
G0DM0D3 appeared on GitHub on March 25, 2026 under the account elder-plinius and accumulated over 3,000 stars within days. It's been discussed in AI safety circles, red-teaming communities, and on X — often under descriptors that focus on one aspect of what it does and miss the rest. This is a functional description of what it actually is.
What G0DM0D3 Actually Is
G0DM0D3 is an open-source, browser-based interface for running multiple AI models in parallel, evaluating their outputs, and manipulating input prompts using a suite of structured techniques. It's built for red-teaming, cross-model comparison, and AI safety research — not productivity chat or coding assistance. The official description from the elder-plinius/G0DM0D3 repository is "LIBERATED AI CHAT" — framing that reflects its positioning as a tool for researchers and builders who want to probe model behavior rather than consume it passively.
Single index.html, No Install, No Login
The entire client application is a single index.html file. No npm install, no build step, no framework dependencies — you clone the repository and open the file directly in a browser, or serve it locally with a one-line Python command. There is no login system and no server-side storage. Your API key lives in localStorage, your chat history lives in localStorage, and nothing is sent to G0DM0D3's infrastructure. The consequence of this design is that clearing your browser data wipes your history. The tool includes an export/import function in settings, but the responsibility for backup sits with the user.
The codebase underneath is ~3,300 lines of TypeScript compiled into that single file, with an optional Node.js/Express API server in api/ for deployments that need server-side orchestration or programmatic access. The API.md documentation covers OpenAI-compatible endpoints including ultraplinian/fast, ultraplinian/standard, and ultraplinian/full — meaning G0DM0D3's multi-model racing engine can be called directly from existing OpenAI SDK integrations.
OpenRouter as the Model Gateway — What That Means in Practice
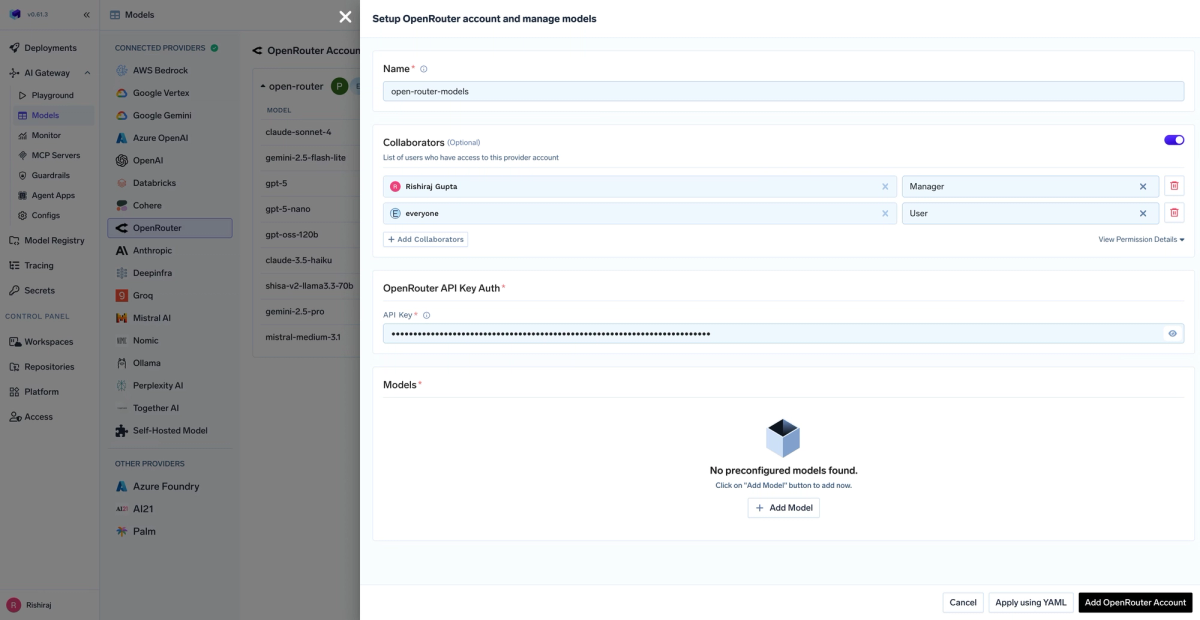
G0DM0D3 doesn't connect to Anthropic, OpenAI, or Google directly. It routes every model call through OpenRouter, a unified API gateway that aggregates access to 50+ models under a single API key and billing account. You register at OpenRouter, generate an API key, and paste it into G0DM0D3's settings. From that point, any model available on OpenRouter — Claude, GPT-5, Gemini 3 Pro, Grok, Mistral, LLaMA, DeepSeek, Qwen, and others — is accessible through G0DM0D3's interface.
The practical implication: costs are metered. Running GODMODE CLASSIC fires 5 parallel model calls. Running ULTRAPLINIAN at full scale fires up to 51. Those are real API calls at real per-token prices, aggregated on your OpenRouter account. G0DM0D3 itself charges nothing — it's MIT-licensed software — but inference costs accumulate with usage.
The Four Core Modes Explained
GODMODE CLASSIC — 5 Parallel Model+Prompt Combos, Best Response Wins
GODMODE CLASSIC runs five predefined combinations of model and system prompt in parallel, scores all responses, and surfaces the highest-ranked output. The "battle-tested combos" in the README refer to specific model and prompt pairings that the project has tuned for direct, substantive responses across a range of query types. It's less a quality-of-life feature and more a structured evaluation method: given the same question, different model and prompt combinations produce systematically different outputs, and this mode makes the variance visible and selectable.
From a research perspective, this is useful for establishing a baseline across model families — you can see in a single query whether Claude, GPT-5, Grok, and Mistral diverge or converge on a specific topic, and by how much. From a red-teaming perspective, it's a mechanism for observing whether identical prompts elicit different safety behaviors from different models.
ULTRAPLINIAN — 10–55 Model Comparative Evaluation with Composite Scoring
ULTRAPLINIAN scales GODMODE CLASSIC's approach across five tiers. The README specifies 10–55 models; the actual parallel race tops out at 51 models simultaneously. The tier structure lets you choose between a fast 10-model sweep and a full 51-model evaluation depending on query budget and latency tolerance.
Each response is scored on substance, directness, and completeness. The scoring function achieves what the PAPER.md describes as "strict quality-tier ordering with 82-point discrimination" — meaning the scoring reliably distinguishes between high and low quality responses across the model set, not just picks randomly. The winning response is surfaced with metadata showing which model produced it and its score relative to the field.
This is the mode that makes G0DM0D3 genuinely useful for model comparison research. Running 51 models against the same prompt in under 30 seconds produces a structured dataset about model behavior that would take hours to assemble manually.
Parseltongue — 33 Input Perturbation Techniques for Red-Teaming
Parseltongue is an input mutation engine. It applies structured transformations to prompts before they reach model safety classifiers — 33 techniques across three intensity tiers, including homoglyph substitution, Unicode perturbation, synonym swaps, and zero-width character insertion. These transformations can pass input-side safety filters while remaining legible to the underlying language model.
The PAPER.md documents a 100% trigger detection rate across 54 default test cases, meaning Parseltongue correctly identifies and transforms known trigger words. What that translates to in practice against any specific model's safety system varies and is explicitly not guaranteed by the project. The intended use case, as stated in the project documentation, is auditing and red-teaming — systematic testing of whether a model's input classifiers are robust to character-level perturbation. Whether a given deployment of Parseltongue constitutes legitimate safety research or misuse depends on context, intent, and applicable policy. The project documentation states this explicitly and notes that users are responsible for compliance with local law.
AutoTune — Context-Adaptive Sampling with EMA Learning
AutoTune classifies each conversation into one of five context types using 20 regex patterns, then selects an optimized sampling parameter profile across six dimensions: temperature, top_p, frequency penalty, presence penalty, and related parameters. A feedback loop adjusts these parameters based on binary thumbs-up/thumbs-down ratings from the user, using Exponential Moving Average learning with α=0.3.
This is documented in detail in PAPER.md and confirmed by the source: AutoTune achieves 84% classification accuracy across 150 labeled test messages, and the feedback loop converges to 29–62% parameter distance improvement within 19 ratings. The practical effect is that G0DM0D3 adapts its sampling configuration based on what you appear to be trying to do — creative generation, technical reasoning, research, and so on — and refines that configuration based on your feedback over time. AutoTune can be toggled off entirely if you prefer manual parameter control.
Who Actually Uses This and Why
Red Teamers Probing LLM Safety Boundaries
The project is explicitly positioned for AI safety research and red-teaming. Security researchers and AI safety evaluators use G0DM0D3 to systematically probe whether model safety behaviors are consistent across providers, whether input perturbation affects safety responses, and whether some models are more robust than others to specific prompt patterns. Running the same adversarial prompt through 51 models simultaneously produces a cross-provider safety behavior snapshot that is genuinely hard to replicate with manual testing.
Researchers Comparing Model Outputs at Scale
Model comparison is a legitimate research task: which model family handles technical reasoning better, which produces more diverse outputs, which is most consistent across paraphrases of the same question. ULTRAPLINIAN makes this tractable at query scale. A researcher evaluating 10 models against 50 test prompts manually would spend hours. With G0DM0D3, it's a session.
Developers Who Want Offline, Privacy-First Multi-Model Access
The single-file architecture means you can run G0DM0D3 fully offline after the initial download — with a locally served index.html and a local model via an OpenRouter-compatible endpoint. No data goes to G0DM0D3's servers. Developers building tools that need multi-model access and want to avoid vendor lock-in or cloud telemetry use this as a local evaluation environment.
What G0DM0D3 Is Not
Not a Coding Agent or IDE Plugin
G0DM0D3 has no IDE integration, no terminal interface, no file system access, and no ability to read or modify a codebase. It receives text input and returns text output. There is no concept of a repository, a project, a diff, or a pull request. The tool doesn't know what files you have, what language you're using, or what your architecture looks like.
No Persistent Memory, No Codebase Context
Within a session, G0DM0D3 maintains conversation history in the browser. Between sessions, nothing persists unless you manually export and reimport your history. There is no auto-memory system, no CLAUDE.md equivalent, no mechanism for the tool to build up understanding of your project over time.
How It Differs from Tools Like Cursor, Claude Code, or Verdent
The distinction is architectural, not qualitative. Cursor and Claude Code are purpose-built coding environments: they read your repository, understand file structure, run tests, execute shell commands, and maintain project context across sessions. Verdent runs multiple agents in isolated git worktrees simultaneously, coordinating parallel coding work.
G0DM0D3 answers a different question entirely: given a prompt, which model gives the best response? It's a model evaluation and comparison tool, not an autonomous agent. You might use G0DM0D3 to determine which underlying model performs best on a specific type of reasoning task, then use that model inside Claude Code or Verdent for the actual engineering work. They're not competitive alternatives — they sit at different layers of an AI workflow.
Limitations Worth Knowing Before You Run It
localStorage Only — Clear Browser = Lose Everything
This is the most operationally significant limitation. Chat history, settings, and API keys are stored in browser localStorage. Clearing browser data, switching browsers, opening a different browser profile, or running in incognito mode all mean starting fresh. The built-in export function produces a JSON file you can reimport, but this is manual. If you're using G0DM0D3 for longitudinal research, build the export habit immediately.
Requires Your Own OpenRouter API Key
There is no freemium tier or trial. You need an OpenRouter account and a funded API key before the tool does anything. OpenRouter's pricing is pass-through from the underlying model providers, so costs scale directly with usage. Running ULTRAPLINIAN at tier 5 (51 models) on a complex prompt can consume meaningful token volume across all 51 calls. Monitor your OpenRouter usage dashboard if you're running ULTRAPLINIAN extensively.
Multi-Model Calls Need Stable Internet and Can Be Costly
51 simultaneous API calls against 51 different model endpoints require stable, low-latency internet. Flaky connections cause partial results — some models respond, others time out, and the scoring runs on whatever comes back. The PAPER.md notes that the ULTRAPLINIAN scoring function handles partial results, but a degraded connection degrades result quality. Additionally, the tool currently lacks voice input/output — it's text only despite its responsive UI.
FAQ
Is G0DM0D3 Safe to Use?
"Safe" covers two different questions. Operationally: your API key stays in your browser, no personal data goes to G0DM0D3's servers, and the AGPL-3.0 license means the code is fully auditable. The project includes a SECURITY.md with a vulnerability disclosure process. On the use-case question: G0DM0D3 is a dual-use tool. It's built to probe safety boundaries, and some of its capabilities — particularly Parseltongue — are designed to bypass input-side safety classifiers. The project documentation is explicit that users are responsible for what they do with the tool and must comply with applicable law and model provider terms of service.
Does G0DM0D3 Work Without an API Key?
No. Every model call routes through OpenRouter, which requires an API key. The hosted version at godmod3.ai and the local version both require you to paste an OpenRouter key in settings before making any queries.
What's the Difference Between G0DM0D3 and ChatGPT?
ChatGPT is a consumer product built around a single model family (OpenAI's GPT series) with persistent memory, a managed subscription, and a UI designed for general productivity. G0DM0D3 is a research tool built around parallel evaluation of 50+ models with no persistent memory, BYOK economics, and a UI designed for red-teamers and researchers. The use case overlap is minimal.
Can I Use G0DM0D3 for Coding Tasks?
You can ask it coding questions and it will query multiple models for answers, surfacing the best response across the model set. That's useful for model comparison on coding benchmarks. What you can't do is give it a repository, ask it to make changes, run tests, or open a PR. For actual coding agent work, you need a tool with file system access and project context. G0DM0D3 is upstream of that — it helps you understand which models are worth using, not how to deploy them in an agent workflow.
Is GODMODE CLASSIC Actually a Jailbreak Tool?
GODMODE CLASSIC's prompt+model combos are tuned for direct, substantive responses and are explicitly documented as red-teaming methodology. Whether any specific use of the tool constitutes jailbreaking depends on what you're asking, which models you're using, and what those models' providers consider permissible. The project positions it as a safety evaluation tool — the same outputs that reveal model safety gaps to researchers are what adversaries would want to produce without the research framing. The code is open source and the methodology is documented; what users do with it is their responsibility.
Related Reading
- Claw Code: Claude Code, OpenClaw, and What Each Actually Does — Context on the OpenClaw ecosystem that G0DM0D3's Skills integrate with.
- GLM-5V-Turbo: Z.ai's Vision Coding Agent Explained — One of the model families accessible through OpenRouter that G0DM0D3 can evaluate.
- What Is Model Context Protocol? — The protocol layer that sits between agents and tool infrastructure, relevant to how G0DM0D3's API mode connects to broader workflows.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — The coding agent tools that G0DM0D3 is explicitly not — and how they complement each other.
- LLM Knowledge Base for Coding Agents: Beyond RAG — Once you've used G0DM0D3 to identify which model handles your tasks best, this is how to give that model persistent project context.
