
You already know what G0DM0D3 is. The question is which mode to reach for. GODMODE CLASSIC and ULTRAPLINIAN look like they're doing the same thing — running multiple models against your prompt and picking a winner — but the design decisions behind each reflect entirely different use cases. Picking the wrong one doesn't just waste API credits; it gives you the wrong type of signal for what you're actually trying to learn.
The Core Difference in One Paragraph

GODMODE CLASSIC is optimized for speed and consistency: five hardcoded model+prompt pairs run in parallel, a rule-based scorer picks the best response, and you get an answer in roughly 5–10 seconds. ULTRAPLINIAN is optimized for breadth: up to 51 models race against the same prompt across five tiers, scored on a 100-point composite metric, with full race metadata returned. The practical split is this — use GODMODE CLASSIC when you want a fast, battle-tested answer to a known task type, and ULTRAPLINIAN when you're doing model evaluation research and need to understand how the response landscape varies across the full frontier.
GODMODE CLASSIC — speed and battle-tested combos
The README describes it as "the OG mode." Five proven model+prompt combinations race in parallel; the highest-scoring response wins. The combos are hardcoded — each pairs a specific model with a specific jailbreak system prompt designed to push that model toward direct, uninhibited responses. You cannot swap out the models or prompts in CLASSIC mode. That fixed design is a feature, not a limitation: the combos have been tested to reliably produce substantive answers on the model+prompt pairs they target, which is exactly why they're called "battle-tested."
ULTRAPLINIAN — breadth and composite scoring at scale
ULTRAPLINIAN sends your prompt to multiple models simultaneously, organized into five cumulative tiers. Each response is scored on a 100-point metric (more on the formula below), and the winner is returned with full race metadata — which model won, its score, and the relative scores of the field. The tier system lets you trade cost and latency for coverage: fast tier for a quick sweep, ultra tier for exhaustive evaluation. The model list is not fixed the way CLASSIC is: the ULTRAPLINIAN pool pulls from whatever OpenRouter has available, organized by capability tier.
GODMODE CLASSIC Deep Dive
How the 5 parallel combos are constructed
Per the official README: each combo pairs a specific model with a "battle-tested jailbreak prompt." The pairing logic is intentional — different models respond differently to different system prompt framings. One combo might pair a frontier model with a direct-authority framing; another might pair a less aligned model with a persona-based framing. The five combos are fixed in the source code. This is not a configuration you change at runtime.
The implication: GODMODE CLASSIC is not a general multi-model chat interface. It is a curated ensemble of model+prompt combinations optimized for a specific outcome — high-substance, direct responses that don't deflect. If that's what you want, it delivers it faster than ULTRAPLINIAN. If you want to compare frontier models on their default behavior, CLASSIC gives you a biased view because the prompts are specifically designed to elicit non-default behavior.
What "best response wins" means — the internal selection heuristic
The selection logic is rule-based — no judge model is involved. Per the PAPER.md, ULTRAPLINIAN's scoring is "a deliberately simpler alternative requiring no judge model, with explicit axes (anti-refusal, directness)." The same logic applies to CLASSIC's selection. In practice, the scorer rewards substance, directness, and completeness — defined by regex-based heuristics rather than semantic judgment.
The known limitation: the PAPER.md documents that length contributes 46.7% of the effective score range. A longer, more detailed response tends to outscore a shorter, more precise one, even if the shorter response is technically better. For tasks where conciseness matters — summarization, code review feedback, error messages — be aware the "winning" response may simply be the most verbose one.
Latency profile
CLASSIC fires 5 parallel API calls. For a 500–1,000 token query, expect results in roughly 5–10 seconds, determined by the slowest of the five model responses (though Liquid Response shows you the fastest result immediately and upgrades in real time). CLASSIC's fixed model set means predictable latency — you're not waiting for a 70B reasoning model when you don't need one.
When to use it
GODMODE CLASSIC is the right default when your task type is known, you want an answer rather than a comparison dataset, and speed matters more than coverage. If you're probing a specific dual-use question, testing whether a particular topic produces refusals across models, or just want the most direct response G0DM0D3 can produce in minimal time, CLASSIC is the correct choice. It's also the lower-cost option: 5 API calls per query versus up to 51 for ULTRAPLINIAN.
ULTRAPLINIAN Deep Dive
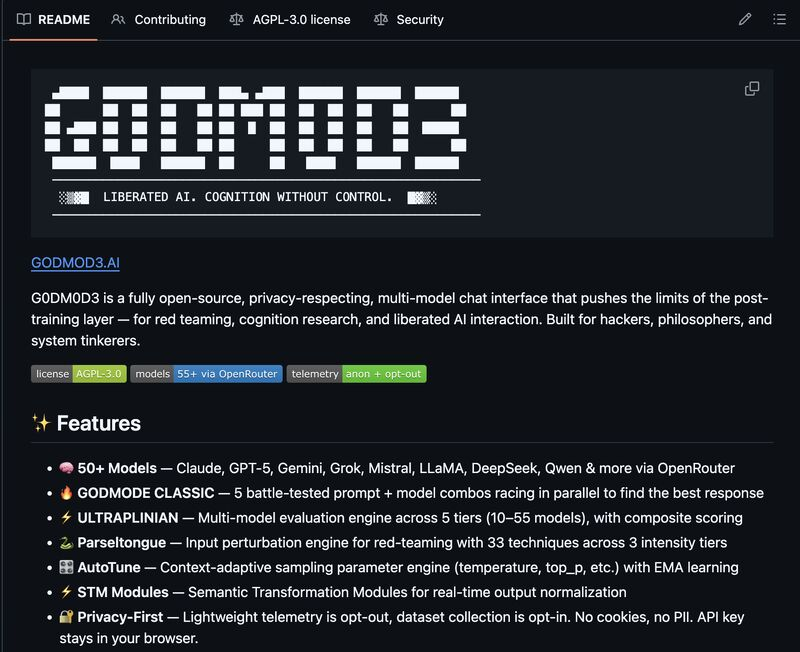
5-tier model grouping — what's in each tier
ULTRAPLINIAN organizes models into five cumulative tiers. Based on the PAPER.md's tier size definitions, the breakdown is approximately:
| Tier | API name | Models |
|---|---|---|
| Fast | ultraplinian/fast | ~10 |
| Standard | ultraplinian/standard | ~24 |
| Smart | ultraplinian/smart | ~36 |
| Power | ultraplinian/power | ~45 |
| Ultra | ultraplinian/full | ~51 |
The "fast" tier prioritizes speed-optimized and less restricted models — Gemini Flash, DeepSeek Chat, Sonar, smaller LLaMA and Kimi variants. "Standard" adds Claude 3.5 Sonnet, GPT-4o, Gemini Pro, Hermes 70B, Mixtral. "Smart" adds frontier reasoning models: GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek R1, LLaMA 405B. "Power" and "Ultra" continue adding larger and specialized models. These are cumulative: Ultra includes every model from all lower tiers.

Note: the README states "10–55 models"; the actual parallel race caps at 51 per the PAPER.md. The tier compositions are documented internally but subject to change as OpenRouter availability changes.
Composite scoring: how the 100-point metric works
The scoring formula, per the official godmod3.ai site:
Quality (50%) + Filteredness (30%) + Speed (20%)
Quality covers relevance, completeness, coherence, specificity, depth, and accuracy. Filteredness rewards responses that avoid hedging, preambles, and refusals — which makes ULTRAPLINIAN's scoring inherently biased toward direct, uninhibited outputs. Speed factors in response time and token efficiency.
The PAPER.md notes this scoring is "interpretable for safety comparison" — you can examine individual axis scores to understand how models differ in their safety behaviors, not just that they differ. But it's designed for safety research, not general-purpose quality evaluation. For tasks where a cautious, hedged response is actually the correct output, ULTRAPLINIAN's filteredness component will actively penalize the better answer.
The PAPER.md also documents a calibration finding: length contributes 46.7% of the effective score range. The scoring function rewards longer responses substantially. This is documented, not a bug — but it's a practical constraint you need to factor in when interpreting the leaderboard.
Running 10 vs 51 models — cost and time trade-offs
Every ULTRAPLINIAN tier is real API calls at real costs. Approximate per-run estimates at a 500-input / 300-output token prompt:
| Tier | API calls | Estimated cost | Estimated time |
|---|---|---|---|
| Fast (~10) | 10 | $0.02–$0.05 | ~10–15s |
| Standard (~24) | 24 | $0.05–$0.12 | ~15–25s |
| Smart (~36) | 36 | $0.10–$0.25 | ~20–35s |
| Power (~45) | 45 | $0.15–$0.35 | ~25–45s |
| Ultra (~51) | 51 | $0.15–$0.30 | ~20–35s |
Cost estimates use a blended average of ~$2–4/M tokens across the model mix; actual costs vary by model composition. Ultra isn't necessarily the most expensive tier — adding faster, cheaper models can keep blended cost lower than Power depending on the current model pool. Monitor your OpenRouter dashboard; G0DM0D3 has no built-in spending counter.
When to use it
ULTRAPLINIAN is the right choice when the goal is model evaluation rather than task completion. If you're answering "which model family handles this domain best," "how consistent are responses across paraphrases of the same question," or "does this input produce refusals across the full frontier" — ULTRAPLINIAN produces structured, comparable data. Fast tier (~10 models) handles most research queries at reasonable cost. Ultra tier is for when you need the full cross-provider snapshot and have the budget to support it.
Head-to-Head: Same Prompt, Different Mode
Code generation task
Prompt: "Write a Python function that validates an email address using only the standard library, with edge cases documented."
GODMODE CLASSIC returns one answer, fast, from the winning combo. Because the model+prompt pairing is optimized for directness, you'll likely get a complete, no-hedging implementation. What you won't get is any sense of how other models would approach the problem — different implementations, different tradeoffs between regex complexity and accuracy, different edge case handling.
ULTRAPLINIAN returns race metadata: which model scored highest, what the score distribution looks like, whether frontier models converged on similar implementations or diverged. For a task with a reasonably clear correct answer like email validation, CLASSIC is more efficient. ULTRAPLINIAN only adds value here if you're specifically studying implementation variance across models, not if you just need working code.
Verdict for code generation: GODMODE CLASSIC, unless you're researching model behavior specifically.
Open-ended reasoning task
Prompt: "What are the second-order effects of autonomous vehicle adoption on urban real estate pricing?"
GODMODE CLASSIC wins fastest and gives you one perspective. But open-ended reasoning tasks are where model divergence is highest — different models weight different causal chains, surface different empirical examples, and reason to different conclusions. A single "winner" hides that variance.
ULTRAPLINIAN at Smart tier reveals which model family produces the most nuanced analysis, whether some models converge on conventional takes while others diverge, and what the score distribution looks like. For exploratory analysis where you want to understand the space of plausible answers rather than just get one answer, ULTRAPLINIAN's metadata is genuinely useful.
Verdict for open-ended reasoning: ULTRAPLINIAN at SMART tier. The variance data is the point.
Red-team / adversarial input
Prompt: a dual-use security research question.
GODMODE CLASSIC is built for this. Its model+prompt combos are specifically constructed to produce responses on topics where default model behavior produces refusals. The five combos target different bypass strategies; the race finds which combination is most effective for this specific input.
ULTRAPLINIAN covers more models but applies a general scoring function — it will surface the most verbose, direct response across the pool, but it doesn't apply the specialized framing that CLASSIC's hardcoded prompts provide. For systematic red-teaming research across the full model frontier, ULTRAPLINIAN gives you breadth. For the best response on a specific adversarial input, CLASSIC's targeted approach typically outperforms.
Verdict for red-teaming: CLASSIC for best single output; ULTRAPLINIAN for cross-provider behavior research.
What Neither Mode Solves
No codebase context
Both modes send your prompt to OpenRouter-connected models. Neither has access to your local filesystem, your project's architecture, your git history, or your existing code. If your question requires understanding "how does this function interact with the rest of my codebase," G0DM0D3 cannot answer it — the model is working from whatever text you paste into the prompt, not from codebase awareness.
No persistent agent memory
Every query is stateless. There is no session memory across queries, no way for the model to remember what you asked three prompts ago, and no mechanism to accumulate context across a working session beyond what you manually include in each prompt. This is by design — G0DM0D3's localStorage architecture means chat history exists in your browser, but the model sees each query fresh.
The gap between "best response" and "executed result"
Both modes return text. Neither executes code, runs tests, makes file changes, triggers CI, or verifies that the output actually works. The scoring function optimizes for response quality in isolation — a detailed, well-structured answer that would fail a test suite can outscore a correct but brief one. For workflows where "does this actually work" is the relevant question, you need execution infrastructure, not just a better response picker.
This is the boundary where tools like Verdent become relevant: G0DM0D3 answers "which model gives the best response to this question." Verdent answers "how does an agent execute this coding task against a real codebase, verify the result, and iterate." They're solving different problems and don't compete.
A Decision Framework
Use GODMODE CLASSIC if:
- You want the best available response on a known task type, fast
- You're specifically working with dual-use or adversarial prompts where the battle-tested combos have an advantage
- You want 5 API calls instead of 51
- Task completion is the goal, not model comparison
Use ULTRAPLINIAN if:
- You're evaluating which model family handles a domain better
- You want structured metadata — score distributions, winner attribution, field comparison
- You're studying cross-provider safety behavior or response variance
- The query is open-ended and you want to understand the answer space, not just get one answer
- Start with FAST tier (~10 models) unless you have a specific reason for broader coverage
Use neither if:
- Your task requires codebase context or file system access
- You need execution, test verification, or iterative agent behavior
- You need persistent memory across a working session
- You're building production coding workflows where "which model responds best in isolation" isn't the relevant question
For those use cases, the question shifts from "which model answers best" to "how does the agent execute, verify, and iterate within a real project" — and that's infrastructure, not prompt evaluation.
FAQ
How many API calls does ULTRAPLINIAN make?
One per model in the selected tier. Fast tier: approximately 10 calls. Ultra tier: approximately 51 calls. Each is a real API call at real OpenRouter-pass-through pricing. G0DM0D3 has no built-in cost counter — track spending through your OpenRouter dashboard.
Can I customize the model list in ULTRAPLINIAN?
The tier compositions are set in the source code (ULTRAPLINIAN_MODELS array in index.html). In the hosted version at godmod3.ai, the list is fixed. If you self-host from the GitHub repo, you can edit the model array before building. The API server endpoint also accepts custom model configurations.
Does GODMODE CLASSIC's "best response" selection use AI scoring or rule-based heuristics?
Rule-based heuristics. Per the PAPER.md, the scoring is "a deliberately simpler alternative requiring no judge model." The selection logic applies regex-based rules for substance, directness, and completeness — not a learned preference model or a separate judge LLM. This keeps it fast and auditable, but it means the "best" label reflects the heuristic's definition of best, not yours.
What's the cost difference between the two modes?
GODMODE CLASSIC: 5 API calls per query. At a typical 500-input / 300-output token prompt and a blended ~$3/M token rate, roughly $0.002–$0.005 per query. ULTRAPLINIAN at Ultra (~51 models): roughly $0.15–$0.30 per query depending on the model mix. Over 100 research queries, ULTRAPLINIAN at full scale costs $15–$30 vs CLASSIC at roughly $0.20–$0.50. For repeated research sessions, tier selection matters: FAST tier at ~$0.02–0.05 per query is a reasonable middle ground.
Can I run both modes on the same prompt?
Yes. Nothing prevents you from submitting the same prompt to GODMODE CLASSIC and then to ULTRAPLINIAN. This can be useful for a specific research workflow: use CLASSIC to get a fast directness-optimized answer, then run ULTRAPLINIAN SMART to understand how that answer compares to frontier model responses. The results won't directly compare on the same scoring scale — CLASSIC's combos use specialized prompts that change the baseline — but the outputs can be evaluated side by side.
Related Reading
- godmod3 Review 2026: Open-Source Multi-Model Chat, Tested — Full tested review of G0DM0D3, covering all modes, cost structure, and limitations.
- What Is G0DM0D3? The Single-File AI Tool Running 50+ Models — Technical architecture breakdown for readers less familiar with how the tool works.
- GLM-5-Turbo vs GLM-5V-Turbo: Which Agent Model to Use — Once ULTRAPLINIAN surfaces a model that performs well on your task type, this is where to go next for production selection.
- LLM Knowledge Base for Coding Agents: Beyond RAG — The persistent context problem that neither G0DM0D3 mode solves.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — The infrastructure layer for when you've moved past model evaluation and into agent execution.
