
Search is a solved problem — until you try to use it inside an AI coding agent. The same model that can write a Redis implementation from memory will confidently cite deprecated API documentation, miss a library version that shipped two months ago, or claim a GitHub issue is unresolved when it was closed last week. This isn't a reasoning failure. It's a freshness failure. And it's pushing a new product category into the coding agent stack: dedicated search infrastructure that agents can call as a tool, not just as training data.
AnySearch, which launched on May 11, 2026, is the clearest current example of this category. This article uses it as a lens to explain what the search layer in agentic coding workflows actually needs to do — and where search, no matter how good, still can't replace verification.
Why AI Coding Agents Need Better Search

Coding agents fail when context is stale
Training data has a cutoff. A model trained through mid-2025 doesn't know about a framework's breaking change shipped in March 2026, a security advisory published last month, or a Stack Overflow answer updated to note that the accepted solution no longer works. When a coding agent acts on stale context, the failure mode is subtle: the code compiles, the tests pass in the agent's knowledge, but the dependency it's calling changed its interface six months ago.
The standard workaround is web search — give the agent a search tool and let it look things up. That works for general queries. For coding-specific context, the quality of search results matters significantly: documentation search, library reference, GitHub issue tracking, security advisory databases, and academic/technical references are different information surfaces with different retrieval requirements.
Search is becoming part of the agent workflow layer
The MCP ecosystem has made search infrastructure composable. An agent that needs to check the current React Router API doesn't need a custom integration — it calls a search tool exposed by an MCP server, gets structured results, and continues working. The search layer is becoming a reusable component rather than an ad-hoc prompt addition.
This shift matters for multi-agent coding workflows: when multiple parallel agents are working on different parts of a codebase, the search layer becomes shared infrastructure. Each agent that needs current documentation or GitHub context calls the same tool rather than doing its own web scraping or relying on potentially different model training cutoffs.
What AnySearch Is in This Context
API-first search infrastructure for agents
AnySearch launched in May 2026 with a stated design premise: much of the information most valuable to AI agents is not publicly searchable via standard web search. The product aggregates vertical data sources — finance, legal, academic research, cybersecurity, code repositories, and structured API services — and exposes them through a single API endpoint.

For coding workflows specifically, the relevant capabilities from their official documentation are:
- General Web Search — open-ended natural language queries
- Vertical Domain Search — structured queries across specific domains including code, academic, and security
- Parallel Batch Search — up to 5 independent queries in a single call
- URL Content Extraction — fetch and extract full page content as Markdown
The parallel batch search capability is directly relevant to multi-agent coding: an orchestrator agent can dispatch multiple search queries simultaneously rather than waiting for each query to return before issuing the next.
Anonymous access works without an API key at lower rate limits. API key access unlocks higher throughput. Verify current access tiers at the official documentation before building workflows that depend on specific rate limits.
SKILL, MCP, and API as different integration surfaces
AnySearch exposes the same search capability through three integration surfaces, which serve different use cases in coding workflows:
API — direct HTTP calls. Best for custom agents and orchestration systems where you control the full request pipeline and want maximum flexibility.
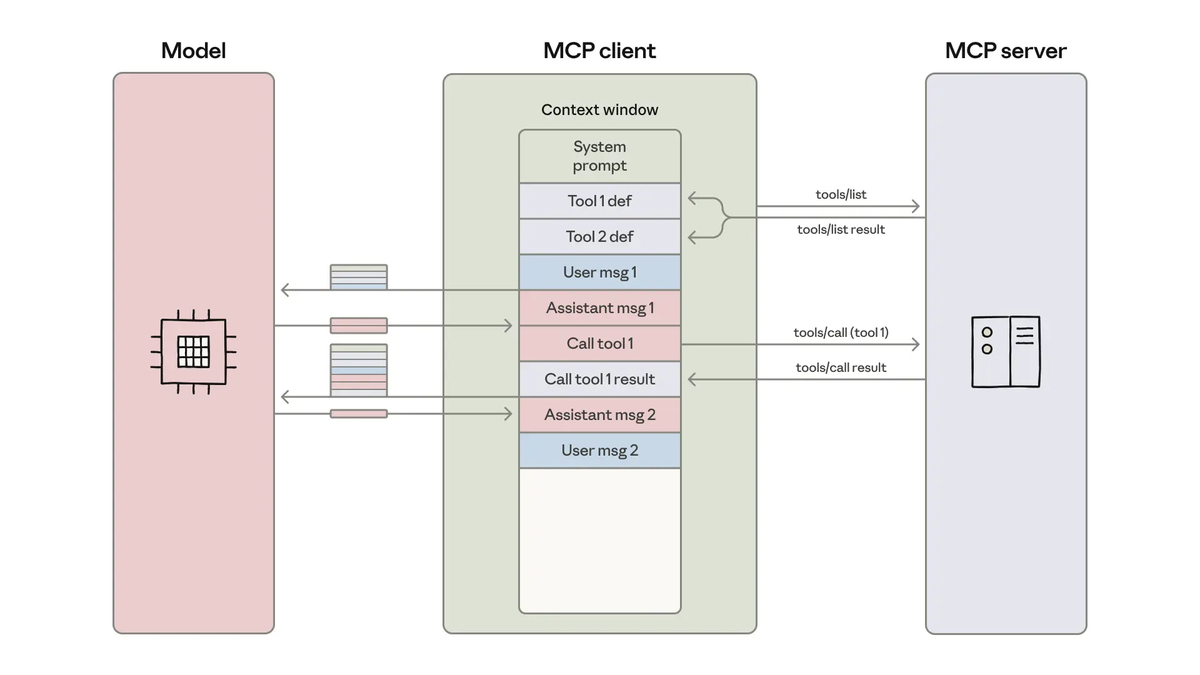
MCP — AnySearch's MCP server runs at https://api.anysearch.com/mcp and natively supports Streamable HTTP (MCP spec 2025-03-26). Client support as of the documentation:
- Clients with native Streamable HTTP (OpenCode, Claude Desktop 2025.6+, Claude Code): connect directly
- Clients requiring stdio (most Claude Code configurations): use
mcp-remoteas a proxy bridge - Clients requiring SSE (Cursor, Windsurf): connect via proxy
SKILL — available on GitHub, skills.sh, ClawHub, SkillHub, and Glama. Skills bundle the search capability with instructions for when and how to invoke it, making it composable inside Claude Code's skill system and compatible tools.
The right surface depends on the agent environment. For Claude Code with a standard terminal setup, the stdio-via-mcp-remote path is the documented approach. For OpenCode or Claude Desktop with Streamable HTTP support, direct connection is simpler.
How Real-Time Search Improves AI Development Workflows
Fresher docs and dependency context
The most direct value: an agent working on a Node.js project can query current npm package documentation rather than relying on training data. For fast-moving ecosystems (React, Python packaging, cloud SDKs), the difference between 6-month-old training data and current documentation is often the difference between working and broken code.
This matters most at the dependency boundary: when an agent is writing code that calls an external API or library, it needs the current interface, not the interface as of the training cutoff. Real-time docs search closes this gap.
GitHub, issue, and technical reference lookup
Coding workflows often involve understanding why a decision was made, not just what it was. GitHub issue history, PR discussions, and commit messages contain context that model training may have captured incompletely or not at all for recent activity.
An agent resolving a bug that resembles a known issue can search GitHub for related reports before proposing a fix, reducing the chance of a duplicate solution or a fix that misses the root cause. Source attribution from this kind of search — "this matches GitHub issue #4521, closed with the following fix" — gives reviewers a reference point to verify the agent's reasoning.
Source attribution before code changes
The governance case for search in coding agents goes beyond freshness. When an agent makes a change based on retrieved information, the audit trail should include where that information came from. A code review that shows "agent checked current API docs, retrieved version 3.2 interface, made changes consistent with that interface" is more auditable than "agent made changes based on its knowledge."
This is the same principle that applies to human engineering: cite your sources, especially for architectural decisions. Search infrastructure that returns structured, citable results supports this discipline in agentic workflows.
Where MCP Search Fits
Search as a reusable tool inside agent environments
MCP's value proposition for search is the same as its value proposition for any tool: define the capability once, use it consistently across agents and sessions. Anthropic's MCP engineering blog notes that agents now routinely access hundreds of tools across dozens of MCP servers. An MCP search server configured in Claude Code is available in every session without re-implementing the retrieval logic in each prompt.
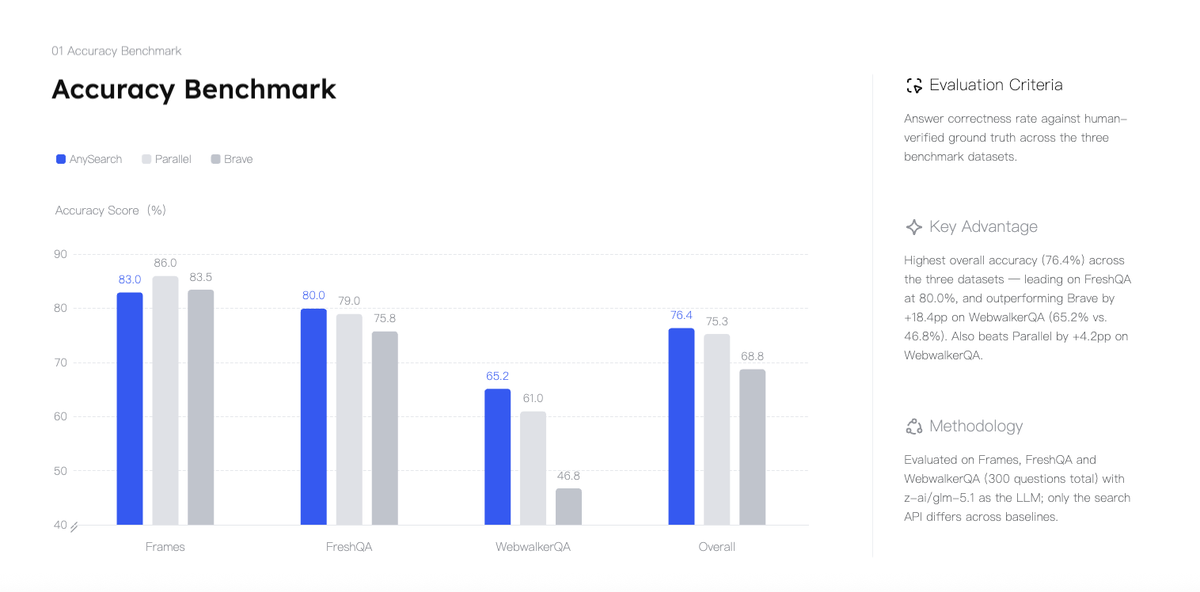
For coding teams standardizing on a tool stack, an MCP search server is part of the shared infrastructure — alongside the GitHub MCP integration, the Linear issue tracker MCP, and whatever observability and deployment MCP servers the team uses. Search becomes a peer capability to git operations and ticket management rather than an ad-hoc capability added to individual prompts.
Why tool routing matters for multi-agent coding
In single-agent workflows, tool routing is straightforward: the agent decides when to call search based on the task. In multi-agent workflows, tool routing becomes a coordination problem. If three parallel agents are each doing documentation lookups, they should be calling the same search infrastructure rather than each implementing their own retrieval logic — this produces consistent results, reduces total API calls through caching, and creates a shared audit trail.
A search tool available via MCP can be configured once in the agent orchestration layer and shared across all agents in a workflow. This is cleaner than embedding search prompts in each agent's instructions and hoping the retrieval behavior is consistent.
Limits, Risks, and Governance
Search results are not proof
The most important thing search cannot do is verify code correctness. A search result saying "API returns array" is not proof that the API returns an array — it's a claim from a web page. The agent still needs to validate against a test, a type check, or a known-good integration before trusting retrieval-based context.
This is where the promise of fresher context and the reality of agentic coding diverge. Search improves the quality of information the agent starts with. It doesn't replace the verification step that confirms the agent's output is correct. For coding workflows, verification requires the test suite to pass, the type checker to confirm, and the diff to be reviewed — none of which search addresses.
Third-party skills and MCP servers need review
Adding an MCP server to a coding agent's tool configuration is not a zero-cost decision. The MCP server has access to the agent's context — it sees the queries the agent sends, which may include repository names, library choices, and problem descriptions that reveal information about your codebase and architecture.
Before adding any third-party MCP server, including search-specific ones, teams should verify: what data the server logs, what its data handling policies are, whether the connection is appropriate given the sensitivity of what the agent will query, and whether the server is maintained by a organization with clear accountability. This applies to AnySearch and to any other MCP search provider.
Policies for enterprise coding agents
For teams running AI coding agents at scale, the governance requirements extend beyond individual tool choices. Questions that need policy answers:
- Which search sources are approved for agent use in coding workflows?
- Should agents be required to surface search attribution in code review?
- Is there a list of prohibited query types (e.g., queries that would reveal codebase internals to third-party search infrastructure)?
- Are rate limits and cost controls on search APIs tracked against team budgets?
These are the same governance questions that apply to any external service an agent can call. Search infrastructure is not special — it just needs to be inside the same governance framework as other tool integrations.
What This Means for Agentic Coding Platforms
Search is not the same as execution
The workflow layer distinction matters: search provides context; execution makes changes. A coding agent that searches for the current API interface is better informed than one that doesn't. But the search result doesn't change whether the code the agent produces is correct — that's determined by execution, testing, and review.
Platforms that blur this distinction — treating retrieval as a substitute for verification, or treating a search result as ground truth rather than an input — create a false confidence problem. Fresher context reduces one source of error (stale knowledge). It doesn't eliminate the need for the structural safeguards that catch errors from other sources: misunderstanding requirements, misapplying a correct API, or producing code that's technically accurate but architecturally wrong.
Why Plan-First and verification still matter
For coding workflows built on Plan-First principles — where agents decompose a task into a verifiable plan before touching code, and verification gates confirm output meets acceptance criteria before integration — search is an input to the planning step, not a substitute for verification. An agent that searches for current documentation before proposing an implementation plan is making a more informed plan. The plan still needs approval. The implementation still needs to pass tests.
For platforms like Verdent that enforce Plan-First execution with parallel worktree isolation, search fits naturally as a context-enrichment step before planning, not as a replacement for the verification that happens after implementation. The distinction is: search tells the agent what it should build; tests and review confirm it built it correctly.
FAQ
What is search for AI coding agents?
A dedicated mechanism for agents to retrieve current information — documentation, GitHub context, technical references, security advisories — from external sources during task execution. Unlike model training data, search-retrieved information reflects current state rather than training cutoff state. For coding workflows, this means agents can reference current library documentation, recently opened issues, and up-to-date API specifications rather than relying on potentially stale training knowledge. Verify specific capabilities and coverage at the tool's official documentation.
How can a coding agent use AnySearch or MCP search?
AnySearch provides three integration surfaces: direct API calls for custom agent implementations, MCP server connection for Claude Code, OpenCode, Cursor, Windsurf, and other MCP-capable clients, and Skill packages available on GitHub, skills.sh, ClawHub, SkillHub, and Glama. The MCP server URL is https://api.anysearch.com/mcp; connection approach varies by client's supported transport (Streamable HTTP, stdio, or SSE via proxy). Anonymous access is available without an API key at lower rate limits. Consult the official AnySearch documentation for current connection instructions, as client support and transport options evolve.
What are the risks of giving coding agents real-time search?
Three categories: information quality — search results are not proof; agents may act on incorrect or misleading retrieved content without verification; data exposure — queries sent to third-party search infrastructure may reveal information about your codebase, architecture, or problems; governance gaps — search introduces an external dependency that needs to be inside your tool approval, logging, and cost control frameworks. Mitigations: validate retrieved information against tests, review third-party MCP server data handling policies before integrating, and include search tools in your agent governance policies. Consult your organization's security and compliance team before integrating search into workflows that handle sensitive code.
When should teams add search to an AI coding workflow?
When agents are regularly working with fast-moving dependencies where training data staleness is a consistent source of errors, when source attribution for information-based decisions is required for code review, or when multi-agent workflows would benefit from shared, consistent retrieval infrastructure rather than per-agent ad-hoc lookups. Teams with stable, well-documented internal codebases and no external dependency churn will see less benefit. Teams working across multiple external APIs, framework versions, and rapidly-updating dependencies will see more. Assess search as part of your full tool governance review rather than as a standalone addition. Consult official documentation for current capabilities, access tiers, and rate limits before architectural commitments.
Related Reading
