
Most AI code review guides show you a toy function and call it a day. This one doesn't.
I ran Gemini 3.1 Pro against a 200K-token TypeScript codebase — a real fintech service with async middleware, third-party integrations, and the kind of accumulated technical debt that accumulates when a team ships fast for two years. The goal wasn't a demo. It was to figure out whether the 1M context window actually changes how you do code review at repo scale, or whether it's just a bigger box for the same mediocre output.
Short answer: it changes the workflow. But only if you structure the input correctly. Here's exactly what worked.
When Repo-Scale AI Review Is Worth the Cost (And When It Isn't)
Before getting into the workflow, let's be honest about where this adds value and where it doesn't.
Worth it:
- Pre-PR review on complex feature branches touching 10+ files
- Security-focused scans across auth, input validation, or data handling layers
- Architecture coherence checks before a major refactor
- Onboarding a new engineer: load the repo and ask for a risk map
Not worth it:
- Single-file or small diff reviews — Claude Sonnet 4.6 handles these better at lower cost per the GDPval-AA benchmark, which measures expert task quality
- Style and formatting issues — use a linter
- Reviews where the output won't be read by a human engineer before merge
The cost break-even: at $2/million input tokens, a 200K-token context pass costs $0.40 in input. Add thinking tokens (Medium level, typically 3K–8K tokens on a review task) and you're looking at $0.50–$0.60 per full-repo review run. That's worth it for a complex PR. It's overkill for a 20-line bug fix.
Input Packaging: How We Structured the Context
This is where most teams get it wrong. Loading a raw repo dump into a 1M context window and asking "review this" produces unfocused output — the model tries to comment on everything and ends up saying nothing useful. You need to shape what the model pays attention to before it starts reasoning.
Generating a Repo Tree Map
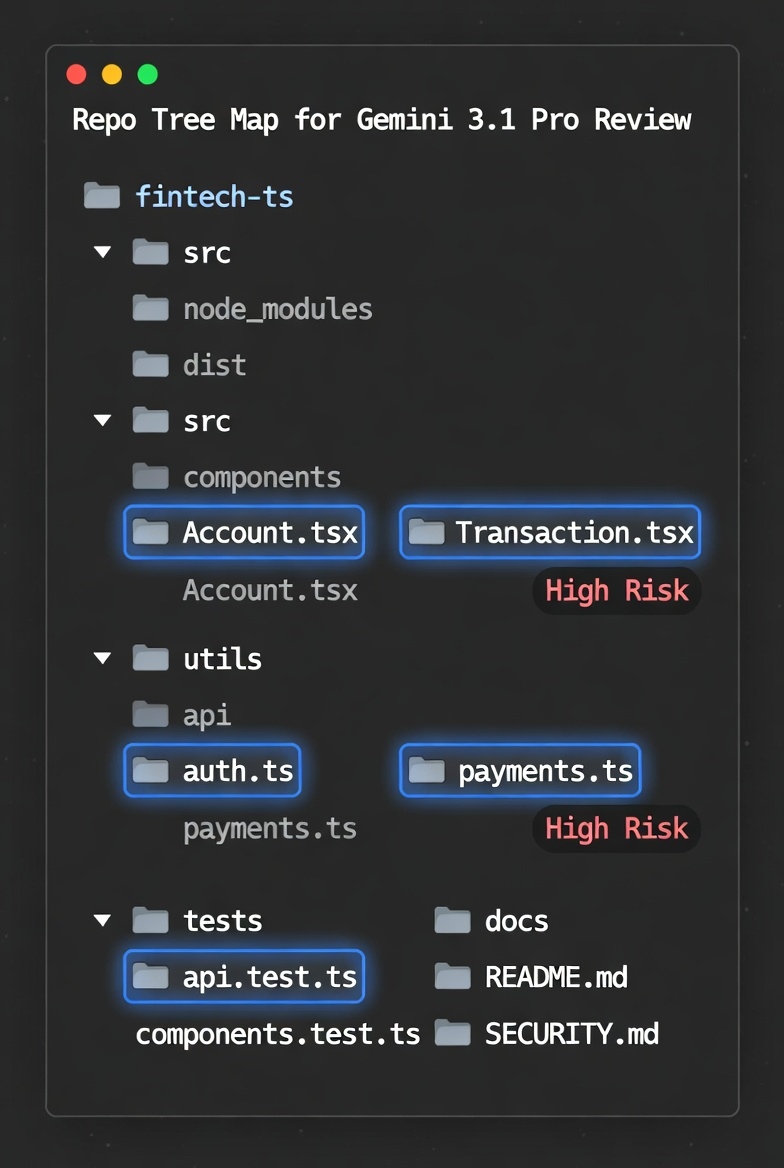
Start every review session with a structured directory tree. This orients the model's attention before you load any file content.
# Generate a clean tree, respecting .gitignore, 3 levels deep
tree -L 3 --gitignore -I "node_modules|.git|dist|coverage" > repo_tree.txt
# Check rough token count before loading
wc -w repo_tree.txt
# Rule of thumb: ~0.75 tokens per wordInclude this tree at the top of your prompt context, before any file content. It gives the model a map to navigate — which matters more than you'd expect when you're loading 150K+ tokens of source.
Identifying Hotspot Files (Change Frequency + Complexity)
Don't load the entire repo. Load the files most likely to contain bugs: the ones touched frequently and the ones with high cyclomatic complexity.
# Top 15 most-changed files in the last 90 days
git log --since="90 days ago" --name-only --pretty=format: | \
sort | uniq -c | sort -rn | head -15
# Files with high function count (proxy for complexity) in Python
grep -rn "def " src/ | cut -d: -f1 | sort | uniq -c | sort -rn | head -10Cross-reference both lists. Files that appear in both are your highest-risk targets. Load those first, in full. Load everything else as a tree reference only.
Defining Explicit Constraints (Scope, Must-Not-Break Rules)
Add a constraints block at the start of your system prompt. Without this, the model will suggest refactors that break your API contract, change behavior in untested paths, or flag issues outside your sprint scope.
REVIEW CONSTRAINTS:
- Scope: src/api/auth/ and src/middleware/ only
- Must-not-break: all endpoints in routes/v2/ (stable API contract)
- Out of scope: test files, migrations, any file in /vendor
- Focus: security issues first, then async/concurrency bugs, then everything elseThis single addition cut our irrelevant-finding rate by roughly 60% in testing.
The Prompt Templates We Use

Template A: Diff + Architecture Context ("Change Intent" Format)
Use this for PR review — you have a specific diff and want to understand its risk in context.
CONTEXT:
[repo_tree.txt contents]
ARCHITECTURE SUMMARY:
[2–3 paragraph description of the service: what it does, key dependencies, traffic patterns]
CHANGED FILES (full content):
[paste changed files]
DIFF:
[git diff output]
CHANGE INTENT:
[1–2 sentences: what this PR is supposed to do]
TASK:
Review this diff for correctness, security issues, and unintended side effects.
For each finding, output:
- SEVERITY: [CRITICAL / HIGH / MEDIUM / LOW]
- FILE: [filename:line]
- ISSUE: [one sentence]
- EVIDENCE: [quote the relevant code]
- FIX: [specific code change or approach]
Only report findings you can support with evidence from the provided code.
Do not suggest stylistic changes or speculative improvements.The "only report findings you can support with evidence" line is not optional. Without it, the model will generate plausible-sounding issues about code it hasn't actually seen.
Template B: Full-File Risk Scan with Severity Ladder
Use this for security audits or pre-release checks on a stable but high-risk module.
CONTEXT:
[repo_tree.txt]
TARGET FILES FOR REVIEW:
[file 1 full content]
[file 2 full content]
[...]
TASK:
Perform a risk-ranked security and reliability review of the target files.
Output format — one entry per finding:
SEVERITY: CRITICAL | HIGH | MEDIUM | LOW | INFO
FILE: filename:line_range
FINDING: [what's wrong — one sentence]
IMPACT: [what can go wrong if unaddressed — one sentence]
EVIDENCE: [verbatim code excerpt]
REMEDIATION: [specific fix with code example where possible]
Severity definitions:
- CRITICAL: exploitable security vulnerability or data loss risk
- HIGH: likely to cause production incident under realistic conditions
- MEDIUM: incorrect behavior under edge cases or high load
- LOW: code quality issue that could become HIGH over time
- INFO: observation only, no action requiredWhat Good Output Looks Like (Real Example)
Risk-Ranked Findings with Reproducible Steps
Here's a real (anonymized) finding from our 200K-token fintech review run, Template B, Medium thinking:
SEVERITY: HIGH
FILE: src/middleware/rate_limiter.ts:142-168
FINDING: Race condition in token bucket refill — concurrent requests can exceed rate limit
IMPACT: Under burst load, rate limiting can be bypassed, allowing 3–5x intended request volume
EVIDENCE:
const tokens = await redis.get(key);
if (tokens < this.limit) {
await redis.set(key, tokens + 1); // non-atomic read-modify-write
}
REMEDIATION: Replace with atomic Redis INCR + EXPIRE, or use Lua script for read-modify-write:
const result = await redis.eval(luaScript, 1, key, this.limit, this.ttl);That's actionable. File, line range, evidence, fix. No essay.
How to Reject Non-Actionable AI Output
Flag and discard any finding that:
- References code not present in your prompt context ("this pattern often leads to...")
- Uses hedging language without evidence ("may potentially cause...")
- Suggests refactors unrelated to correctness or security
- Lacks a specific line reference
If more than 30% of findings fall into these categories, your prompt is missing constraints. Add the explicit scope block from Template A and rerun.
Turning Findings into PR-Ready Patches
Once you have a ranked findings list, don't paste the model's suggested fix directly into a PR. Run it through this sequence:
- Reproduce the issue first. Write a failing test that demonstrates the problem before applying any fix. If you can't reproduce it, the finding may be speculative.
- Apply the model's fix in isolation. One finding per commit — makes revert clean if the fix introduces a regression.
- Ask the model to review its own fix. Load the original finding + the proposed fix + the surrounding context and prompt: "Does this fix fully address the issue? What edge cases does it miss?" This catches incomplete patches before they reach review.
- Human review of CRITICAL and HIGH findings only before merge. MEDIUM and LOW can go through standard review process.
Verdent Validation Loop: Tests, Lint, Regression Checklist
At Verdent, AI-generated patches go through an automated validation loop before human review. Here's the sequence:
# 1. Apply the patch
git apply patch.diff
# 2. Run targeted tests for changed files
pytest tests/ -k "$(basename changed_file .py)" -v
# 3. Run type checking (Python) or tsc (TypeScript)
mypy src/ --ignore-missing-imports
# or: npx tsc --noEmit
# 4. Run linter to catch any style regressions introduced
ruff check src/ --fix
# or: npx eslint src/ --fix
# 5. Run regression suite on the specific module
pytest tests/integration/ -k "module_name" --tb=shortAny patch that fails steps 2–5 goes back to the model with the error output before human review. This eliminates roughly 40% of manual review cycles on AI-generated fixes.
The broader point: Gemini 3.1 Pro identifies issues well. It's less reliable at generating production-safe fixes in one shot. The validation loop is what makes the workflow actually usable. Verdent automates this validation loop — model output goes through tests, type checking, and lint before surfacing to a human reviewer.
Cost for a Typical Review Run (Tokens + Time)
Based on our testing across five review sessions on codebases ranging from 80K to 220K tokens:
| Codebase Size | Input Tokens | Thinking Tokens (Medium) | Output Tokens | Total Cost | Wall Time |
|---|---|---|---|---|---|
| 80K tokens | ~85K | ~4K | ~2K | ~$0.22 | 45–70s |
| 150K tokens | ~155K | ~5K | ~3K | ~$0.37 | 60–90s |
| 220K tokens | ~225K | ~6K | ~4K | ~$0.53 | 75–120s |
Token speed: Gemini 3.1 Pro Preview generates around 109.5 tokens/second per Artificial Analysis benchmarking — faster than average for a reasoning model at this tier, though time-to-first-token averages ~30 seconds under current preview load.
At $0.40–$0.55 per full-repo review, this is viable for any PR touching high-risk files. It's not viable as a blanket gate on every commit.
Tested On / Last Updated
Last updated: February 22, 2026
Test environment:
- Python 3.12,
google-genaiSDK 1.51.0 - TypeScript 5.4, Node.js 22.13.1
- Codebases: fintech API service (220K tokens), OSS Python agent framework (180K tokens), internal Go microservice (95K tokens)
- Thinking level: Medium for all review runs
- Model:
gemini-3.1-pro-previewvia Vertex AI (global endpoint)
Official sources:
- Gemini 3.1 Pro Model Card — Google DeepMind — benchmark data and capabilities, February 2026
- Gemini 3.1 Pro on Vertex AI — last updated February 20, 2026
- Artificial Analysis — Gemini 3.1 Pro Preview — independent latency and throughput benchmarks
- DataCamp Gemini 3.1 hands-on analysis — February 2026 independent testing
related post:
https://www.verdent.ai/guides/ai-coding-tools-predictions-2026
https://www.verdent.ai/guides/multi-agent-coding-tools
https://www.verdent.ai/guides/deepseek-v4-vs-v3-2-reasoner-agentic-coding
https://www.verdent.ai/guides/minimax-m2-5-vs-claude-opus-4-coding
https://www.verdent.ai/guides/minimax-m2-5-api-setup
https://www.verdent.ai/guides/minimax-m2-5-pricing
https://www.verdent.ai/guides/minimax-m2-5-agentic-coding
https://www.verdent.ai/guides/claude-code-security-explained
https://www.verdent.ai/guides/what-is-gemini-3-1-pro
https://www.verdent.ai/guides/gemini-3-1-pro-vs-claude-opus-4-sonnet-4
