
I've been tracking DeepSeek releases since V3, and April 24, 2026 was the one I'd been waiting for: DeepSeek V4 Preview landed with two new API models, a 1M context window as the default floor, and weights on Hugging Face under MIT. The DeepSeek V4 Preview changes the practical decision for API teams from "wait and see" to "Flash or Pro, which do I test first?" — and it comes at a fraction of GPT-5.5 or Opus 4.7's price. Here's what actually shipped, what the "Preview" label means for your production decisions, and where the open-source SOTA claims hold up versus where they need verification.
What DeepSeek V4 Preview Actually Is
Why "Preview" matters
The word "Preview" in the official release name is not marketing hedging — it's operationally significant. Reuters reported on the launch day that DeepSeek released V4 as a preview and did not provide a finalization timeline. DeepSeek's own API docs carry the same framing.
What Preview means in practice: the API is live, the weights are on Hugging Face, and production-volume testing is possible — but model behavior may change before the final release. For teams building production pipelines, "preview-stable" is the right posture: use it, test it, don't treat it as version-frozen behavior you can rely on without a rollback path.
V4-Pro vs V4-Flash in one paragraph

Both models are MoE (Mixture-of-Experts) and both support a 1M-token context window. The difference is scale and cost. V4-Pro is the flagship: 1.6 trillion total parameters with 49 billion activated per token, designed for complex reasoning, deep agentic coding, and knowledge-intensive tasks. V4-Flash is the efficient tier: 284 billion total parameters with 13 billion activated, built for speed, cost-sensitivity, and agent tasks that don't require V4-Pro's full reasoning depth. DeepSeek explicitly says V4-Flash matches V4-Pro on simpler agent tasks and falls slightly behind on complex ones — so the lineup is not "flagship vs. throwaway"; it's a practical performance-cost split across a spectrum of real workloads.
What Changed for Developers on April 24, 2026
New API model names
The two model IDs that shipped on April 24 are the most operationally immediate change:
deepseek-v4-pro
deepseek-v4-flashBase URL is unchanged. Integrations that previously used deepseek-chat or deepseek-reasoner can migrate by updating the model parameter. New integrations should use the V4 model IDs directly rather than the legacy aliases. From the official DeepSeek V4 release note:
"Keep base_url, just update model to deepseek-v4-pro or deepseek-v4-flash. Supports OpenAI ChatCompletions & Anthropic APIs."
Both models also support three reasoning effort modes (non-thinking, thinking, and a max reasoning mode). Context length is 1M tokens; maximum output is 384K tokens.
1M context as the new default
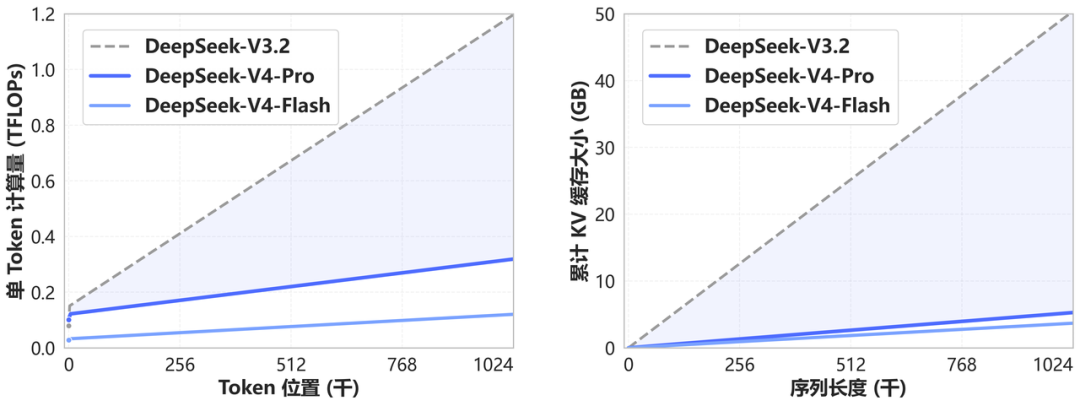
V3.2 shipped with a 128K context window. V4 sets the floor at 1M for both variants. The practical efficiency gain at that scale is meaningful: at 1M tokens, V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache compared to V3.2. V4-Flash pushes those numbers lower still (10% FLOPs, 7% KV cache). These numbers come from the official tech report.
The efficiency improvement is architecturally real: V4 introduces a hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) specifically to reduce long-context costs. For teams doing repo-wide code analysis, long-document ingestion, or multi-step agent workflows with large accumulated context, this is the most meaningful change from V3.2.
Legacy alias deprecation (act before July 24): deepseek-chat and deepseek-reasoner will be fully retired and inaccessible after July 24, 2026, 15:59 UTC. Currently they route to V4-Flash non-thinking and V4-Flash thinking modes respectively. Don't wait until the retirement date to test your migration.
Open weights and Hugging Face release
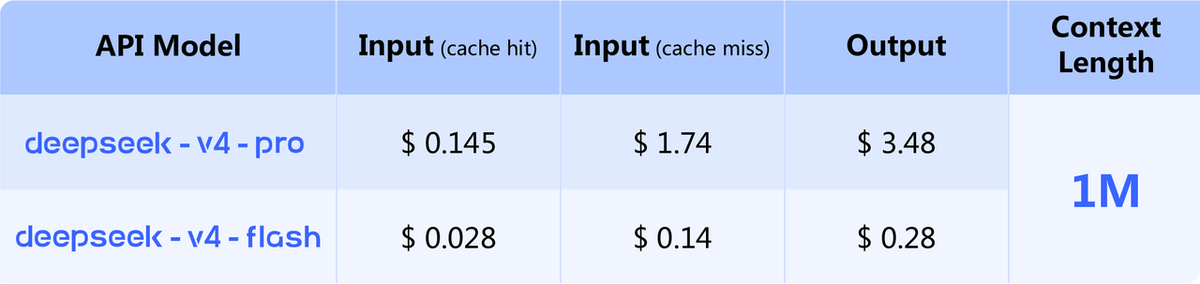
Both V4-Pro and V4-Flash weights are published on the official DeepSeek Hugging Face collection under the MIT license. Storage requirements: V4-Pro is approximately 865GB, V4-Flash is approximately 160GB. The models use FP4+FP8 mixed precision — MoE expert parameters are FP4, most other parameters are FP8.
V4-Pro at 1.6T total parameters is currently the largest open-weight model publicly available, larger than Kimi K2.6 (1.1T) and DeepSeek V3.2 (685B). For most teams, local deployment at this scale is hardware-constrained enough that cloud API access is the practical starting point. But for enterprise compliance requirements, on-premise data processing, or fine-tuning use cases, the open weights under MIT remove the licensing friction that proprietary alternatives carry.
What Changed for Coding Workflows
Agentic coding positioning
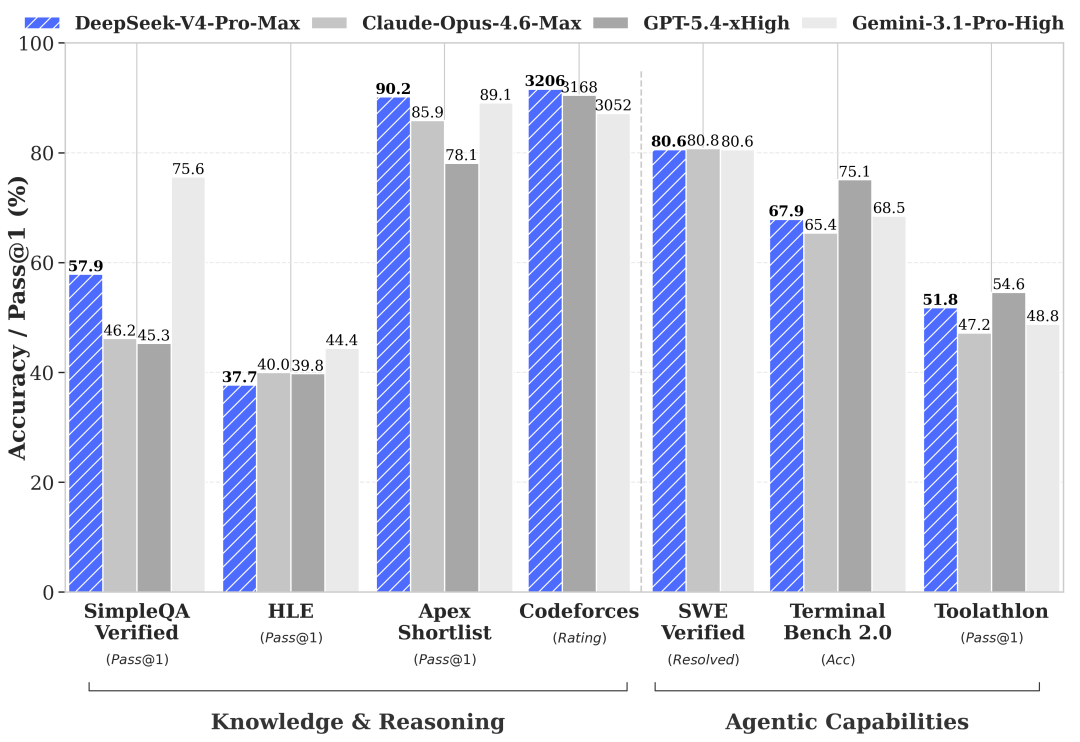
DeepSeek's official release positions V4 around agent capabilities: "Enhanced Agentic Capabilities — Open-source SOTA in Agentic Coding benchmarks." The specific benchmark cited is a Codeforces rating of 3,206 for V4-Pro, placing it at approximately rank 23 among human competitors on that platform. On competitive programming, this is a meaningful result.
However, "open-source SOTA on agentic coding" should be understood in context. On standard benchmarks, V4-Pro sits between GPT-5.2 and GPT-5.4 — not at GPT-5.5 or Claude Opus 4.7 levels. GPT-5.5 scored 82.7% on Terminal-Bench 2.0; Claude Opus 4.7 scored 64.3% on SWE-Bench Pro. DeepSeek has not published equivalent Terminal-Bench 2.0 or SWE-Bench Pro numbers in the preview materials. "Open-source SOTA" is accurate against the open-source field; it does not claim frontier parity with the latest closed models.
DeepSeek also states that V4-Pro has been deployed internally as the company's coding agent of choice, with employee feedback indicating output quality approaches Claude Opus 4.6 in non-thinking mode but trails Opus 4.6's thinking mode. This is a self-reported internal comparison, not an independent benchmark.
Context-heavy repo and doc workflows
The 1M context window changes the calculus for tasks that previously required chunking or RAG to work around context limits. Feeding an entire large codebase, a full documentation set, or months of code history into a single context is now architecturally straightforward — provided your team is working with the API, where the 1M window is fully available. At these context lengths, V4's efficiency advantages over V3.2 (27% of FLOPs at 1M tokens) translate directly into lower cost per long-context call.
For coding agent workflows specifically: the 384K max output token limit is relevant for tasks that generate large code artifacts or extended reasoning traces in max-thinking mode. For multi-turn agentic loops, the context window allows substantially longer accumulated tool-call history before truncation becomes an issue.
Migration impact for existing V3.2 users
Teams currently using deepseek-chat or deepseek-reasoner have a three-month migration window before forced retirement. The migration itself is low-friction: update the model parameter, keep everything else. The behavior change is more significant: you're now calling V4-Flash rather than V3.2. V4-Flash is faster, cheaper at scale, and carries the improved context window — but it's a different model with different behavior characteristics that warrant regression testing before you cut over production traffic.
For teams that relied on deepseek-reasoner for extended reasoning chains: you now have explicit control through three reasoning effort modes on V4-Flash and V4-Pro, rather than a dedicated reasoning model alias. The behavior is more configurable; the prompt tuning may need adjustment.
What Didn't Change or Still Needs Verification
Official claims vs independent validation
The V4 release is four days old as of this writing. No third-party independent benchmark replication has been published. The benchmark numbers in DeepSeek's release materials are:
- Self-reported from DeepSeek's own evaluations
- Compared primarily against other open-source models, not the most recent frontier closed models
- Silent on Terminal-Bench 2.0, SWE-Bench Pro, and other benchmarks prominent in Claude Opus 4.7 and GPT-5.5 evaluations
Treat the launch benchmarks as directional signal. The agentic coding claims are plausible given the architecture improvements, but the magnitude won't be independently verifiable for weeks. If you're building a production evaluation decision, your own workload testing is the relevant benchmark.
What "open-source SOTA" does and doesn't prove
V4-Pro being the best-performing open-weight model currently available is meaningful for teams where self-hosting is a requirement. For teams evaluating cost-quality tradeoffs across the entire model market, the relevant comparison is against closed models at their respective price points.
At $1.74/$3.48 per million tokens for Pro and $0.14/$0.28 for Flash (per the official pricing page), DeepSeek V4 sits dramatically below GPT-5.5 ($5/$30) and Claude Opus 4.7 ($5/$25). If V4-Pro's quality is comparable to models priced 3-4× higher for your specific coding workloads, the cost argument becomes primary. If it's meaningfully behind on task success rate, the effective cost per successful task narrows the gap. The only way to know which applies to you is to run your own workload evaluation.
Who Should Care Right Now

API teams
If you're using any DeepSeek model via API today, the July 24, 2026 legacy alias retirement date is the immediate action item. Start testing deepseek-v4-flash against your current deepseek-chat calls now. Three months is enough time to catch regressions and tune prompts if V4-Flash behaves differently on your workloads — but not if you wait until July.
For teams currently using GPT-5.4 or Claude Opus 4.6 for cost-sensitive coding tasks: V4-Pro at $1.74/$3.48 is worth a direct evaluation against your benchmark tasks. If quality is acceptable, the cost savings are substantial enough to justify the integration effort.
Self-hosted teams
V4-Flash at 160GB is the more accessible self-hosted option. A heavily quantized Flash may run on high-end consumer hardware — a 128GB M-series MacBook Pro is plausible for inference, according to initial community reports, though throughput will be low. V4-Pro at 865GB requires multi-GPU infrastructure; 8× H100 or equivalent is a realistic starting point for production throughput.
The MIT license removes all commercial use restrictions. For teams that need open weights and cannot use closed APIs due to data residency or compliance requirements, V4-Pro is now the strongest available option.
Evaluation-first teams
If you're not currently a DeepSeek user but benchmark all significant model releases: the 1M context + competitive pricing combination makes V4 the most interesting open-weight release since K2.6. The Preview label means behavior isn't finalized, so build your evaluation infrastructure with that expectation — but the API is live, the weights are public, and there's no reason to wait to start testing.
FAQ
Is DeepSeek V4 fully released or still a preview?
Preview. The official release is named "DeepSeek-V4 Preview Release." Reuters reported that DeepSeek did not provide a finalization timeline. The API is live and the weights are publicly available, but model behavior is subject to change before the final release. Treat it as production-testable but not production-frozen.
What is the difference between V4-Pro and V4-Flash?
V4-Pro (1.6T total / 49B active parameters) is the high-capability tier: stronger on complex reasoning, deep agentic tasks, knowledge-intensive coding, and tasks where parameter count matters. V4-Flash (284B total / 13B active) is the efficiency tier: faster, cheaper, comparable to V4-Pro on simpler agent tasks, and slightly behind on complex ones. Both have the same 1M context window and support the same reasoning effort modes. Pricing difference: Pro is approximately 12× Flash on input and output tokens.
Is DeepSeek V4 really built for coding agents?
It's the primary positioning. DeepSeek claims open-source SOTA on agentic coding benchmarks and has deployed V4-Pro internally as its own coding agent. The Codeforces rating (3,206, approximately rank 23 among humans) is a credible competitive programming data point. The gap relative to leading closed models (GPT-5.5, Opus 4.7) on standard benchmarks like SWE-Bench Pro and Terminal-Bench 2.0 is not yet independently established for V4 specifically. "Best open-source coding agent" is plausible; "better than GPT-5.5 for agentic coding" is not yet supported by the launch materials.
Conclusion
DeepSeek V4 Preview landed on April 24 with a clear story for developers: two new API models, 1M context as the default, open weights under MIT, and pricing well below the closed frontier. For API teams, the immediate action is testing the migration from legacy aliases before July 24. For self-hosted teams, V4-Flash at 160GB is the realistic first deployment target. For evaluation-first teams, the combination of open weights, 1M context, and aggressive pricing makes this worth testing now rather than waiting for a finalization date that DeepSeek hasn't announced.
The Preview label is real. Run your own workload benchmarks rather than relying on DeepSeek's self-reported comparisons, and maintain a rollback path until behavior stabilizes.
Related Reading
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
- What Is GPT-5.5 for Coding in 2026?
- What Is Kimi K2.6? Moonshot AI's Open-Weight Agent Model Explained
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
