
The benchmark that matters most for Gemma 4 is the one Google didn't lead with.
LiveCodeBench 80%, Codeforces ELO 2150 — those numbers are real, and they're about competitive programming. Your coding agent doesn't solve graph traversal problems. It reads messy production code, calls tools that sometimes fail, and needs to recover across dozens of sequential steps without losing context. The benchmark that tells you whether Gemma 4 can do that is τ2-bench: agentic tool use. Gemma 3 27B scored 6.6%. Gemma 4 31B scored 86.4%. That's the number worth talking about — and this article explains what it means for the model variant decision.
Gemma 4 in One Paragraph — What Changed

Four models shipped: E2B, E4B, 26B MoE, and 31B Dense. All are Apache 2.0 licensed — a first for the Gemma family, and the most operationally significant change for commercial teams. The 31B Dense model currently ranks #3 on the Arena AI text leaderboard. The 26B MoE activates only 3.8 billion of its 26 billion parameters per forward pass, which the official Hugging Face model card describes as running "almost as fast as a 4B-parameter model." Every model in the family includes native function calling, configurable thinking mode, and 256K context (128K for the edge models). Training data has a cutoff of January 2025, confirmed in the official Google Model Card.
The jump from Gemma 3 was not incremental. On AIME 2026 (math competition): Gemma 3 27B scored 20.8%, Gemma 4 31B scored 89.2%. On τ2-bench Retail (agentic tool use): Gemma 3 27B scored 6.6%, Gemma 4 31B scored 86.4%. These numbers don't come from a narrow optimization — they reflect a model built from the same research stack as Gemini 3.
Code Benchmark Breakdown
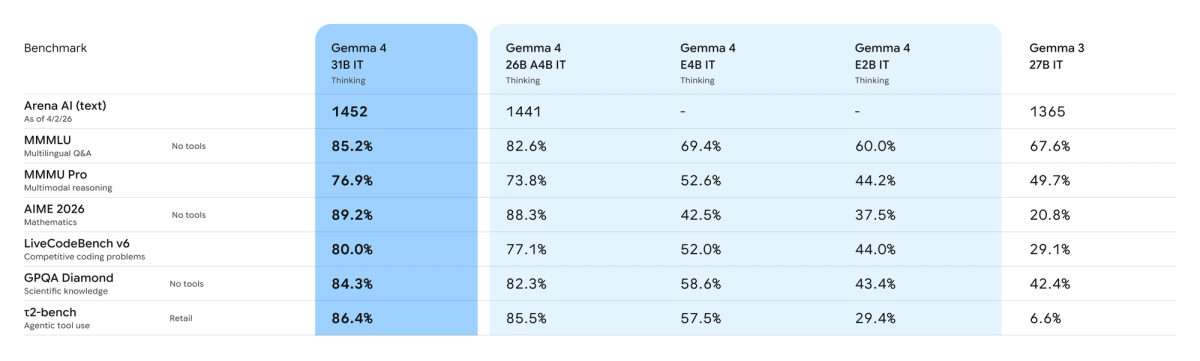
LiveCodeBench v6 tests competitive programming problems that were not publicly available during training, specifically to reduce data contamination risk. Gemma 4 31B scores 80.0%, up from 29.1% on Gemma 3 27B. The 26B MoE scores 77.1% on the same benchmark. These are numbers from the official model card.
Codeforces ELO measures performance on competitive programming challenges at rated difficulty levels. ELO 2150 corresponds to roughly Candidate Master tier on the Codeforces platform. For reference, Gemma 3 27B sat at ELO 110 — essentially below Newbie. The 26B MoE variant reaches ELO 1718 according to TokenCost's April 2026 analysis.
What these benchmarks measure — and don't. Both LiveCodeBench and Codeforces ELO reflect performance on algorithmic competition problems: graph traversal, dynamic programming, sorting, mathematical reasoning under constraints. This differs from the actual failure modes in production coding agent workflows: long-horizon task decomposition across multiple files, consistent tool-calling across 30+ turns, recovering gracefully from failed intermediate steps, and navigating real codebases where the correct approach isn't a well-posed algorithmic problem.
τ2-bench is arguably more relevant here. The 86.4% score on τ2-bench Retail measures multi-step tool use in a realistic agentic environment. Gemma 3 27B's 6.6% on the same benchmark illustrates that thinking mode and architectural changes made a fundamental difference — not just better answers, but better sequential action.
31B vs 26B MoE: Which for Coding Agents

The choice depends on your deployment constraints and what you're optimizing for.
31B Dense is the right choice when: you need maximum coding quality (Codeforces ELO 2150 vs 1718), you're fine-tuning for a domain-specific codebase, or you're running in a server environment with an 80GB H100 where throughput is less of a constraint. At unquantized bfloat16, the 31B fits on a single H100. With Q4 quantization, it runs on a consumer GPU with 24GB+ VRAM.
26B MoE is the right choice when: you're running high-concurrency workloads where throughput matters (more requests per GPU), you're VRAM-constrained (fits on a 24GB RTX 3090/4090 at Q4), or you're evaluating cost efficiency first. On most benchmarks the gap is 1–3 points — meaningful on competitive coding tasks, small in practice for most agent tasks that aren't adversarially hard. On OpenRouter as of April 2026, the 26B MoE is priced at $0.13/M input tokens vs $0.14/M for the 31B, a minor difference but reflecting the lower inference compute.
The inference speed advantage of the MoE variant is real. With only 3.8B active parameters per forward pass, throughput at the same hardware scales significantly higher than the 31B. Google's official release post describes the 26B MoE as focused on "latency, activating only 3.8 billion of its total parameters during inference to deliver exceptionally fast tokens-per-second."
One decision point that gets overlooked: if fine-tuning is on your roadmap, 31B Dense is the clearer path. MoE fine-tuning requires routing the gradient updates correctly across experts, which is well-understood but adds complexity. Dense fine-tuning is simpler to set up and iterate on.
Native Function Calling and Agent Workflow Support
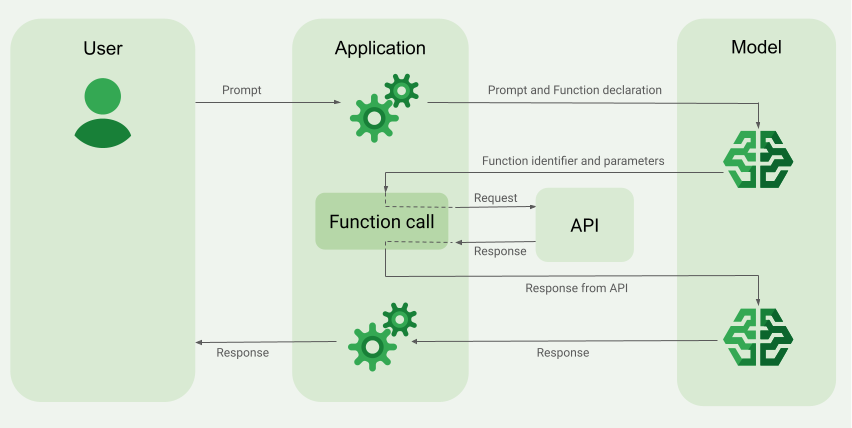
This is where Gemma 4 makes the clearest case for coding agent use cases. Function calling is native in all four variants — not a post-training patch, but built into the model's architecture and training. The Google Cloud documentation confirms explicit support for: structured tool use, JSON output, multi-step planning, and configurable thinking mode.
ADK (Agent Development Kit) compatibility is confirmed. The official ADK documentation lists Gemma 4 as a supported model, with explicit guidance for deploying via Vertex AI, GKE, and Cloud Run. Tool calling and structured output are both listed as supported ADK features. The ADK documentation provides working code examples for Gemma 4 with vLLM endpoints.
The configurable thinking mode is worth understanding clearly. In thinking mode, the model generates extended reasoning tokens (marked with <|think|>) before producing its final response. On tasks requiring multi-step planning — the kind a coding agent typically handles — this substantially improves quality. On simple code completion tasks, it adds latency for marginal gain. Thinking is toggled at the system prompt level, so you can route different request types to different configurations without deploying separate models.
Deployment Reality
Gemma 4 has day-one support across the inference ecosystem: Hugging Face Transformers, vLLM, Ollama, llama.cpp, MLX, NVIDIA NIM and NeMo, LM Studio, SGLang, and Docker. This is broader launch-day framework coverage than most open model releases achieve.
Cloud: The 26B MoE model is available as a managed serverless endpoint on Vertex AI Model Garden. Both 26B and 31B are deployable on Cloud Run with NVIDIA RTX PRO 6000 GPUs. TTFT latency improvement of up to 70% is cited for GKE Inference Gateway with predictive latency scheduling — though that figure comes from Google's own infrastructure documentation, not independent benchmarks.
Local: 31B Dense at bfloat16 requires a single 80GB H100. At 4-bit quantization, it fits on a 24GB consumer GPU. The 26B MoE fits on the same 24GB card with Q4 quantization and delivers materially faster inference. E2B and E4B run on laptops and mobile devices.
Self-hosted agent loop considerations: Because MoE models load all 26B parameters into memory (even though only 3.8B activate per token), VRAM requirements scale with total parameters, not active parameters. At Q4, you're loading roughly 14–16GB for the 26B MoE — feasible on an RTX 3090 or 4090, but not headless servers with smaller cards. Plan accordingly.
Limitations to Know Before Adopting
Training data cutoff is January 2025. This is 14 months before the April 2026 release date. The model has no knowledge of: Gemma 4 itself, models released after January 2025, API changes, library updates, or security patches from 2025 onward. For coding agents operating on recent dependencies or frameworks, retrieval augmentation is not optional — it's necessary for accurate behavior.
LiveCodeBench ≠ production agent performance. The jump to 80% on LiveCodeBench is real. What it doesn't tell you is how the model handles multi-file refactoring, recovering from tool call failures across 20+ steps, or navigating a 150K-token codebase with inconsistent naming conventions. These are the tasks where coding agent infrastructure matters — and they require evaluation on your actual workloads, not benchmark proxies.
MoE inference has routing overhead. In high-concurrency batched inference, the sparse expert routing adds overhead that doesn't exist in dense models. At low concurrency (single-user, interactive), the 26B MoE is generally faster. At very high concurrency, routing costs can offset throughput gains. Test under your actual load pattern before committing to production configuration.
No system-level evaluation of persistent agent quality. The τ2-bench Retail score of 86.4% is encouraging, but τ2-bench is a structured retail task environment. Real multi-agent coding workflows — the kind where Verdent's parallel worktree architecture manages multiple agents across different branches of the same codebase — require models to maintain state coherence across sessions, understand project-level context, and produce consistently mergeable diffs. Benchmarks don't cover this yet.
Gemma 4 is not the right choice if you need: persistent memory management across sessions, model-level codebase indexing, or an integrated development workflow. These require infrastructure — an IDE integration layer or multi-agent orchestration system — rather than a better base model.
FAQ
Does Gemma 4 support tool calling natively?
Yes. Native function calling is built into all four variants. The ADK documentation confirms support for structured tool use and JSON output. For vLLM deployments, ensure the serving configuration includes the compatible function calling and reasoning parsers — the Cloud Run documentation notes this explicitly.
What does the Apache 2.0 license change mean practically?
Previous Gemma models used Google's custom "Gemma Terms of Use." That license included acceptable-use restrictions, extended ambiguously to models trained on Gemma-generated synthetic data, and could be updated unilaterally. Enterprise legal teams frequently declined to use it without extended review. Apache 2.0 eliminates all of that: no MAU caps, no downstream policy enforcement requirements, no ambiguity about synthetic data. It's the same license Qwen, Mistral, and most of the open-weight ecosystem already use — legal teams have the boilerplate.
Is the 26B MoE actually faster than a 4B model?
No — not unconditionally. The 26B MoE activates 3.8B parameters per forward pass, which means compute per token is roughly in the 4B range. But the model still loads all 26B parameters into VRAM. Memory bandwidth is the bottleneck on most GPU hardware for autoregressive inference. On bandwidth-constrained hardware (consumer GPUs), the MoE is materially faster than the 31B Dense and broadly comparable to 4B-class inference speeds. On high-bandwidth hardware (H100s with 3.35 TB/s HBM3), the gap narrows. The Hugging Face model card says it "runs almost as fast as a 4B-parameter model" — "almost" is doing real work in that sentence.
How does Gemma 4 compare to Qwen 3.5 or Llama 4 for coding agents?
Each has a distinct position. Gemma 4 31B leads on Codeforces ELO (2150 vs Qwen 3.5 27B's competitive range) and has the cleaner Apache 2.0 license. Llama 4 Scout has a dramatically larger context window (10M tokens) which matters if your agent needs to read entire large repositories in a single call. Qwen 3.5 has a larger flagship at 397B parameters. For the 31B-class comparison specifically, Gemma 4 is the strongest open-weight coding option as of April 2026 — but that's a single data point, and both families release frequently.
What's the training data cutoff?
January 2025, per the official Model Card. The model was released April 2, 2026 — a 14-month gap. For any coding task that references frameworks, APIs, or security patches released after January 2025, retrieval augmentation is necessary.
Conclusion
Gemma 4 is a meaningful step for open-weight coding infrastructure. The license is clean, the benchmark gains over Gemma 3 are substantial, and native function calling with ADK support removes the friction that made earlier Gemma versions awkward to integrate. For teams evaluating open-weight models for agent subagent roles, the 26B MoE is the right starting point for throughput-constrained environments; the 31B Dense is the right choice for maximum quality or fine-tuning workflows.
The caveats are real. Competitive programming benchmarks don't directly predict production agent reliability. The January 2025 knowledge cutoff makes retrieval augmentation mandatory for current dependencies. And Gemma 4 is a base model — the quality of the agent orchestration layer above it matters as much as the model itself. If the gap you're trying to close is in multi-agent parallel execution, persistent codebase context, or structured code verification, that's an infrastructure problem rather than a model selection problem.
Related Reading
- GLM-5-Turbo vs GLM-5V-Turbo: Which Agent Model to Use — Another open-weight model comparison for agent workflows, covering Z.ai's API-only variants at similar price tiers.
- LLM Knowledge Base for Coding Agents: Beyond RAG — How to address the knowledge cutoff problem with structured persistent context — relevant for any model with a dated training cutoff.
- AutoResearch vs AI Coding Agents: Where Autonomous Research Ends — Distinguishes autonomous research workflows from agentic coding infrastructure; useful context for evaluating where Gemma 4 fits.
- What Is Muse Spark? Meta's New AI Model Explained — The proprietary frontier model that released the same week as Gemma 4, for benchmarking the open-weight vs. closed-model decision.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — The orchestration layer that sits above model selection — where persistent context, parallel worktree isolation, and code verification live.
