
Andrej Karpathy released autoresearch on March 7, 2026. Within a month it had over 66,000 GitHub stars and 9,600 forks. Fortune dubbed the underlying methodology "The Karpathy Loop." Most of the coverage described it as "AI doing research while you sleep," which is accurate but leaves out the parts that matter for engineers: what the loop actually does, why git rollback is the core mechanism, and what this pattern can and can't be applied to. This is a technical description of the system.
What AutoResearch Is
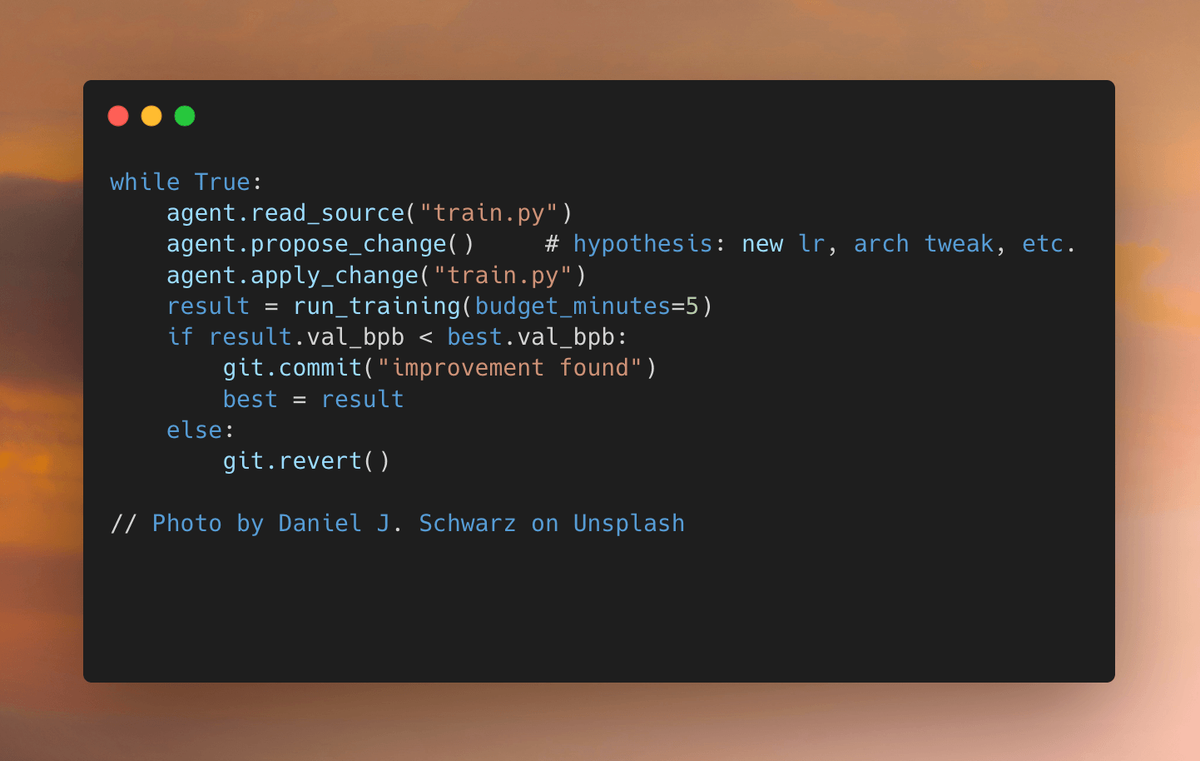
AutoResearch is an autonomous ML experimentation loop. A coding agent — Claude Code, Codex, or any equivalent — is pointed at a minimal LLM training setup and given a Markdown instruction file. The agent then runs an indefinite loop: read the training code, propose a change, run a 5-minute training job, measure whether the result improved, commit the change if it did, roll it back if it didn't, repeat. No human interaction required. You set it running at night, and in the morning there's a git history of validated experiments and a log of everything that was tried.
The codebase it operates on is a stripped-down single-GPU LLM training implementation called nanochat — the key file, train.py, is ~630 lines of Python. The scope is deliberately small: one file, one GPU, one metric.
The Event: 66K Stars in Weeks
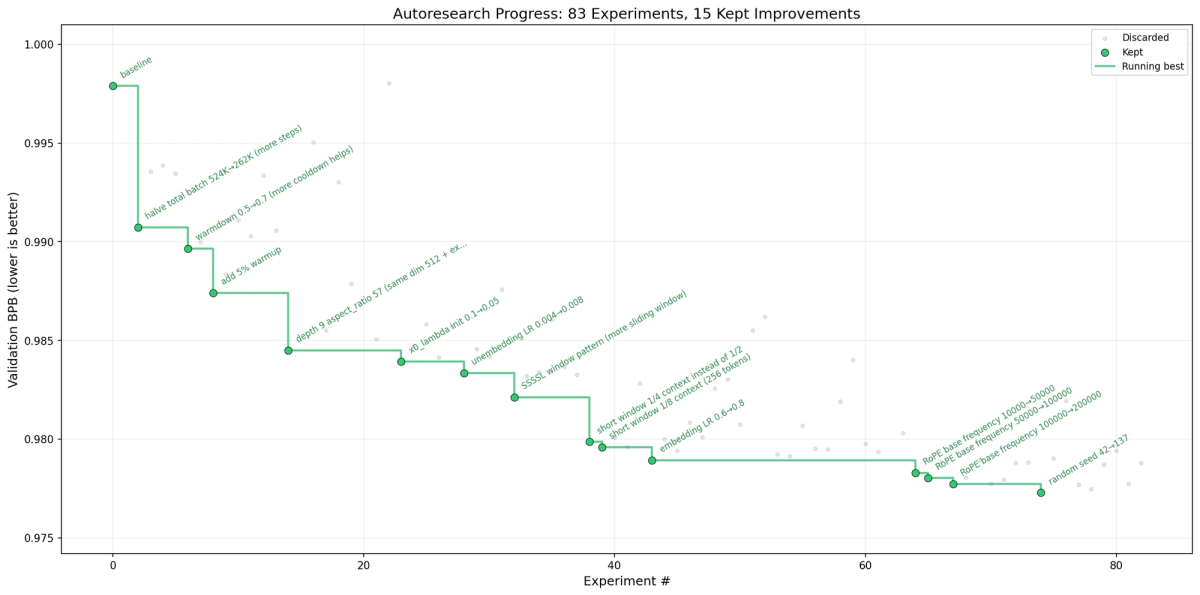
The scale of community response was notable: 66,000+ GitHub stars and 9,600 forks as of early April 2026 (source: GitHub Issues page, April 3, 2026). VentureBeat's coverage reported that Karpathy's own two-day extended run produced 700 experiments, with the agent stacking 20 additive improvements that dropped the "Time to GPT-2" benchmark from 2.02 hours to 1.80 hours. The awesome-autoresearch curated list already tracks dozens of forks and derivative projects applied to domains outside ML.
What Makes It Different from a Script
A standard automation script for ML experiments would need to define the search space explicitly: try these hyperparameters, try these architectures, in this order. AutoResearch doesn't. The agent reads the code, forms a hypothesis using its own knowledge of deep learning literature, makes a targeted code change, and evaluates the result. The search space is whatever the agent can think to try. Karpathy baked one additional criterion into the instructions: a tiny improvement that adds ugly complexity isn't worth keeping, but deleting code while maintaining performance is always a win. This is a research philosophy, not an algorithm.
How the Core Loop Works
program.md as the Only Human Input
The human's entire contribution to the running system is a Markdown file: program.md. This file tells the agent what it's allowed to modify (only train.py), what it must never do (modify prepare.py, which handles data and evaluation), how to interpret results, how to handle crashes, and — in all caps — NEVER STOP. The exact phrasing from the official program.md:
"Once the experiment loop has begun (after the initial setup), do NOT pause to ask the human if you should continue. Do NOT ask 'should I keep going?' or 'is this a good stopping point?'. The human might be asleep, or gone from a computer and expects you to continue working indefinitely until you are manually stopped."
There are no state graphs, no orchestration frameworks, no tool schemas. The "agentic loop" is English text. The agent's context window is the state machine. Git is the version control and rollback mechanism. This is a design bet that a sufficiently capable LLM, given clear written instructions and the ability to run code, doesn't need additional scaffolding.
Code Mutation — What the Agent Actually Changes
Everything in train.py is in scope: model architecture, optimizer choice, hyperparameters, training loop logic, batch size, learning rate schedule. The agent proposes a change with explicit reasoning, applies it directly to the file, and runs the experiment. The constraint is that prepare.py is read-only — this file contains the evaluation function (evaluate_bpb), data loading, tokenizer, and the time budget constant. Keeping evaluation outside the agent's write access preserves the integrity of the metric.
The validation metric is val_bpb: validation bits per byte. It's computed by dividing token-level cross-entropy (in nats) by the total byte length of the target text and converting to bits. The metric is vocabulary-size-independent, which matters because the agent might try different tokenizer configurations. Lower is better.
Ratchet Loop — How Git Rollback Ensures One-Way Improvement
This is the mechanism that makes AutoResearch work. The agent runs on a dedicated git branch. After each experiment:
- If
val_bpbimproved (lower): the change is committed. It becomes the new baseline. - If
val_bpbis equal or worse:git resetreverts the change instantly. The codebase returns to exactly where it was.
The name "ratchet" is precise: the codebase can only move in one direction. Every committed change is a validated improvement; no regression ever persists. The git history is also the audit trail — you can review every successful experiment in the morning and understand exactly what the agent changed and why.
The ratchet design has a known structural limitation: the agent can't take a step backward to set up a larger gain later. Human researchers routinely reason that a change will hurt performance in the short term but enable a bigger improvement downstream. The ratchet prevents this. It's an optimization pressure that finds local improvements reliably, not one that explores broadly.
Fixed 5-Minute Budget: Why Time Not Epochs
Every experiment trains for exactly 5 minutes of wall-clock time, regardless of what the agent changes. Whether it tries a small model with a huge batch size or a large model with fewer steps, the time cost is identical. This creates two properties:
First, experiments are directly comparable. Architecture changes, optimizer changes, and hyperparameter changes are all evaluated on the same basis.
Second, the system finds the optimal model for your specific hardware. An H100 and a consumer GPU will produce different results — the agent discovers what works best on the machine it's running on, not what works best on paper.
The tradeoff is that results aren't comparable across machines. If Karpathy runs AutoResearch on an H100 and you run it on a 3090, the winning configurations will differ, and the val_bpb numbers can't be directly compared.
What It Can and Can't Do
Single GPU Limitation
The current repository requires a single NVIDIA GPU, explicitly tested on H100. This is stated in the README without qualification: "This code currently requires that you have a single NVIDIA GPU." CPU, MPS (Apple Silicon), and AMD GPU paths are mentioned as "in principle possible" but not implemented, and adding them would "bloat the code." Community forks exist for lower-compute platforms — the README links to several — but those are not the main project. If you're on a MacBook or a non-NVIDIA machine, you're using a fork, not the canonical codebase.
Why It's Not AutoML
AutoML systems like Optuna, Ray Tune, or NAS frameworks work by searching a predefined configuration space. You specify which hyperparameters to tune and what ranges to explore, and the system runs through combinations, often with principled sampling strategies like Bayesian optimization. AutoResearch does something structurally different: the agent proposes code changes using its knowledge of the ML literature. There's no predefined search space. The agent can propose adding a new optimizer, changing the attention mechanism, refactoring the training loop, or removing code entirely. It's an open-ended search in code space, not a constrained search in parameter space.
This also means AutoResearch has none of AutoML's theoretical guarantees. AutoML with Bayesian optimization has provable properties about convergence given enough samples. AutoResearch has no such properties — it depends on the LLM's knowledge and reasoning, which can be wrong, biased, or stuck in local patterns.
What "Bundle Cleanly" Doesn't Mean
Karpathy's results from extended runs (source: GitHub README) showed the agent finding improvements including a missing QKnorm scaler, value embedding regularization, and AdamW beta parameter tuning. These are real code changes that transferred to a larger model. What the agent didn't do: invent a novel attention mechanism, propose something outside the space of things an ML researcher would have eventually tried, or produce improvements that required reasoning across multiple experiments rather than within a single change. The ratchet loop, by design, prevents multi-step reasoning. Each change has to win on its own.
Why This Matters for AI Coding Engineers
From Execution to Goal-Setting
AutoResearch is the clearest current example of a shift Karpathy has been describing in his public writing: the human's role in AI-assisted development moving from code author to goal-setter. In standard agentic coding (Claude Code, Verdent, Cursor), the human is still orchestrating — watching what the agent does, providing corrections, redirecting when it goes wrong. AutoResearch removes even that. The human writes program.md, starts the loop, and leaves. The agent makes decisions indefinitely without check-ins.
This only works because the problem is tightly constrained: single file, single metric, single GPU, binary keep-or-revert decision. The moment the scope expands, the reliability of "NEVER STOP" becomes a different kind of bet. But within that constraint, it demonstrably works.
What program.md Tells Us About Human-AI Contracts
The most technically interesting thing about AutoResearch isn't the loop — it's that the loop is defined in English. program.md is a document that specifies a complete research methodology: what to modify, what to leave alone, how to evaluate, how to handle failure cases, and a blanket prohibition on asking for help. A coding agent reads this document and executes it indefinitely.
The implication for engineering teams is concrete: the quality of autonomous agent behavior scales with the quality of the document that specifies its behavior. Not the orchestration framework. Not the scaffolding. The written specification. This is different from how most teams think about agent reliability — which defaults to adding more framework complexity, more guardrails, more error handling code. AutoResearch suggests a different lever.
FAQ
Is AutoResearch Open Source?
Yes. The repository is at github.com/karpathy/autoresearch under the MIT license. All three core files (train.py, prepare.py, program.md) are public and directly readable. The project has no commercial component and Karpathy has not announced any plans to commercialize it.
What Hardware Do I Need?
The canonical setup requires a single NVIDIA GPU. The README says it was "tested on H100" but doesn't restrict to H100 — consumer NVIDIA GPUs work with appropriate configuration adjustments (lower model size, shorter sequence length). For non-NVIDIA hardware, you'll need one of the community forks, which may behave differently and are not maintained by Karpathy. No cloud account or API key is needed — it runs locally. You do need a coding agent (Claude Code, Codex, or similar) to run the loop, which may have its own cost or subscription requirements.
Can It Be Used for Software Engineering Tasks, Not Just ML?
Community forks and derivatives have extended the pattern. The awesome-autoresearch curated list includes forks applying the ratchet loop to prompt optimization, coding skill improvement, and general software performance benchmarks. These adaptations share the same structural requirement: a single file to modify and a measurable scalar metric. The constraint is the metric, not the domain. If you can define a numerical objective that a training run (or any repeatable process) produces, the loop applies. If your task can't be reduced to a measurable scalar, it doesn't.
Is It Production-Ready?
AutoResearch is a research tool and explicitly described as such. It has no authentication, no error recovery beyond what program.md specifies, and results that are platform-specific. The README README notes that "Codex doesn't seem to work" due to the agent not following the "NEVER STOP" instruction — reliability depends on the coding agent being used. Community forks add production-grade features like dashboards, resumability, and multi-GPU support, but those are third-party projects. For production ML workflows at scale, AutoResearch is a pattern to adapt, not a system to deploy directly.
Where AutoResearch Fits in the Broader Stack
AutoResearch is a narrow tool for a specific problem: autonomous code improvement against a fixed, measurable objective. It's not a general coding agent. It doesn't have persistent memory, codebase understanding across multiple files, or the ability to take direction mid-run. For work that requires those capabilities — multi-file changes, IDE integration, project-level context — tools like Claude Code or Verdent's multi-agent worktree setup are the right layer. AutoResearch is what you run after you've built the system and want to let an agent iterate on it overnight.
If you're building the kind of measurable objective function that AutoResearch needs, the LLM knowledge base pattern discussed in LLM Knowledge Base for Coding Agents is relevant — using accumulated project context to inform what the agent should prioritize. The two patterns are complementary: structured context for the agent, measurable evaluation for the loop.
Related Reading
- LLM Knowledge Base for Coding Agents: Beyond RAG — The persistent context layer that gives agents the project knowledge AutoResearch deliberately omits.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — The coding agent tools that run the AutoResearch loop, and how they differ on parallel execution.
- Claude Code Auto Mode and Cloud Auto-Fix — Claude Code's autonomous execution features — the agent layer AutoResearch is built on top of.
- What Is G0DM0D3? — Another community-built research tool with a different approach to autonomous AI evaluation.
- GLM-5V-Turbo: Z.ai's Vision Coding Agent Explained — An alternative model family that can be used as the coding agent running AutoResearch loops.
