
You're already running Claude Opus 4.7 in Claude Code, your agent loops are stable, and your team has built up workflow muscle around the current model. Anthropic released Opus 4.8 on May 28, 2026 — same price, reportedly better at agentic coding, and with some new Claude Code features. The honest question for builders isn't "is 4.8 better." It's "does upgrading actually improve my workflow enough to justify the testing cost?" This guide is built around that decision.
Based on Anthropic's release information current at May 29, 2026. Benchmark figures are Anthropic self-reported. Verify pricing, model IDs, and feature availability at the official Claude Opus page before making commitments.
Quick Answer: Should 4.7 Users Upgrade?
When upgrading is likely worth testing
You should test the upgrade if:
- Your workflow involves long-horizon agent loops running many steps autonomously — 4.8's reported improvements in this area are most directly relevant
- You're hitting limits where agents miss their own code errors — Anthropic reports 4.8 is approximately 4× less likely than 4.7 to let its own code flaws pass unremarked
- You run multi-file, multi-hour migrations that would benefit from Claude Code's new dynamic workflows feature (parallel subagents) — available on Enterprise, Team, and Max plans
- You use fast mode interactively and find the previous fast mode too expensive — 4.8's fast mode is 3× cheaper than on previous models
- You want to steer long agent sessions mid-flight without breaking prompt caching — 4.8 supports mid-conversation system message changes that keep cached input rates intact
When to stay on 4.7 for now
Hold off if:
- Your workflow is heavily terminal/CLI-centric — Anthropic's reporting indicates GPT-5.5 leads on terminal/CLI coding benchmarks; the 4.8 upgrade may not address this specific axis
- You've tuned prompts and effort levels carefully on 4.7 and don't have testing capacity right now — every model update can shift prompt behavior subtly, and re-tuning a working setup is real work
- You're on a regulated or compliance-sensitive deployment — newer models warrant cautious rollout regardless of benchmark improvements
- You don't have representative coding tasks ready for evaluation — without local evals, you're choosing based on benchmark aggregates rather than your actual workload
The conservative position: 4.7 isn't broken. The upgrade is worth testing on a non-critical path before broader adoption.
Claude Opus 4.7 vs 4.8 at a Glance
Model behavior and reliability
The key behavioral shifts Anthropic reports for 4.8 vs 4.7:
- Better judgment in agentic tasks — described as "more reliable and sharper in its judgement" during agent runs
- Honesty improvement — approximately 4× less likely than 4.7 to let flaws in its own code pass unremarked; more likely to flag uncertainties about its own work
- Tool calling efficiency — fewer steps for the same intelligence, more efficient end-to-end task completion
- Long-context coherence — better at carrying context and style direction across long sessions
The reliability framing matters specifically for builders running autonomous workloads. A model that catches more of its own errors and completes tasks in fewer tool calls means lower cost per task and fewer surprises during unattended runs.
Claude Code defaults
Both models work in Claude Code. The defaults differ:
| Opus 4.7 | Opus 4.8 | |
|---|---|---|
| Default effort | high | high (Anthropic reports similar token cost to 4.7 at this default, with better performance) |
| Available effort levels | xhigh, max available | xhigh, max available |
| Dynamic workflows | Not supported | Research preview on Enterprise/Team/Max |
| Mid-conversation steering | Breaks prompt cache | Supports cache-preserving mid-conversation system messages |
| Fast mode | Available | 2.5× speed, 3× cheaper than previous models |
For most Claude Code users, the default effort behavior is the most directly relevant change — same token cost, better performance per dollar.
API constraints and compatibility
Anthropic's release documentation notes that some 4.7 API constraints carry over to 4.8 — the model isn't a completely fresh API surface. For builders integrating Claude through the API directly (rather than only through Claude Code), check the official API documentation for current request format requirements, supported headers, and any features that have changed status (beta to GA, or vice versa) between 4.7 and 4.8.
Prompt caching continues to work in 4.8 with the additional benefit that mid-conversation system message changes no longer invalidate the cache. Verify the current minimum caching requirements at the official documentation, as these have changed before and may change again.
Benchmark interpretation
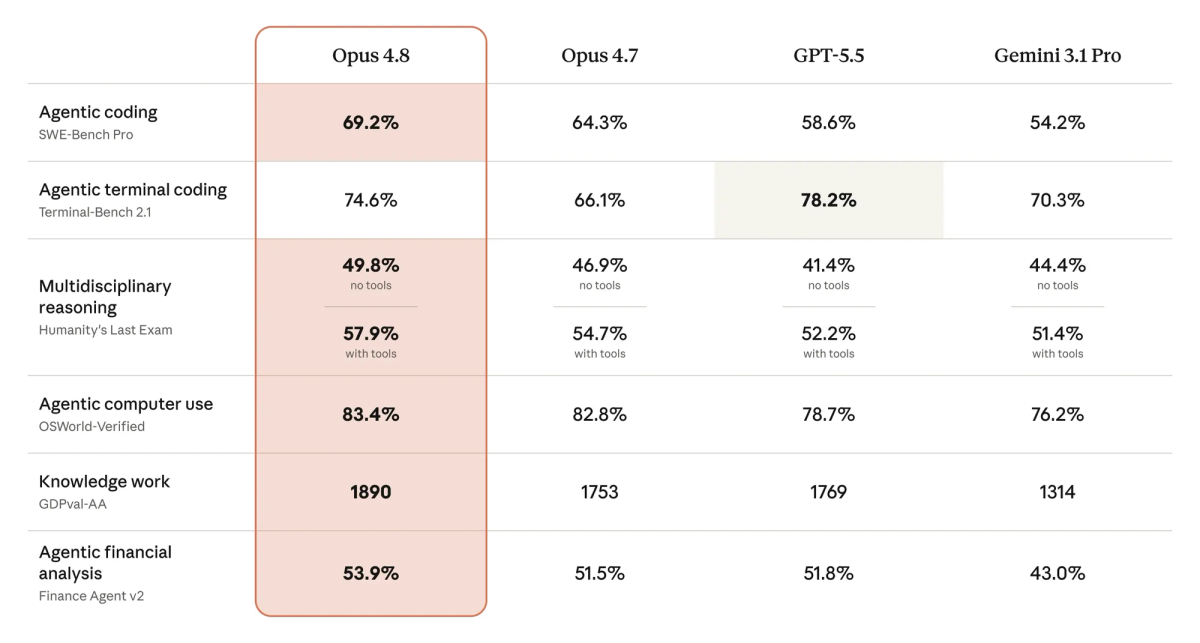
The reported benchmark deltas (Anthropic self-reported):
| Benchmark | Opus 4.7 | Opus 4.8 |
|---|---|---|
| SWE-Bench Pro (agentic coding) | 64.30% | 69.20% |
| Multidisciplinary reasoning with tools | 54.70% | 57.90% |
Source: Anthropic-reported figures via 9to5Mac.
For context: Anthropic reports 4.8 beats GPT-5.5 on at least 12 benchmarks including most knowledge-work, coding (issue-level), agentic tool-use, and long-context categories. GPT-5.5 reportedly leads on terminal/CLI workflows.
These are directional signals from the party releasing the model. The +4.9 point jump on SWE-Bench Pro is the meaningful coding signal because that benchmark has more remaining headroom than SWE-Bench Verified. But none of these scores tell you what will happen on your specific codebase, with your specific conventions, on your actual tasks.
What 4.8 Changes for Coding Agents
Tool triggering improvements
Tool calling is described as meaningfully more efficient in 4.8 — fewer steps for the same result. For coding agents that make many sequential tool calls (read file, write file, run test, read output, iterate), fewer steps means lower per-task cost and faster completion. The practical implication: long agent loops should be cheaper and faster on 4.8 even before counting the model's improved end-task accuracy.
This is also where the honesty improvement compounds. A model that uses tools efficiently AND catches more of its own errors during the loop is a more reliable autonomous agent than one that's only better at one of those things.
Long-context and compaction recovery
Long agent runs accumulate context as tool calls and intermediate reasoning fill the window. How well the model maintains task coherence as context grows — and how cleanly it recovers when the context is compacted to fit within limits — determines how long a session can run before performance degrades.
Anthropic emphasizes 4.8's ability to carry context and style direction across long sessions. For workflows where you'd previously break a task into shorter sessions to avoid context degradation, 4.8 may handle longer runs cleanly enough to consolidate them. Verify this against your own long-session workloads rather than assuming the improvement transfers.
Adaptive thinking behavior
Both 4.7 and 4.8 expose effort controls (high/xhigh/max). What changed in 4.8 is the calibration: Anthropic reports that high effort on 4.8 delivers better performance than high effort on 4.7 at similar token cost on coding tasks. The model adaptively allocates reasoning depth based on task complexity, with the default tuned more efficiently than the previous version.
For builders, this means re-evaluating your effort level choices is worthwhile after upgrading. The xhigh and max settings on 4.7 may be unnecessary on 4.8 for the same task — the new high default may suffice.
What Stays Similar from 4.7
API constraints inherited from 4.7
Several API behaviors carry from 4.7 to 4.8. Beta headers that were required for 4.7 features (task budgets, advanced caching configurations) may have the same requirements in 4.8 or may have moved to GA — check the current API documentation for status.
The model ID changed (you need to update your API calls to point at the 4.8 model ID), but most surrounding integration code should not need significant changes. The migration is more about validating that your prompts still produce expected behavior than about restructuring your integration.
Similar need for effort tuning and workflow testing
Every Opus release has needed local tuning. 4.7 wasn't a drop-in replacement for 4.6; 4.8 isn't a drop-in replacement for 4.7. The high effort default produces different outputs even when the prompts are identical. For workflows where prompt-output alignment matters (e.g., agents that follow specific output formats, structured generation, instruction-tuned tasks), expect to spend testing time validating that your prompts still produce the outputs you depend on.
Same requirement for review and verification
A more capable model doesn't replace diff review. A model that's better at catching its own errors still produces errors that need to be caught by tests, code review, and verification gates. The governance discipline doesn't relax because the model improved. If anything, the longer agent runs that 4.8 enables make verification gates more important — the longer an agent runs autonomously, the more important it is that the checks at the end are correct.
Upgrade Risks for Existing Workflows
Prompt behavior can shift
Subtle changes in how the model interprets prompts are normal across releases. A prompt that worked well on 4.7 may produce slightly different output on 4.8 — the same intent expressed differently, a different structure, a different level of detail. Most of these shifts are minor. Some can break downstream parsing or change agent decision points in ways that matter.
The defense is the same as for any model update: maintain a regression test suite of prompts with expected output characteristics, run it against both 4.7 and 4.8, and review any meaningful divergence before broader adoption.
Agent loops may need re-testing
Multi-step agent loops are particularly sensitive to model behavioral shifts. A loop tuned for 4.7's specific patterns — when it asks for clarification, when it pushes back on a plan, how it decides to use a tool — may behave differently on 4.8. The behavior may be better overall but unfamiliar in specific cases.
For production agent loops, run the upgrade evaluation on representative real tasks, not just smoke tests. The differences that matter often show up only on multi-step tasks similar to your actual workload.
Benchmark wins may not map to your repo
This is the most important risk to internalize. SWE-Bench Pro and similar aggregate benchmarks test against a specific curated set of problems. The 64.3% → 69.2% improvement is real on that benchmark. It does not predict the improvement on your codebase, with your conventions, on your actual tasks.
For some teams, 4.8 will deliver a 5-point improvement on their specific work. For others, the improvement will be smaller, or different in nature (better honesty without better completion rate, for example). The only way to know is to measure on your own workload.
How to Test the Upgrade Safely
Run the same coding tasks on 4.7 and 4.8
The reliable evaluation method: pick 10-20 representative coding tasks from your real work — a mix of bug fixes, feature implementations, refactors, and code review. Run each task on both 4.7 and 4.8 with identical prompts, AGENTS.md / CLAUDE.md, and tool configurations. Compare:
- Did the task complete successfully?
- How many tool calls did it take?
- How many tokens did it consume?
- Did the output pass your tests?
- Did the diff need re-work before merge?
A side-by-side comparison on your actual tasks is more informative than any aggregate benchmark.
Compare diffs, tests, and tool calls
For each test task, capture the specific artifacts:
- Final diff — is it cleaner, more focused, or roughly equivalent?
- Test pass rate — same, better, or worse?
- Tool call count — fewer (efficiency improvement) or similar?
- Honesty signals — did the model flag uncertainties or errors that it would have glossed over before?
The honesty improvement is hard to measure with a single metric. Watch for instances where 4.8 surfaces an issue 4.7 would have ignored — that's a quality signal the benchmark doesn't capture.
Check cost and latency using your own workload

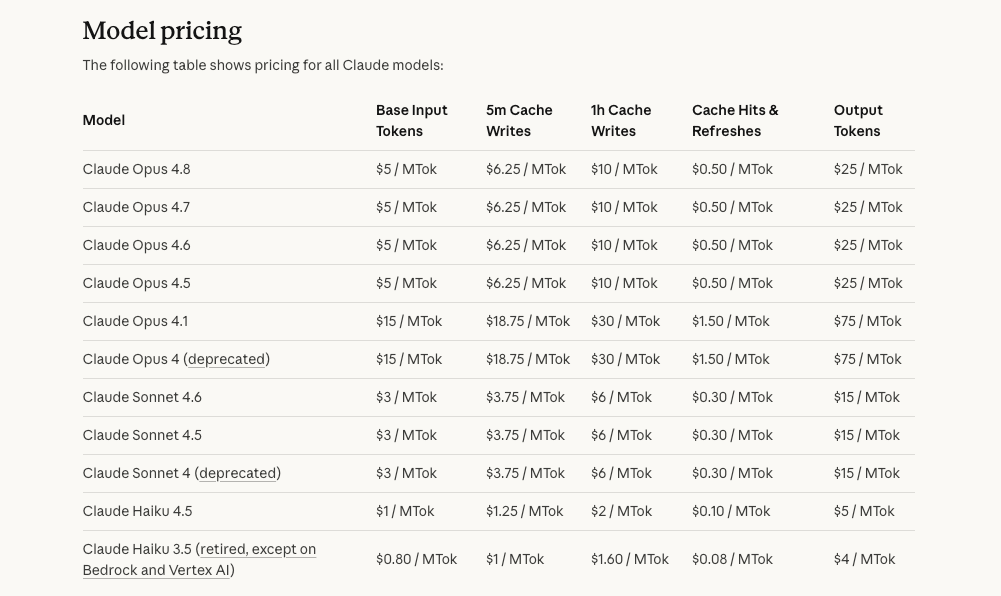
Anthropic prices 4.8 at the same level as 4.7 ($5/$25 per million input/output tokens, per Anthropic's launch). But effective cost per task depends on how many tokens 4.8 actually uses on your work. The default effort is reported to use similar tokens to 4.7's default; xhigh and max use more. Fast mode is 3× cheaper than on previous models but still costs 2× the standard rate per token.
Measure cost per completed task on your representative tasks. If 4.8 completes the same tasks with fewer tool calls and tokens, you save money even at the same per-token rate. If it produces longer outputs at higher effort levels by default, your costs may rise.
For teams running production coding agents at scale, this is worth measuring before broad rollout. The workflow layer where you make these comparisons matters — tools like Verdent's Plan-First execution, parallel worktree isolation, and DiffLens-style review provide consistent measurement structure for evaluating model upgrades by holding the surrounding workflow constant. The model changes; the verification framework doesn't. That's how you can attribute outcome differences to the model rather than to incidental workflow variation.
Where Reddit and Community Feedback Fits
Useful for discovering issues
Reddit threads, Hacker News discussions, and Twitter/X conversations after a major model release surface issues fast: prompt incompatibilities, behavioral regressions in specific use cases, edge cases that broke. The community discovers things in hours that internal evaluation might take weeks to find. Searching "Opus 4.8 Reddit" after launch typically returns concrete bug reports, workarounds, and user experiences that complement official release notes.
This is genuinely useful. If 4.8 has a specific regression on a particular type of task — say, generating SQL with a specific dialect, or following a specific code style — the community will surface it before Anthropic does.
Not a replacement for official docs or local evals
The constraint: community feedback is anecdotal, often based on small sample sizes, and frequently filtered through individual frustration or excitement. A Reddit post saying "Opus 4.8 is worse than 4.7" might reflect a single specific failure case, not the general behavior. A post saying "Opus 4.8 is amazing" might reflect a single positive experience that doesn't generalize.
Use community feedback as a starting list of things to test in your own evaluation — "this Reddit user reported X failed on 4.8, let me check that case on my workload" — not as the basis for the upgrade decision itself. The official release notes tell you what Anthropic changed; your own local evaluation tells you whether those changes help your work.
FAQ
What is the difference between Claude Opus 4.7 and 4.8?
Opus 4.8, released May 28, 2026, is positioned as a "modest but tangible improvement" over Opus 4.7. The main changes: better reported performance on agentic coding (SWE-Bench Pro 64.3% → 69.2%), an approximately 4× reduction in the rate at which the model lets its own code flaws pass unremarked, more efficient tool calling, mid-conversation system message support that preserves prompt caching, 3× cheaper fast mode, and a new dynamic workflows feature in Claude Code (research preview on Enterprise/Team/Max plans). Pricing is the same ($5/$25 per million input/output tokens, per Anthropic's launch). Verify current details at the official announcement.
How should I test Claude Opus 4.8 against 4.7 for coding?
Run a representative set of your real coding tasks — 10-20 cases across bug fixes, feature work, refactors, and review — on both models with identical prompts and configurations. Measure: completion rate, tool call count, tokens consumed, test pass rate, and whether the model flagged its own uncertainties or errors. Compare diffs side by side. The aggregate benchmark numbers don't predict your specific workload; only your own evaluation does. Run this on a non-critical path before broader rollout.
Are Reddit benchmarks reliable for Opus 4.8?
No — at least not as standalone reliable. Community benchmarks on Reddit and similar forums are anecdotal, based on small samples, and often reflect specific use cases rather than general behavior. They're useful for discovering issues quickly (the community surfaces edge cases faster than formal evaluation), but they shouldn't be the basis for an upgrade decision. Use community feedback as a list of things to test in your own evaluation, not as conclusions about the model. The reliable evidence base is the official release documentation plus your local evaluation on representative tasks.
Should Claude Code users upgrade from Opus 4.7 to 4.8?
Most active Claude Code users will likely benefit from upgrading after testing. The reported improvements (better agentic reliability, more efficient tool calling, the new dynamic workflows feature on supported plans, cheaper fast mode) align with how Claude Code is typically used. Hold off if your current 4.7 setup is heavily tuned, if you don't have testing capacity right now, or if your workflow is predominantly terminal/CLI-centric (where Anthropic's reporting indicates GPT-5.5 leads). The reliable path is to test on a side branch before adopting widely.
When should teams keep using Opus 4.7?
Three scenarios: (1) You have a working production deployment that's stable, prompts tuned, and you don't have evaluation capacity to validate the upgrade properly right now — the cost of an under-tested model swap can exceed the benefit. (2) You're on a regulated or compliance-sensitive deployment where any model change requires extensive validation and approval — wait for your formal evaluation process to complete. (3) Your testing reveals 4.8 has a specific regression on workflows that matter to you — stay on 4.7 until the regression is addressed in a future release. In all cases, the staying-on-4.7 decision should be based on evidence from your own evaluation, not on hesitation alone. Consult official documentation for the latest model availability and migration guidance.
Related Reading
