
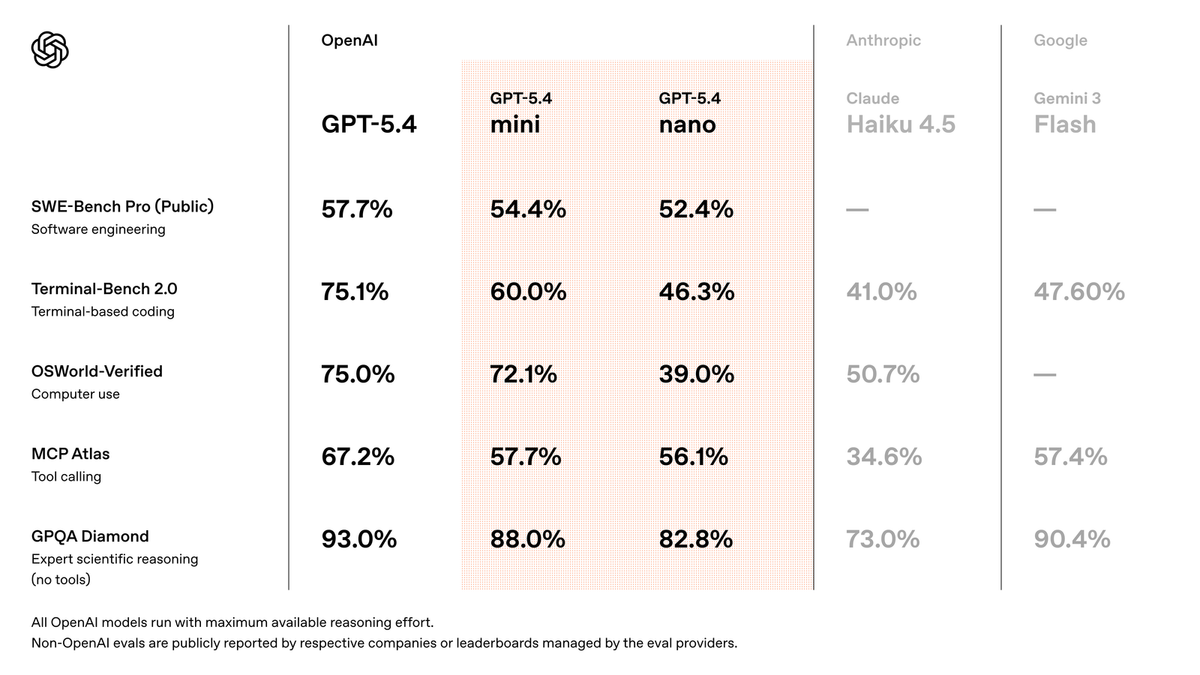
The interesting thing about GPT-5.4 Mini isn't that it's cheaper — it's how little capability you give up for that price. On SWE-Bench Pro, OpenAI reports Mini scoring close to the full GPT-5.4 at roughly a fraction of the cost. For a coding agent that makes hundreds of tool calls per task, that cost-capability ratio is where the real decision lives: when does Mini handle the work well enough that paying for the full model is waste, and when does the task actually need more? Here's the builder's read on where GPT-5.4 Mini fits in an agent loop — and where it doesn't.
Verified against OpenAI's official documentation and reporting as of June 2026. Benchmarks are vendor-reported; pricing and specs change — confirm at the official OpenAI model documentation before building.
GPT-5.4 Mini in One Paragraph
Cost-efficient GPT-5.4 family variant
GPT-5.4 Mini is the cost-efficient, lower-latency variant in OpenAI's GPT-5.4 family — a smaller, faster model that retains much of the full GPT-5.4's reasoning, vision, and tool-use capability at a fraction of the price. It's designed for high-volume workloads where you'd burn through budget running everything on the full model. For coding agents specifically, that profile (cheap, fast, capable tool use) is exactly what the high-frequency parts of an agent loop want.
Released March 17, 2026, 400K context

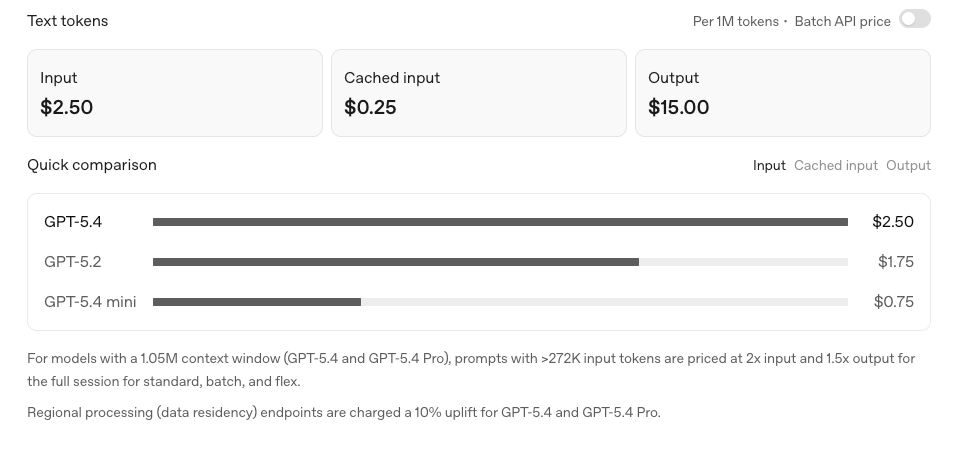
OpenAI released GPT-5.4 Mini on March 17, 2026 — twelve days after the main GPT-5.4 launch. It has a 400K-token context window with up to 128K output tokens, and API pricing of $0.75 per million input tokens and $4.50 per million output. It's available through the OpenAI API and to free-tier ChatGPT users. The model ID is gpt-5.4-mini.
Why It Matters for Coding Agents
Low cost and latency
The core appeal: cost and speed. A coding agent doesn't make one model call per task — it makes many (read a file, propose a change, run a test, read the result, iterate). Each call costs tokens and adds latency, and on a long agentic task those costs compound. Running every call on a full frontier model is expensive and slow; running the high-frequency, lower-complexity calls on Mini cuts both. At $0.75/$4.50 per million tokens, Mini is meaningfully cheaper than the full GPT-5.4 (and far cheaper than flagship models), which matters most exactly where agents spend the most — the many routine calls in a loop.
Tool calling, subagents, computer use
Mini retains the tool-use capabilities that make a model useful in an agent: function calling, tool invocation, and the ability to act (run commands, read results, iterate) rather than just answer. This is what lets Mini serve as a worker in an agent system — handling tool-using subtasks where the reasoning load is moderate but the call volume is high. A common pattern is using a more capable model as the orchestrator and Mini as the subagent that executes the mechanical, tool-heavy work, which keeps cost down without sacrificing the orchestrator's quality on the hard reasoning.
Codex uses ~30% of GPT-5.4 quota
A concrete signal of Mini's positioning: within Codex (OpenAI's coding agent), Mini reportedly consumes roughly 30% of the quota that the full GPT-5.4 would for comparable work. That ratio is the practical case for Mini in an agent loop — you get a large share of the capability for roughly a third of the quota cost. For quota-bound or budget-conscious workflows, that's the difference between a tool you can run all day and one you ration. (Verify current quota behavior in Codex's documentation, as these details change.)
Where Mini Falls Short
Complex reasoning and long-horizon ceilings
Mini is a smaller model, and the trade-off shows on hard reasoning and long-horizon work. For the most complex tasks — intricate architectural reasoning, subtle multi-file logic, long autonomous sessions where coherence has to hold across many steps — Mini hits a ceiling the full model doesn't. It's strong for its size and price, but "strong for its size" is still a ceiling. The failure mode isn't usually a wrong answer on a simple task; it's degraded performance on the genuinely hard parts of a complex task, where the smaller model's reasoning runs out before the problem is solved.
The practical implication: don't route your hardest reasoning to Mini to save cost. The savings evaporate if Mini fails the task and you have to redo it on the full model. Use Mini for the volume of moderate-complexity work and reserve the full model (or a flagship) for the reasoning-heavy core.
Mini vs Full vs Flagship
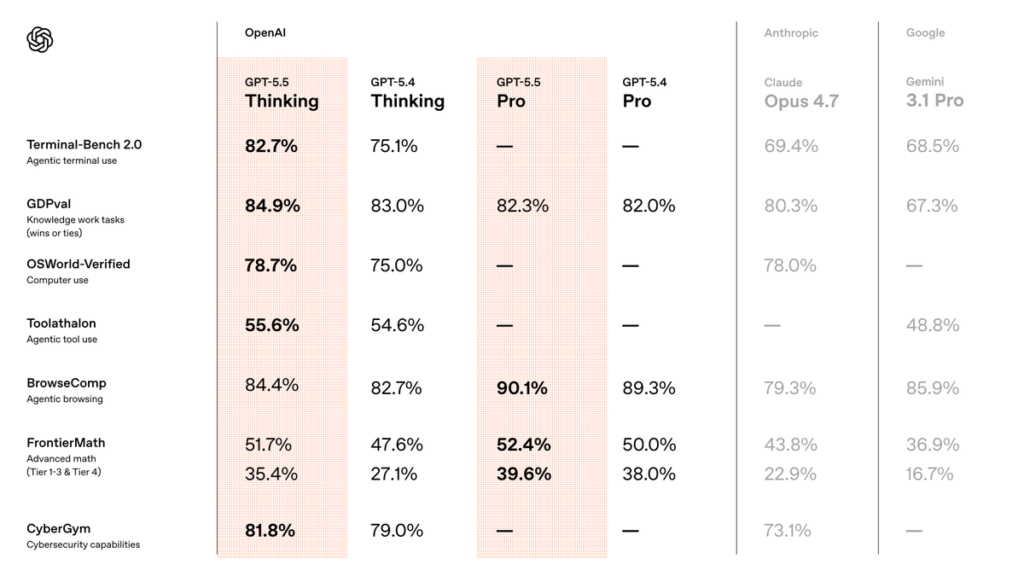
GPT-5.5 now sits above GPT-5.4
A timing note that matters for your decision: GPT-5.4 is no longer OpenAI's flagship. OpenAI released GPT-5.5 in April 2026 as the new frontier model, sitting above the GPT-5.4 family. So the hierarchy is now roughly: GPT-5.5 (flagship, hardest tasks), GPT-5.4 / GPT-5.4 Pro (strong, the prior flagship tier), and GPT-5.4 Mini (cost-efficient variant). When deciding where Mini fits, remember it's a budget variant of a now-superseded flagship — which doesn't make it bad (it's still capable), but it does mean the "full model" above Mini isn't even the current frontier.
Pick by task complexity
The clean decision rule is task complexity, not a blanket model choice. Route routine, high-volume, moderate-complexity work (file reads, simple edits, tool calls, test runs) to Mini for the cost savings. Route the reasoning-heavy core (architecture, complex logic, hard debugging) to the full GPT-5.4 or up to GPT-5.5. A well-built agent system uses the cheapest model that reliably handles each subtask — which means Mini for the volume and a stronger model for the difficulty, not one model for everything.
Who Should Use It
GPT-5.4 Mini fits builders running cost-sensitive or high-volume agent loops who want to cut the cost of the many routine calls without dropping to a model that can't use tools reliably. It fits as the subagent or worker model in a multi-model system, with a stronger model orchestrating. And it fits developers prototyping or working at volume where the full model's cost would be prohibitive and the tasks are mostly moderate-complexity.
It's a poorer fit if your work is dominated by hard reasoning (where Mini's ceiling bites), if you need the current frontier (that's GPT-5.5, not anything in the 5.4 family), or if your volume is low enough that the cost savings don't matter — in which case just use the full model and skip the routing complexity. The honest summary: Mini earns its place in high-volume, mixed-complexity agent loops, not as a universal default.
FAQ
What is GPT-5.4 Mini and how is it different from the regular GPT-5.4?
The cost-efficient, lower-latency variant of GPT-5.4, released March 17, 2026 — a smaller, faster, cheaper model that retains much of the full model's reasoning, vision, and tool-use capability at $0.75/$4.50 per million tokens. The trade-off: Mini is cheaper and faster but has a lower ceiling on complex reasoning and long-horizon tasks. The full GPT-5.4 handles harder work; Mini handles high-volume, moderate-complexity work more economically.
Is GPT-5.4 Mini good enough for coding agents and tool-using workflows?
For a large share of agent work, yes. Mini retains the tool-calling and function-invocation an agent needs, and OpenAI reports it scoring close to the full GPT-5.4 on coding benchmarks (vendor-reported) at much lower cost. It works well as the worker/subagent model for high-volume, tool-heavy, moderate-complexity tasks. Where it falls short is the hardest reasoning and longest-horizon work — route those to a stronger model. The question is matching it to subtask complexity, not whether it can use tools (it can).
How does GPT-5.4 Mini compare to Claude models for coding work?
There's no neutral, same-conditions benchmark to declare a winner, so any comparison should be hedged. Both vendors publish their own benchmarks under their own conditions, which aren't directly comparable. Mini's distinguishing traits are low cost and tight OpenAI-ecosystem integration (Codex, the API tooling); Claude's models have their own strengths and pricing. Rather than trust either vendor's numbers, test both on your actual tasks and compare cost-per-successful-task. The comparison depends on your workload — only your own testing settles it.
Since GPT-5.5 is already out, is GPT-5.4 Mini still worth using?
Yes, for the right role. GPT-5.5 (April 2026) is the new flagship above the entire GPT-5.4 family, but flagship capability isn't what Mini competes on — it competes on cost-efficiency for high-volume work. You'd use Mini for routine, high-frequency calls in an agent loop and reserve GPT-5.5 for the hardest reasoning. GPT-5.5's arrival changes what you route hard tasks to; it doesn't eliminate the value of a cheap, capable model for volume work.
What's the actual context window size for GPT-5.4 Mini?
400K tokens, with a maximum output of 128K tokens. (Some aggregator sites list a larger figure like 1.1M, but the correct context window for GPT-5.4 Mini is 400K — verify against OpenAI's official model documentation, which is the authoritative source.) For most coding-agent work, 400K is ample to hold substantial context; as always, a large window is only useful if the model reasons well across it and the cost is economical, so match your context usage to the task rather than filling the window for its own sake.
Conclusion
GPT-5.4 Mini is best understood as the cost-efficient worker model in an agent system — not a flagship, not a universal default, but a genuinely useful tool for the high-volume, moderate-complexity calls that dominate a coding agent's loop. Its value is the cost-capability ratio: close to the full GPT-5.4's coding performance (vendor-reported) at a fraction of the cost, with the tool-use capability an agent needs. The conservative judgment: use Mini for the volume and route hard reasoning to the full GPT-5.4 or GPT-5.5, picking by task complexity rather than defaulting to one model. And remember it's a budget variant of a now-superseded flagship — capable, well-positioned for its role, but not the current frontier. Test it on your actual agent loop to find where the routing boundary should sit.
Related Reading
