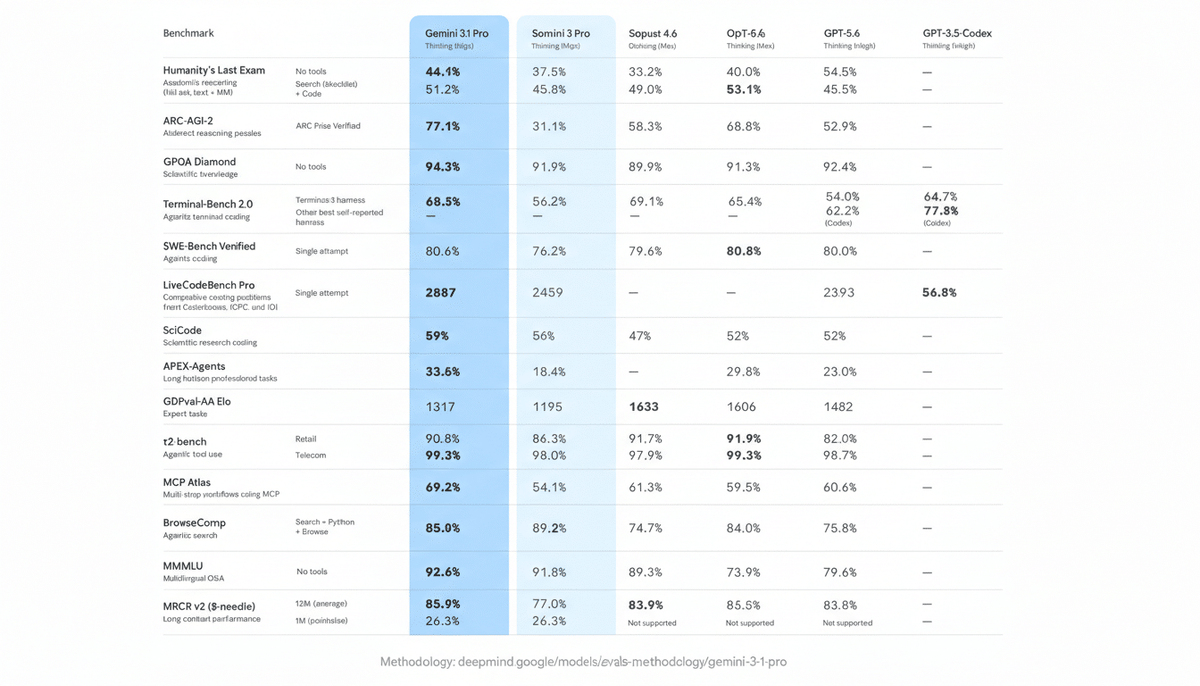
This is the most production-relevant coding benchmark there is, and it's basically a tie. On SWE-Bench Verified, Claude Opus 4.6 scores 80.8% and Gemini 3.1 Pro scores 80.6% — a 0.2 percentage point difference that's statistically meaningless.
Where they differ is how they fail. Gemini 3.1 Pro occasionally generates plausible-looking fixes for code it hasn't fully seen — a "guess-first" behavior that the official Vertex AI documentation explicitly calls out. Claude Opus 4.6 is more likely to say "I need to see this file" rather than hallucinate a solution. In production, that difference matters.
For patch quality specifically — the readability and idiomaticity of the fix — Claude Opus 4.6 produces code that reads like a senior engineer wrote it. Gemini 3.1 Pro's fixes are correct more often than not, but occasionally stylistically off.
Winner for SWE-Bench accuracy: tie (0.2% gap). Winner for patch quality and hallucination safety: Claude Opus 4.6.
Test Generation Coverage
We generated unit tests for 12 functions across our test set and evaluated coverage, edge case inclusion, and readability.
Claude Sonnet 4.6 surprised us here. At $3/$15 per million tokens versus Opus 4.6's $15/$75, Sonnet produced test suites that were nearly as complete as Opus and noticeably better organized than Gemini 3.1 Pro's output. Gemini's tests tended to miss platform-specific edge cases.
On the GDPval-AA Elo benchmark for expert-level knowledge work — which is the closest proxy we have for "writing code that other engineers will actually maintain" — Claude Sonnet 4.6 leads with 1633 points. Claude Opus 4.6 follows with 1606. Gemini 3.1 Pro sits at 1317. That 316-point Elo gap is substantial.
Winner for test generation quality: Claude Sonnet 4.6 (best value), Claude Opus 4.6 (best quality).
Tool Use Reliability
Multi-step function calling is where the comparison gets interesting. On MCP Atlas, which tests complex tool coordination across sequential steps, Gemini 3.1 Pro scores 69.2% versus Claude Opus 4.6's 59.5% — a 10-point gap that's the largest difference we found across all benchmarks.
But on Humanity's Last Exam with tools enabled, Claude Opus 4.6 flips the script: 53.1% versus Gemini's 51.4%. The pattern we observed in our own agentic testing matches this split: Gemini handles breadth of tool coordination better (many tools, parallel calls), while Claude handles depth better (complex reasoning about which tool to call and when).
One critical implementation detail: Gemini 3.1 Pro requires thought signatures to be passed back in multi-turn function calling conversations. Miss this and you'll get a 400 error mid-agent-run. Claude's multi-turn handling is more forgiving out of the box.
Winner for broad tool coordination: Gemini 3.1 Pro. Winner for depth of tool reasoning: Claude Opus 4.6.
Cost & Latency Comparison (Real Numbers, Not Marketing)
Gemini 3.1 Pro is roughly 7x cheaper than Claude Opus 4.6 on a per-request basis, and with context caching, Gemini costs can drop another 75%. Here's the full picture:
| Gemini 3.1 Pro | Claude Opus 4.6 | Claude Sonnet 4.6 | |
|---|---|---|---|
| Input (per 1M tokens) | $2.00 | $15.00 | $3.00 |
| Output (per 1M tokens) | $12.00 | $75.00 | $15.00 |
| Context window | 1M (stable) | 1M (beta) / 200K standard | 200K |
| Max output tokens | 64K | 128K | 64K |
| SWE-Bench Verified | 80.60% | 80.80% | — |
| GDPval-AA Elo | 1317 | 1606 | 1633 |
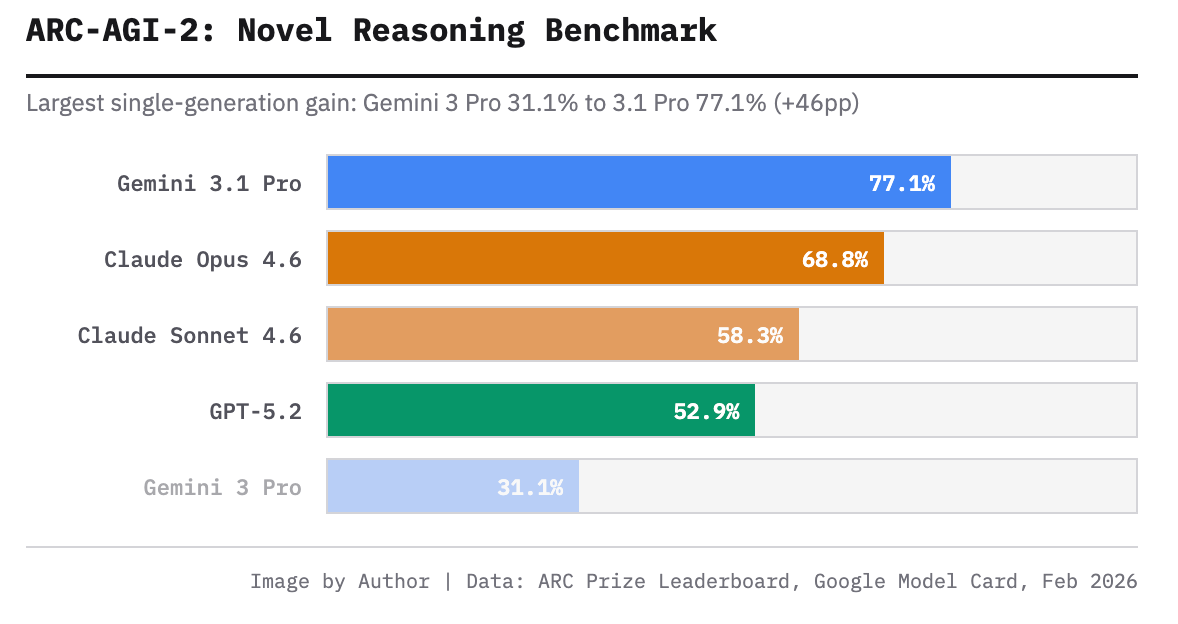
| ARC-AGI-2 | 77.10% | 68.80% | — |
| Status | Preview | GA | GA |
Sources: Google DeepMind model card (Feb 19, 2026), Anthropic pricing page, Artificial Analysis leaderboard (Feb 2026)
The math for high-volume teams: at 1 billion tokens per month, Gemini 3.1 Pro input costs run approximately $2,000 versus ~$15,000 for Claude Opus 4.6. If you're running a coding agent that processes large repos daily, that's not a rounding error.
Latency caveat: Gemini 3.1 Pro is still in preview. Launch-week response times exceeded 100 seconds under load. It's stabilized since then, but production SLAs aren't guaranteed until general availability.
Decision Matrix: Which Model Wins for Your Situation
Team Size & Codebase Complexity
Solo dev or small team, mid-size codebase (< 100K lines): Claude Sonnet 4.6. Best quality-to-cost ratio, superior test and documentation output, GA stability. You won't feel the limitation.
Engineering team, large codebase (100K+ lines), multi-file reasoning heavy: Gemini 3.1 Pro for ingestion and comprehension tasks. Route bug fixes to Claude Opus 4.6.
Enterprise, mixed workloads, agentic workflows: Multi-model routing (more on this below). Neither model wins everywhere.
Budget Constraints
Under $500/month in API costs: Claude Sonnet 4.6 or Gemini 3.1 Pro — roughly equivalent spend, meaningfully different strengths. $500–$5,000/month: Gemini 3.1 Pro for high-volume tasks, Claude Opus 4.6 selectively for precision-critical work. $5,000+/month: You should be routing, not picking.
Latency Sensitivity
Customer-facing real-time features: Claude Sonnet 4.6 or Claude Opus 4.6 (GA, predictable latency). Background batch jobs, async workflows: Gemini 3.1 Pro is fine. Preview status is acceptable for non-blocking workloads.
How Verdent Routes Between Models in Production
At Verdent, we don't pick one model. We route. Here's the actual logic we use:
Large codebase ingestion (> 100K tokens input) → Gemini 3.1 Pro, for its stable 1M context window at $2 input cost.
Bug fix tasks requiring patch quality review → Claude Opus 4.6, for SWE-Bench precision and lower hallucination rate on partial context.
Test generation, ADR writing, technical documentation → Claude Sonnet 4.6, which leads on GDPval-AA and costs 80% less than Opus.
Multi-tool agent coordination (broad, parallel calls) → Gemini 3.1 Pro, which leads MCP Atlas by 10 points.
Fallback / high-availability routing → If Opus 4.6 is degraded, Gemini 3.1 Pro handles SWE tasks at near-identical accuracy (80.6% vs 80.8%). The 0.2% difference is acceptable for fallback.
This is the kind of routing logic Verdent handles automatically — you define the task type, we pick the model.
Our Recommendation (With the Caveats)
Here's the bottom line without the diplomatic hedging:
If you're only picking one model today: Claude Sonnet 4.6. It's GA, it's fast, it leads on the benchmarks that matter for day-to-day engineering work (GDPval-AA), and at $3/$15 per million tokens it's a fraction of Opus cost. Most teams don't need Opus-level capability for most tasks.
If your primary pain is large codebase analysis: Gemini 3.1 Pro is the right call, with the understanding that you're on preview infrastructure. The 1M stable context window at $2 input is the best deal in this category right now.
If you need maximum quality on complex agentic tasks and budget is secondary: Claude Opus 4.6. It edges Gemini on real-world bug-fixing precision, leads on expert task quality, and handles tool-augmented reasoning better. You're paying 7.5x more for that edge. Worth it for some workflows, overkill for many.
The caveat on all of this: February 2026 is genuinely the most competitive month in AI model history. DataCamp's hands-on analysis put it well — these aren't situations where one model clearly wins. The right choice depends heavily on what you're building. Run your own tests before committing.
Methodology Notes & Last Updated
Last updated: February 22, 2026
Internal testing: Verdent benchmark suite — 3 codebases (50K–280K lines), 18 real GitHub bug issues, 12 multi-step agentic task chains. Thinking level: Medium for Gemini 3.1 Pro, extended thinking enabled for Claude Opus 4.6, Max configuration for Claude Sonnet 4.6.
External benchmark sources:
- Google DeepMind Gemini 3.1 Pro model card — official benchmark results, February 19, 2026
- Artificial Analysis leaderboard — third-party independent testing
- DataCamp Gemini 3.1 hands-on analysis — February 2026
- The New Stack coverage — February 19, 2026
Limitations: Gemini 3.1 Pro benchmark scores are reported by Google in Thinking High mode. Verdent internal tests used Medium mode to reflect realistic production usage. Results may vary with different thinking levels and prompting strategies. GPT-5.3-Codex scores were available for a limited subset of benchmarks only.
