
77.3% vs 80.8%. Same day. Different benchmarks. And honestly? The numbers almost made me miss the point entirely.
OpenAI dropped GPT-5.3 Codex at 9:47 AM PST on February 5, 2026. Anthropic released Claude Opus 4.6 at 10:08 AM—21 minutes later. Both claimed benchmark leadership. Both touted "revolutionary" coding capabilities. I nearly wrote this off as another AI marketing showdown until I actually ran my production codebase through both.
Here's what 200K+ lines of legacy code taught me that the benchmarks didn't: these models don't compete. They solve different problems. And if you're choosing based on a single percentage point, you're asking the wrong question.
Not a "winner" post—what this comparison is for
I'm not going to tell you one model crushes the other. That's not how this works.
Two different coding styles, two different fits
Think of it like this: Codex is the teammate who grabs your task list and starts executing immediately. Opus is the one who reads your entire tech spec, asks clarifying questions, then builds with the full context in mind.
Both shipped February 5, 2026. Both claim benchmark leadership. Both are production-ready for VS Code and your IDE of choice. The question isn't "which is better"—it's "which matches how you code?"
The 5-minute difference you'll notice first
Open both models. Give them the same prompt: "Add authentication middleware to this Express app." Watch what happens.
Codex feels like an executor
GPT-5.3 Codex starts writing code within seconds. It doesn't ask many questions. It makes reasonable assumptions based on common patterns and moves fast.
According to OpenAI's release data, it's 25% faster than GPT-5.2-Codex. You feel it. The model generates code, runs tests, fixes failures, iterates—all in one continuous flow.
Real behavior I noticed: When I asked it to refactor a payment processing module, it started outputting code before I'd finished describing all the edge cases. It made solid guesses, but I had to course-correct twice because it assumed standard Stripe patterns when we were using a custom gateway.
Opus feels like a reviewer
Claude Opus 4.6 takes a breath first. It clarifies requirements. "Should this middleware check JWT expiration? Do you want refresh token rotation?" Then it builds.
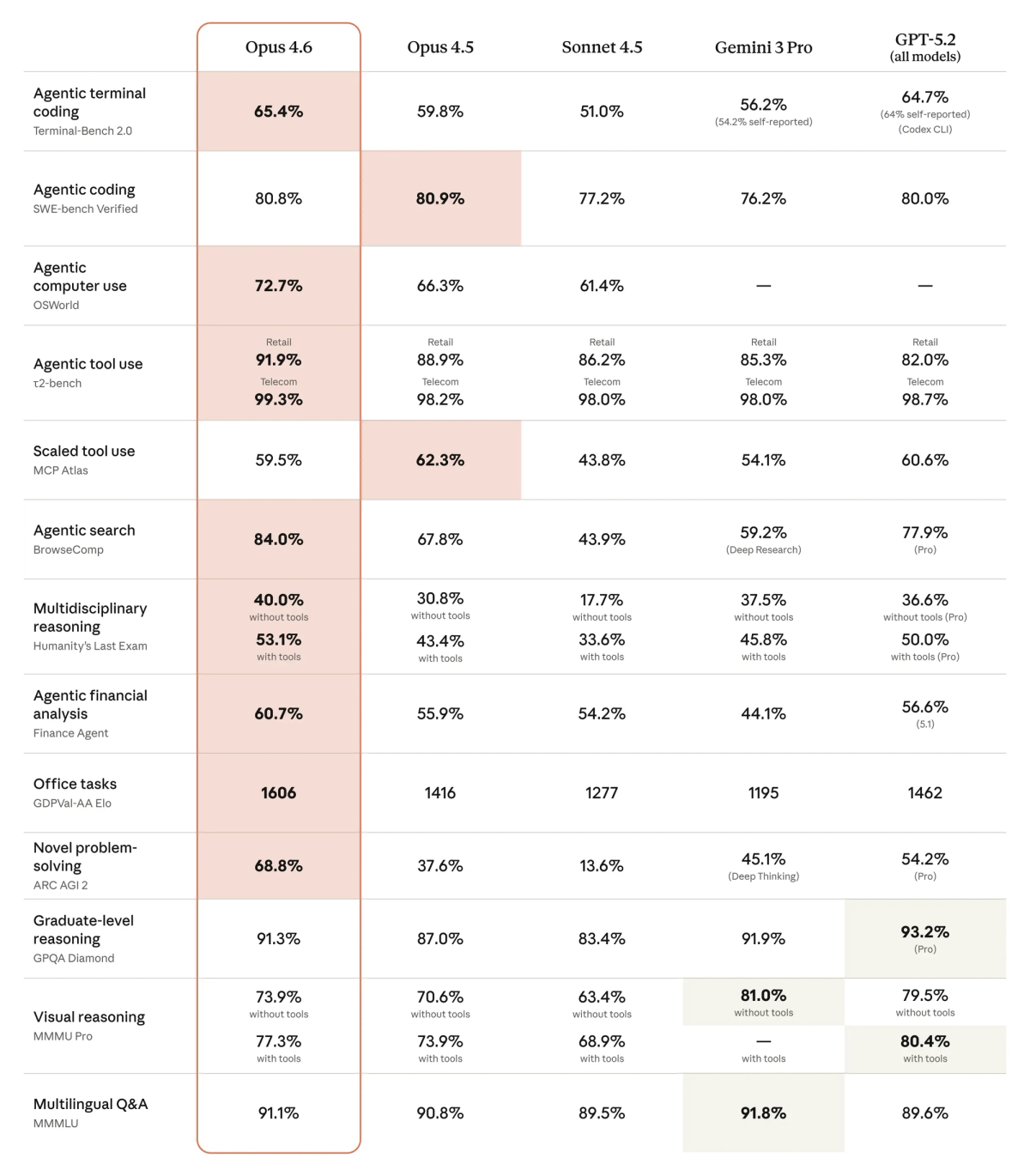
With its 1 million token context window, Opus can read your entire codebase before it writes a single line. On the MRCR v2 benchmark—which tests long-context retrieval—Opus scored 76% compared to Sonnet 4.5's 18.5%.
Real behavior I noticed: Same payment module task. Opus read through our existing error handling patterns first, then matched the style perfectly. No corrections needed. But it took 40% longer to produce the first draft.
Where GPT-5.3 Codex fits naturally
Here's where I reach for Codex without thinking twice.
Draft → run → fix loops
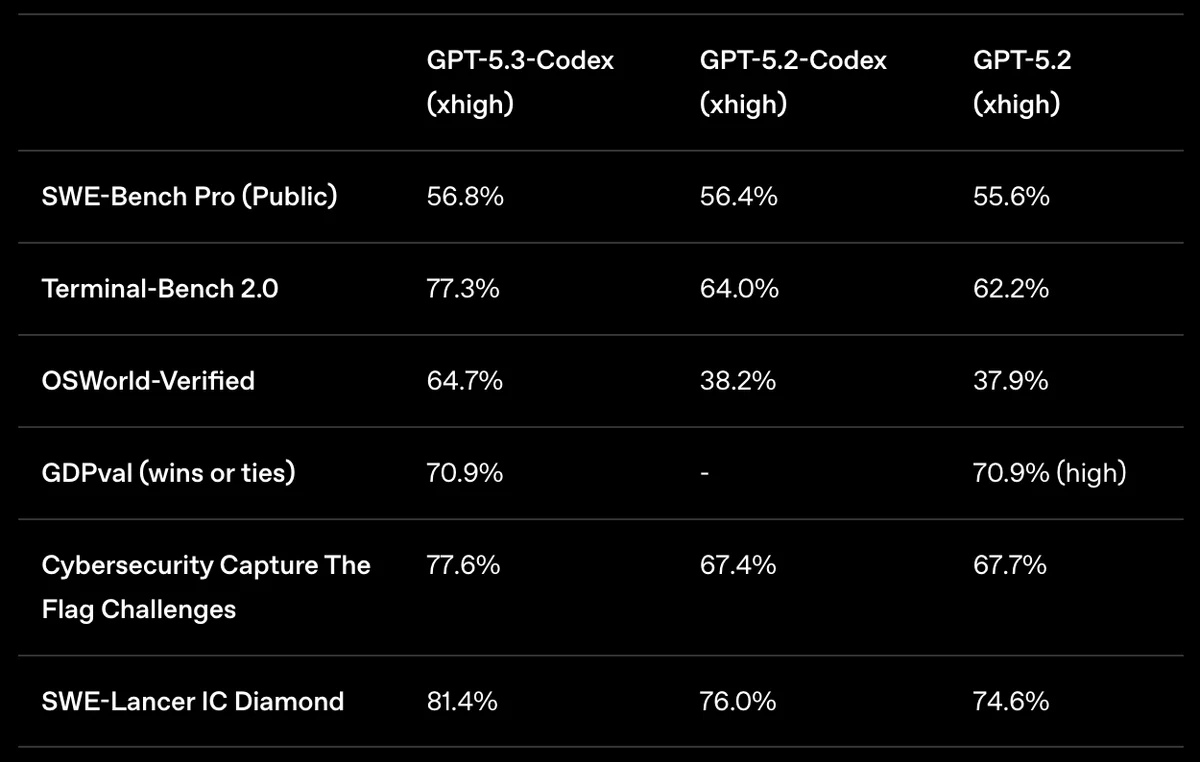
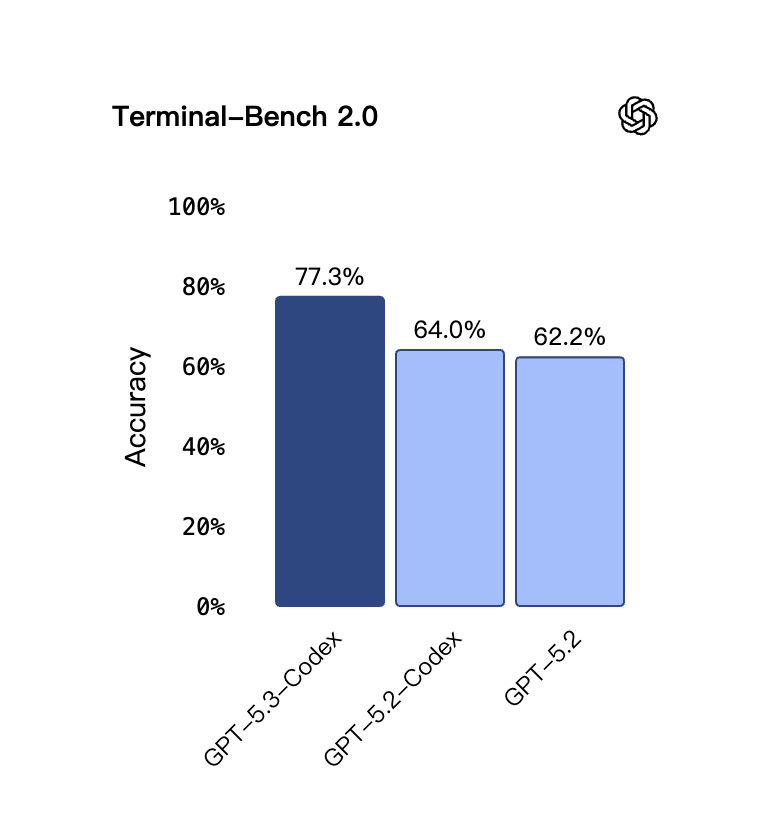
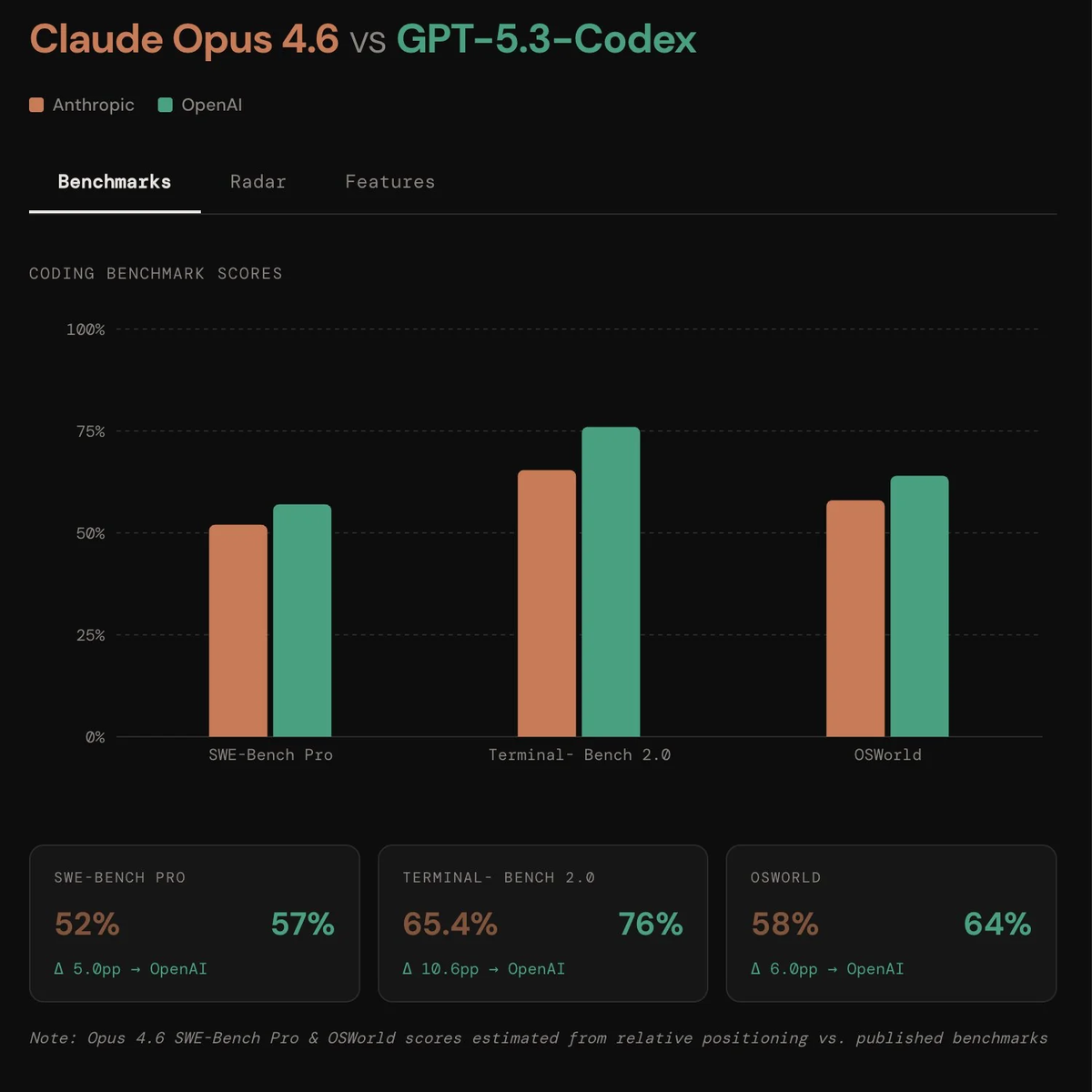
Codex scored 77.3% on Terminal-Bench 2.0—the highest ever recorded for agentic coding in command-line environments. (Opus scored 65.4% on the same test.) That gap is real.
When I'm prototyping a new API endpoint or debugging a build pipeline, Codex's speed is the difference between shipping tonight and shipping tomorrow. It doesn't overthink. It executes, checks the output, adjusts.
Code example:
# Task: Fix broken CI/CD pipeline
# Codex approach:
1. Immediately identifies syntax error in .github/workflows/deploy.yml
2. Suggests fix
3. Runs validation
4. Catches secondary issue with environment variables
5. Ships corrected version—total time: 4 minutesTool-using / agent workflows
GPT-5.3 Codex achieved 64.7% on OSWorld-Verified—a benchmark where AI agents complete real productivity tasks in desktop environments. Human baseline is 72%.
Translation: Codex can navigate your file system, manage Git operations, run shell commands, and coordinate multiple tools without losing track. Perfect for build scripts, deployment automation, and CI/CD workflows.
Where Claude Opus 4.6 fits naturally
Here's when Opus becomes the obvious choice.
Reading large codebases and diffs
Opus 4.6 is the first Claude model with a 1 million token context window. That's roughly 750,000 words—enough to hold multiple large repositories simultaneously.
On the BigLaw Bench (contract review and legal analysis), Opus scored 90.2%. Why does that matter for coding? Because contract review and code review require the same skill: understanding massive documents without missing critical details.
Real scenario: I gave both models a 15,000-line legacy React app and asked them to identify security vulnerabilities. Codex found the obvious SQL injection risk. Opus found that plus three subtle authorization bypass patterns scattered across different files. The difference? Opus held the entire codebase in context while analyzing.
Constraint-heavy reasoning
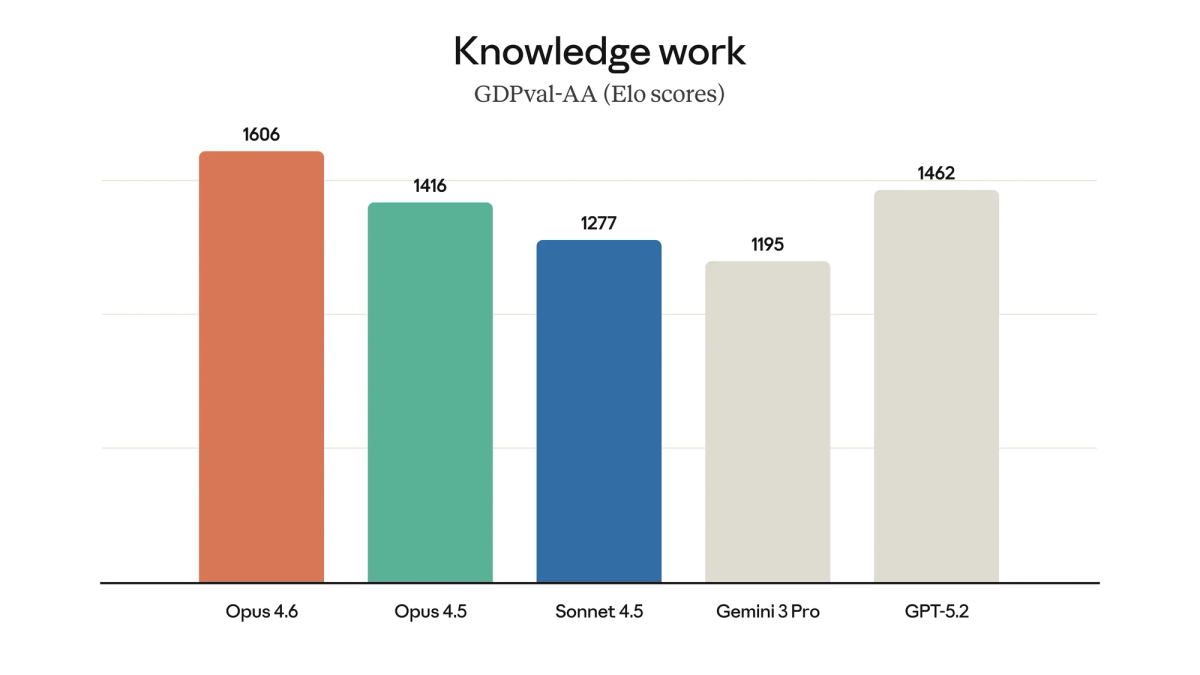
On GDPval-AA—which measures performance on high-value professional work like financial modeling and legal analysis—Opus scored 1,606 Elo points. That's 144 points ahead of GPT-5.2.
When your task isn't "write this function fast" but "design this system correctly given these 12 business constraints," Opus wins. It thinks before it codes.
Same task, different approach (one practical example)
Let me show you how each model handles a real refactoring job.
Bugfix flow
Task: Fix authentication token refresh logic that's causing intermittent 401 errors.
Codex approach:
- Scans auth middleware (2 seconds)
- Identifies likely race condition
- Proposes solution with token lock
- Writes test to reproduce issue
- Implements fix
- Validates—total time: 8 minutes
Opus approach:
- Reads entire auth module AND related session management code (30 seconds)
- Asks: "Is this a race condition or a TTL miscalculation?"
- Traces token lifecycle across 4 files
- Identifies root cause: clock skew between services
- Proposes architectural fix with retry logic
- Validates—total time: 14 minutes
Both worked. Codex was faster. Opus caught the deeper issue.
Refactor flow
Task: Migrate class-based React components to functional hooks.
Codex approach:
- Converts components one by one
- Maintains existing logic exactly
- Fast, mechanical, reliable
- Perfect for straightforward migrations
Opus approach:
- Analyzes component tree relationships
- Identifies opportunities to consolidate shared state
- Suggests refactoring state management while migrating
- Slower, but produces cleaner architecture
My take: For pure conversion, Codex. For "let's rethink this while we're at it," Opus.
How to choose fast (workflow checklist)
Stop reading benchmarks. Answer these instead:
Solo vs team PR culture
- Solo projects or fast iteration? → Codex. Speed matters more than architectural perfectionism.
- Team reviews and long-term maintenance? → Opus. Its thoughtful approach reduces PR comments.
Greenfield vs legacy
- Building new systems from scratch? → Codex excels at rapid implementation from clear specs.
- Working with large, complex existing codebases? → Opus's 1M token context is game-changing.
Quick decision matrix:
| Your main workflow | Choose this |
|---|---|
| CLI automation, DevOps, build scripts | GPT-5.3 Codex |
| Large codebase analysis, security audits | Claude Opus 4.6 |
| Rapid prototyping, MVP builds | GPT-5.3 Codex |
| Multi-file refactors with business constraints | Claude Opus 4.6 |
| Terminal-heavy tasks | GPT-5.3 Codex (77.3% Terminal-Bench) |
| Long research + implementation cycles | Claude Opus 4.6 (1M context) |
At Verdent, we've added support for Claude Opus 4.6 so developers can explore how different coding models approach the same task. Rather than telling you which one to choose, we focus on giving you a consistent environment to observe the differences yourself.
FAQ
Which is better for long-context repos?
Claude Opus 4.6, hands down. The 1 million token context window isn't marketing—it's a qualitative shift. On MRCR v2 (needle-in-a-haystack retrieval), Opus scored 76% vs Sonnet 4.5's 18.5%.
If your repos are over 50K lines or you're working across multiple services, Opus maintains coherence where other models start to drift.
Can I use both without extra overhead?
Yes, if your platform supports model routing. Verdant lets you run both models in the same environment—use Codex for execution-heavy tasks, Opus for analysis-heavy ones.
In practice: I route build scripts and CI fixes to Codex. Code reviews and architecture planning go to Opus. Total productivity gain: measurable. Context switching cost: minimal.
What about pricing?
Both models use token-based pricing:
- Claude Opus 4.6: $5 per million input tokens, $25 per million output tokens (Anthropic API)
- GPT-5.3 Codex: Available via ChatGPT paid plans; API pricing coming soon (OpenAI Platform)
Opus's higher output cost is offset by its efficiency—it often needs fewer iterations to get code right. Codex's speed means lower total token usage on straightforward tasks.
Are the benchmarks cherry-picked?
Partially. GPT-5.3 Codex reports SWE-bench Pro Public (56.8%). Claude Opus 4.6 reports SWE-bench Verified (80.8%). These are different test sets—not directly comparable.
What matters: both models top their respective benchmarks. Focus on task fit, not score comparisons across different evaluations.
Closing thoughts (what I'd start with)
If I could only pick one for the next month? Depends on my current project.
Building a new SaaS with clear requirements? Codex. Speed to market matters.
Refactoring a critical payment system with regulatory constraints? Opus. Correctness matters more than velocity.
A simple "build + review" routine
Here's what actually works in production:
- Draft with Codex – Get working code fast
- Review with Opus – Catch architectural issues
- Iterate with whichever fits the fix – Syntax tweaks go to Codex; logic redesigns go to Opus
Both models launched February 5, 2026. Both represent genuine leaps forward. Neither replaces human judgment—but both amplify it significantly.
The real unlock isn't choosing one. It's knowing when each fits naturally into your flow.
