
If you run Claude Code on a Pro or Max plan, your default model quietly changed on June 9, 2026 — it's now Claude Fable 5, Anthropic's first generally available Mythos-class model, a tier that sits above Opus. For coding agents, that matters: Fable 5 leads agentic-coding evaluations and is built for long-horizon autonomous work. But it comes with three things builders need to understand before leaning on it — a safety fallback to Opus 4.8, roughly double the token cost, and 30-day data retention. Here's what actually changed in your Claude Code workflow.
Verified against Anthropic's official documentation and reporting as of June 2026. This is a fast-moving rollout — the usage-credits rules in particular changed on June 22, 2026, so confirm current details at the official Claude API docs before relying on specifics.
Claude Code Fable 5 in One Paragraph

Fable 5 as the generally available Mythos-class model
Claude Fable 5 is Anthropic's first publicly available "Mythos-class" model — a new capability tier above the Opus line — released June 9, 2026. The API model ID is claude-fable-5. It supports a 1M-token context window, up to 128K output tokens, and a knowledge cutoff of January 2026. Crucially for Claude Code users: as of June 9, 2026, Fable 5 became the default model in Claude Code for Pro and Max subscribers, falling back to Opus 4.8 when credits are tight.
Fable 5 shares the same underlying model as Claude Mythos 5, with one key difference: Fable 5 includes safety classifiers that can decline certain requests, while Mythos 5 (available only in limited release through Project Glasswing) does not. For practical purposes, Fable 5 is the Mythos-class model builders can actually use — Mythos 5 is not generally available, so this article is about Fable 5.
Why Claude Code users care
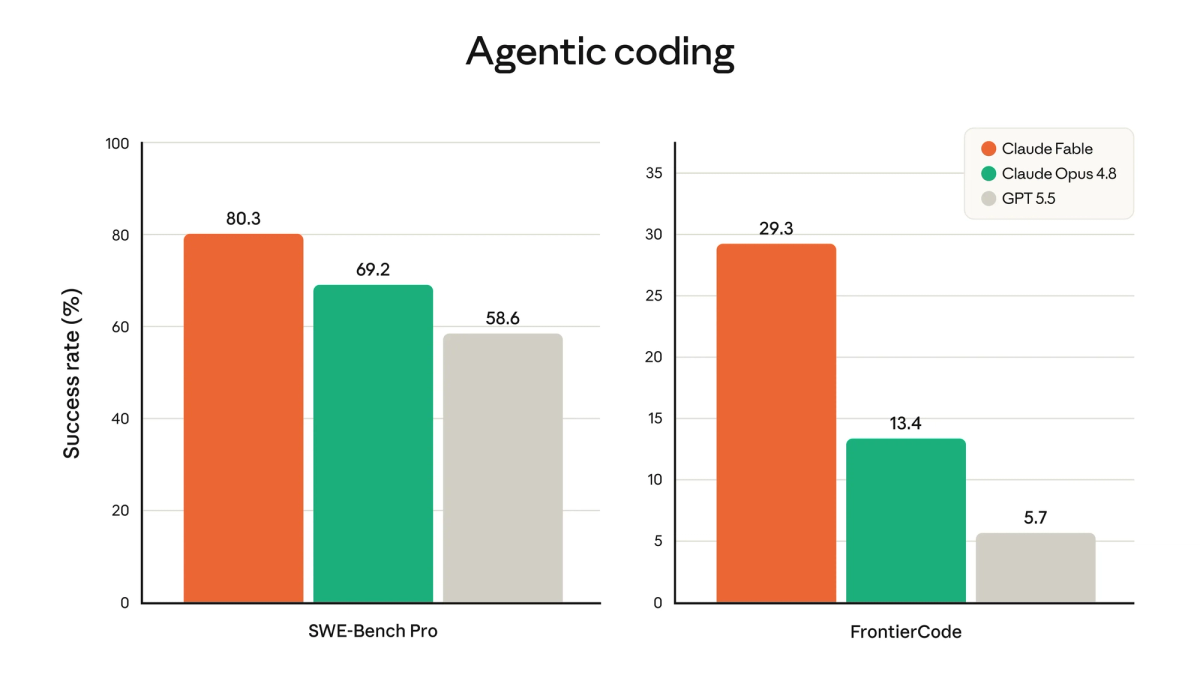
The reason this matters isn't the model name — it's that your default just got more capable and more expensive at the same time. Fable 5 leads agentic-coding benchmarks (independent testing reports roughly 80% on SWE-Bench Pro, versus Opus 4.8's lower score), which means better autonomous coding performance. But it costs $10/$50 per million input/output tokens — exactly 2× Opus 4.8 — and after June 22, 2026, it burns roughly 2× the usage credits on Pro/Max plans. So the practical question for every Claude Code user is: which of your workloads actually merit the more capable, more expensive default, and which should stay on Opus 4.8?
What Fable 5 Changes for Coding Agents
Long-running coding projects
Fable 5 is built for long-horizon agentic work — extended autonomous coding sessions where the agent stays coherent across many steps. This is the headline use case where Fable 5's capability advantage over Opus 4.8 is most pronounced. For a multi-hour autonomous run — implementing a feature end to end, working through a complex task with many sub-steps — the model's ability to maintain context and coherence across the session is where the Mythos-class capability shows.
The practical impact in Claude Code: tasks you might previously have broken into smaller chunks (to keep a less capable model on track) can run as longer, more autonomous sessions. The 1M-token context supports holding large amounts of code in working memory across the run. This is the workflow where paying the premium makes the most sense — long, hard, autonomous work rather than quick edits.
Multi-file implementation and migrations
For changes spanning many files — a feature touching frontend, backend, and tests, or a migration rippling through a codebase — Fable 5's stronger reasoning and large context help it track the interconnections. The model can hold more of the codebase in context and reason about how a change in one file affects others, which is where multi-file work tends to break down with weaker models.
In Claude Code, this means multi-file implementations and migrations are the kind of work where Fable 5 earns its cost. The combination of long-horizon stamina and large context suits exactly the tasks that are too big and too interconnected for quick single-file edits.
Self-testing and validation behavior
Fable 5's agentic strength includes running and responding to tests within the agent loop — writing code, running tests, observing failures, and iterating. This self-validation behavior is part of what makes a capable agentic model useful for autonomous work: the agent can catch and fix its own errors before handing back to you. The stronger the model's reasoning, the more reliable this loop tends to be.
The important caveat: self-testing within the agent loop is not the same as verification you can trust blindly. The agent running its own tests is a useful signal, but it doesn't replace your review of the diff and your own validation before merge. A more capable model raises the quality of the self-validation loop; it doesn't remove your responsibility to verify the output. The model upgrade is one layer; the workflow around it — Plan-First decomposition, diff review, and a verification step before integration — still matters, and is the concern that workflow-layer tools like Verdent address separately from whichever model powers the agent.
Claude Code Workflows That Fit
Large refactors and code migrations
The clearest fit for Fable 5 in Claude Code is large refactors and migrations — exactly the work that benefits from long-horizon stamina, large context, and strong multi-file reasoning. A refactor touching dozens of files, a framework migration, a large-scale API change: these are tasks where Fable 5's capability advantage translates to fewer errors and less hand-holding. If you've been splitting these into many small Claude Code sessions to keep things manageable, Fable 5 can handle larger spans in a single run.
(This article assumes you already know the Claude Code basics like worktree setup and running parallel agents; if not, those are covered separately — here the focus is what Fable 5 specifically changes.)
Multi-stage implementation with sub-agent delegation
Fable 5 suits multi-stage implementations where a primary agent delegates sub-tasks. One cost-aware pattern worth knowing: you don't have to run everything on Fable 5. A common approach is using a capable model as the orchestrator and cheaper models (Opus 4.8, or even Haiku 4.5) for routine sub-agent work — substantially reducing cost versus running every sub-agent on Fable 5. The orchestrator handles the hard reasoning and coordination; the sub-agents handle the mechanical work at a fraction of the cost.
This hybrid pattern is the practical answer to Fable 5's cost: reserve the expensive model for the work that needs it (planning, hard reasoning, complex integration) and route routine sub-tasks to cheaper models. Claude Code's model selection makes this configurable.
Limits, Fallback, and Cost Reality
When requests fall back to Opus 4.8
Fable 5's headline change for integrations is its safety classifiers — it can decline requests in high-risk domains (cybersecurity, biology, chemistry, and certain health-related areas, plus model distillation). When Fable 5 declines, the workflow can fall back to another Claude model like Opus 4.8 to handle the request. Anthropic's billing handles this cleanly: you're not billed for a request refused before any output is generated, and when you retry on another model, a fallback credit refunds the prompt-cache cost of switching so you don't pay it twice.
For builders, the practical implication: if your work touches security tooling, bioinformatics, chemistry, or health domains, expect some requests to route to Opus 4.8 rather than Fable 5. This is by design (the safety scaffolding is the reason Fable 5 is generally available while Mythos 5 isn't). Plan your integration to handle the refusal-and-fallback path gracefully.
Token burn and the June 22 usage-credits change
The cost reality is the thing to internalize. Fable 5 is exactly 2× the API cost of Opus 4.8 ($10/$50 vs $5/$25 per million input/output tokens). On June 22, 2026, Anthropic's usage-credits system for Claude Code Pro/Max changed, and Fable 5's credit consumption roughly tracks its API cost — about 2× Opus 4.8's credit burn. (Exact credit ratios may vary by tier and weren't fully published as a final rate table at launch — treat specific numbers as approximate and verify against your own claude usage output.)

The combined effect: if you migrated to Fable 5 as the default after June 9 and you're on a Pro/Max subscription, the June 22 credits change effectively cuts your monthly throughput compared to staying on Opus 4.8, because each task consumes roughly twice the credits. The cost-conscious move is to be deliberate — use Fable 5 for the workloads that merit it (long-horizon, hard reasoning) and keep routine high-volume work on Opus 4.8.
30-day data retention for Mythos-class models
A compliance detail builders must know: Fable 5 carries 30-day data retention and is not available under zero data retention (ZDR). Anthropic retains prompts and outputs for up to 30 days to operate the safety classifiers that detect harmful use, then deletes them; retained data is not used to train Anthropic's models. This applies specifically to Fable 5 (and Mythos 5, both designated Covered Models) — other Claude models like Opus 4.8, Sonnet, and Haiku continue to operate under ZDR.

For teams with strict data-residency or zero-retention requirements, this is a meaningful constraint: if your compliance framework requires ZDR, Fable 5 won't qualify, and you'd need to use a ZDR-eligible model like Opus 4.8 instead. Verify your data-handling requirements against this retention policy before defaulting to Fable 5 on sensitive code.
FAQ
What is Claude Code Fable 5?
Claude Fable 5 is Anthropic's first generally available "Mythos-class" model — a tier above Opus — released June 9, 2026, and now the default in Claude Code for Pro and Max subscribers. It leads agentic-coding benchmarks, supports a 1M-token context window and 128K output tokens, with a January 2026 knowledge cutoff (model ID claude-fable-5). It shares Mythos 5's underlying model but adds safety classifiers that can decline high-risk requests, costs 2× Opus 4.8, and carries 30-day data retention.
Is Fable 5 the default model in Claude Code now?
Yes, as of June 9, 2026, Claude Code Pro and Max tiers default to Fable 5 when available, falling back to Opus 4.8 when credits are tight. Free claude.ai users do not get Fable 5 (Pro or higher is required). If you're on Pro/Max and haven't changed your model selection, you're likely running Fable 5 by default — which also means roughly 2× the credit consumption after the June 22, 2026 usage-credits change. You can switch back to Opus 4.8 for routine work via Claude Code's model selection. Verify your current default with the claude model selection in your terminal.
Why does Fable 5 fall back to Opus 4.8?
Two reasons. Safety: Fable 5's classifiers can decline requests in high-risk domains (cybersecurity, biology, chemistry, health, model distillation), routing them to another model like Opus 4.8. Cost/credits: on Pro/Max plans, Claude Code falls back to Opus 4.8 when Fable 5 credits run tight (it consumes ~2× the credits). Anthropic doesn't bill for a request refused before output and refunds the prompt-cache cost on retry. The fallback is by design.
Is Fable 5 the same as Mythos 5?
They share the same underlying model but aren't interchangeable in practice. Fable 5 includes safety classifiers that can decline high-risk requests; Mythos 5 has them lifted. Critically, Mythos 5 is not generally available — it's limited to Project Glasswing approved customers (infrastructure providers, vetted researchers). Fable 5 is the version builders can actually use: generally available on the Claude API, Bedrock, Vertex AI, Microsoft Foundry, and as the Claude Code Pro/Max default. For typical builders, Fable 5 is your Mythos-class option.
Related Reading
