
Both are Google models. That's where the similarity ends. Gemma 4 is an open-weight family you run on your own hardware; Gemini 3.5 Flash is a cloud API you call. The choice between them isn't really about which model is "better" — it's about whether you want local control (privacy, no per-token cost, offline) or cloud agentic performance (frontier-level coding, no hardware constraints, managed infrastructure). For builders, that local-vs-cloud trade-off shapes the entire decision.
Verified against Google's official announcements and documentation as of June 2026. Benchmark and pricing figures are from official sources or vendor reporting — confirm current details at the official docs before relying on specifics.
Quick Answer
Local control vs cloud agentic performance
Pick Gemma 4 if: privacy is a hard requirement (code can't leave your machine), you want zero per-token cost for high-volume work, you need offline capability, or you want to self-host an open-weight (Apache 2.0) model you can fine-tune and fully control. Gemma 4 trades raw capability for control and cost.

Pick Gemini 3.5 Flash if: you want frontier-level coding and agentic performance, you don't want to manage local hardware, you need the broadest multimodal support and Google ecosystem integration, or your workflow involves agentic loops where cloud-scale capability matters. Gemini 3.5 Flash trades local control for capability and managed infrastructure.

The honest framing: these aren't competitors so much as different points on a spectrum. Gemma 4 is the local/open-weight option; Gemini 3.5 Flash is the cloud/managed option. Many builders use both — Gemma 4 for private, scoped, cost-sensitive work and Gemini 3.5 Flash for agentic tasks needing frontier capability.
Gemma 4 in One Paragraph
Open-weight local model path
Gemma 4 is Google DeepMind's open model family, released April 2, 2026 under the Apache 2.0 license. Unlike Gemini (a cloud API), Gemma 4 ships as downloadable weights you run locally via Ollama, llama.cpp, MLX, vLLM, or similar runtimes. This is the defining difference: with Gemma 4, the model runs on your hardware, your code never leaves your machine, and you pay nothing per token. The trade-off is that you're bounded by your local hardware's capability, and an open-weight model on consumer hardware delivers less than a frontier cloud model.
For developers who need privacy (compliance, confidentiality), want to fine-tune on their own data, or want to eliminate per-token costs for high-volume work, the open-weight local path is the reason to choose Gemma 4 over any cloud model.
E4B, 26B MoE, and 31B as practical choices
The original Gemma 4 family shipped in four sizes — E2B, E4B, 26B MoE, and 31B Dense. (A separate 12B Unified model was added as a follow-up in June 2026.) For local coding, the practical choices:
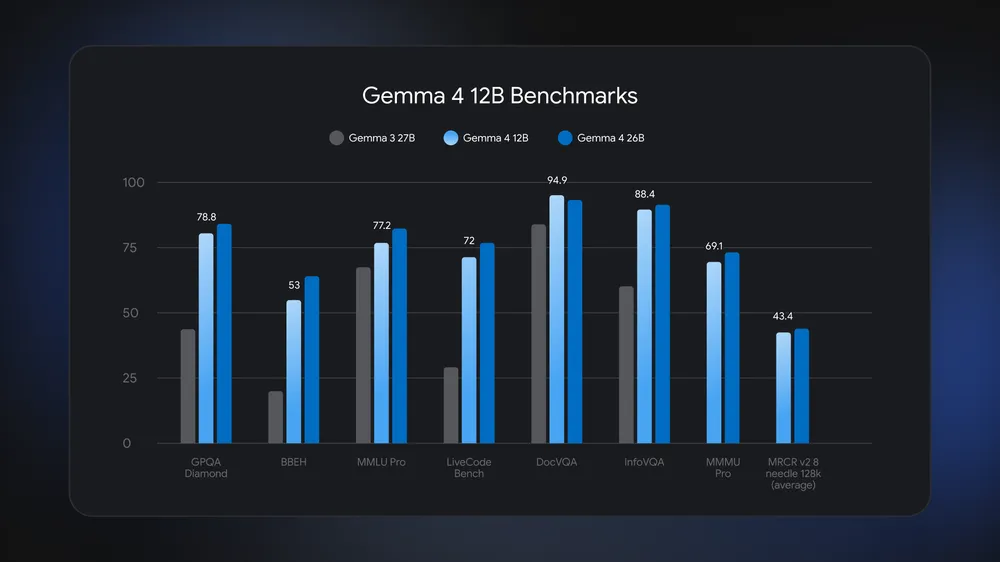
- E4B (4.5B effective / 8B total) — runs on a 16 GB laptop, the safe default for lighter local work
- 26B MoE (26B total, 4B activated per token) — the balanced workhorse, runs on a 24 GB GPU/Mac, ranked #6 on Arena's text leaderboard
- 31B Dense (full 31B active) — the highest-quality variant, ranked #3 open model on Arena, needs workstation-class memory
You pick the variant your hardware can hold and reason over — E4B for laptops, 26B for a capable GPU, 31B for a workstation.
Gemini 3.5 Flash in One Paragraph
Google's current Flash model for agentic and coding workflows
Gemini 3.5 Flash launched at Google I/O 2026 (May 19, 2026) as generally available and stable — the first model in the Gemini 3.5 family and, per Google, the strongest agentic and coding model the Flash series has shipped. The model ID is gemini-3.5-flash (no preview suffix — it's production-stable). It's optimized specifically for agentic workflows, parallel execution loops, and sub-agent deployment, with native function calling, structured outputs, and code execution.
On coding and agentic benchmarks, Google reports it outperforms Gemini 3.1 Pro — including 76.2% on Terminal-Bench 2.1 and 83.6% on MCP Atlas (per Google's reporting; treat vendor benchmarks as directional). It runs roughly 4× faster than comparable frontier models, often at less than half the cost, with dynamic thinking on by default (the model auto-allocates more compute for harder problems).
Cloud API and Google developer ecosystem
Gemini 3.5 Flash is delivered through Google's cloud: the Gemini API, Google AI Studio, Google Antigravity, the Gemini app, and AI Mode in Google Search. It has a 1M-token input context window, supports text/image/audio/video/PDF input, and integrates with Google-native tooling (search grounding, Maps grounding, URL context, Batch/Flex discounts, context caching). For builders already in the Google ecosystem, this integration is a meaningful advantage. The trade-off versus Gemma 4: your code transits Google's infrastructure, and you pay per token.
Comparison Table
| Gemma 4 | Gemini 3.5 Flash | |
|---|---|---|
| Type | Open-weight, local | Cloud API |
| License | Apache 2.0 | Proprietary (API access) |
| Where it runs | Your hardware | Google's cloud |
| Cost model | Free (your compute) | Per-token ($1.50/$9 per 1M, per Google) |
| Privacy | Code stays local | Code transits Google's cloud |
| Offline | ✅ | ❌ (cloud API) |
| Capability ceiling | Bounded by local hardware | Frontier-level |
| Context | Up to 256K | 1M input tokens |
| Multimodal | Text/image/audio (varies by size) | Text/image/audio/video/PDF |
| Coding-agent fit | Scoped local tasks | Agentic loops, sub-agents, parallel execution |
| Fine-tuning | ✅ (open weights) | Limited (API) |
| Ecosystem | Local runtimes (Ollama, etc.) | Gemini API, AI Studio, Antigravity |
Locality, governance, speed, multimodal support, coding-agent fit
Locality and governance are the core split. Gemma 4 keeps code on your machine — the strongest governance position for sensitive code. Gemini 3.5 Flash sends code to Google's cloud, which means your data handling falls under Google's terms and your compliance requirements need to permit it.
Speed depends on context. Gemini 3.5 Flash is fast (4× comparable frontier models) on Google's infrastructure. Gemma 4's speed depends entirely on your hardware — fast on a workstation, slower on a laptop, and dependent on the variant.
Multimodal support favors Gemini 3.5 Flash (text/image/audio/video/PDF, 1M context) over Gemma 4 (text/image/audio, up to 256K, varying by size).
Coding-agent fit is where the capability gap shows. Gemini 3.5 Flash is purpose-built for agentic loops, sub-agent deployment, and parallel execution at frontier capability. Gemma 4 handles scoped local coding tasks well but isn't built for the same scale of autonomous agentic work — its agentic ceiling is bounded by local hardware.
Which Fits Builder Workflows?
Local prototyping and privacy-sensitive experimentation
For prototyping where code can't leave your machine, or experimentation where per-token costs would add up, Gemma 4 is the clear fit. Running locally means no API costs regardless of how many iterations you run, and code stays private by default. For developers at companies with strict data residency requirements, or working on confidential code, the open-weight local path may be the only compliant option. The 26B MoE or 31B Dense variants give enough capability for serious local prototyping; E4B suffices for lighter work.
Cloud agent workflows and fast iteration
For agentic coding workflows — multi-step tasks, sub-agent deployment, parallel execution loops where each iteration consumes tokens — Gemini 3.5 Flash's combination of frontier capability and Flash-tier speed/cost is purpose-built. Its 1M context handles full codebases, its agentic optimization suits the kind of plan-call-tools-iterate loops that coding agents run, and the Google ecosystem integration (AI Studio, Antigravity) streamlines the build. When capability and speed matter more than locality, this is the fit.
Hybrid routing across local and cloud models
The pattern many builders converge on: route by task. Use Gemma 4 locally for private, scoped, or high-volume work where cost and privacy matter; route to Gemini 3.5 Flash for tasks needing frontier capability, large-context reasoning, or agentic depth that exceeds local hardware. Because both are Google models, they share enough behavioral consistency that hybrid routing is less jarring than mixing across vendors. This is the practical answer for many teams — not choosing one, but matching the model to each task's requirements.
A framing worth keeping clear regardless of which model you pick: Gemma 4 and Gemini 3.5 Flash are both model-layer choices. The workflow layer — how tasks are planned, how agents are coordinated, how changes are verified before integration — is a separate concern. Tools like Verdent operate at that workflow layer (Plan-First decomposition, parallel agents on isolated Git worktrees, reviewable diffs with verification) and are model-agnostic: they structure how agent work happens regardless of whether the underlying model is a local Gemma 4 or a cloud Gemini 3.5 Flash. Choosing the model and structuring the workflow are independent decisions.
FAQ
What is the difference between Gemma 4 and Gemini 3.5 Flash?
Gemma 4 is Google's open-weight family (Apache 2.0) you run locally — code stays on your machine, no per-token cost, offline, but bounded by local hardware. Gemini 3.5 Flash is a cloud API (gemini-3.5-flash) — frontier coding/agentic performance, 1M context, broad multimodal, but code transits Google's cloud and you pay per token. The core difference: local control versus cloud capability.
Can Gemma 4 replace Gemini 3.5 Flash for coding agents?
For scoped, privacy- or cost-sensitive work, often yes — Gemma 4 (especially 26B/31B) handles explanation, small edits, and tests well. For demanding agentic loops (multi-step autonomous work, sub-agent deployment, frontier-capability parallel execution), Gemini 3.5 Flash is purpose-built and bounded only by cloud scale, while Gemma 4's ceiling is bounded by local hardware. Test against your actual tasks.
Is local Gemma safer than cloud Gemini?
For data privacy, yes — local Gemma 4 keeps code on your machine, with no third-party data transit, which matters for confidential or regulated code. For everything else (output correctness, security of generated code), locality doesn't make Gemma inherently safer: both need the same review discipline — read the diff, run tests, verify output. Local execution removes data-transit risk, not the need to verify what the model produces.
When should builders choose Gemma 4 over Gemini 3.5 Flash?
Choose Gemma 4 when privacy is a hard requirement, when you want zero per-token cost for high-volume work, when you need offline capability, or when you want to fine-tune an open-weight model. Choose Gemini 3.5 Flash for frontier agentic capability, no hardware management, or broad multimodal support. Many builders use both — local Gemma for private/scoped work, cloud Gemini for frontier agentic tasks.
Related Reading
