
A million tokens of context sounds like the answer to every large-codebase problem — load the whole repo, let the model reason over all of it, done. SkyClaw-v1.0, Skywork AI's "Million-Context Agent Model at Ultra-Low Cost," released in May 2026, is built around exactly that premise. But the gap between "can hold a million tokens" and "reasons correctly over a million tokens" is where the actual engineering question lives. This article looks at what long-context agent models like SkyClaw mean for coding agents — and where context length stops being the thing that matters.
Based on Skywork AI's release information, current at May 29, 2026. All benchmark figures are Skywork self-reported. Verify current capabilities, pricing, and availability at the official SkyClaw page before making decisions.
SkyClaw-v1.0 in One Paragraph
A long-context agent model from Skywork
SkyClaw-v1.0 is an agent model from Skywork AI (Kunlun Wanwei), positioned as a million-context model optimized for agent workflows at low cost. It ships in two variants: SkyClaw-v1.0 (the main model) and SkyClaw-v1.0-lite (a faster, lower-cost variant). According to Skywork, the model is optimized for the OpenClaw, Hermes, and Nanobot agent frameworks, with a focus on complex tool use and multi-turn task execution. It was trained around practical agent behavior: complex tool environments, filtered synthetic trajectories, and end-to-end reinforcement learning aimed at more stable multi-step execution. Skywork has launched a free trial period and stated it will progressively open-source each model version.
Why agent builders are paying attention
Two things draw builder attention: the context length and the cost positioning. A million-token context window is large enough to hold substantial codebases, long documents, or extended multi-turn agent histories in a single reasoning loop. The "ultra-low cost" framing — Skywork positions it below the price of comparable models — makes long-context agent work economically viable for high-volume use where premium frontier models would be cost-prohibitive.
For builders evaluating the agent model landscape, SkyClaw is a data point in a broader trend: agent-specialized models trained specifically for tool use and multi-step execution, rather than general-purpose models adapted to agent tasks. Whether that specialization translates to better outcomes on your specific work is the question this article keeps returning to.
What Long-Context Agent Models Change
More project context in one reasoning loop
The most direct effect of a large context window is that more information fits into a single reasoning pass. For coding agents, this means a model can hold more files, more documentation, and more of the task history in context simultaneously — without the agent having to repeatedly retrieve and re-load information across turns.
For tasks that genuinely require understanding relationships across many files — a refactor that touches interconnected modules, a migration that needs to maintain consistency across a large codebase — having more of the relevant code in context at once can reduce the errors that come from the model losing track of code it processed earlier and discarded.
Better fit for docs, repos, and multi-step tasks
Long-context models fit a specific shape of task: ones where the relevant information is large but needs to be reasoned over holistically. Reading a long technical specification and implementing against it, analyzing a large log file to find a pattern, understanding a codebase's architecture before making a change — these benefit from the model being able to take in the full context rather than working from fragments.
Multi-step agent tasks also accumulate context as they run: each tool call adds output, each reasoning step adds tokens. A larger context window means a longer agent loop can run before hitting the limit that forces compaction or truncation — which can mean more coherent long-running sessions.
Why context length does not guarantee correctness
Here's the part the "million context" headline obscures: holding information in context is not the same as reasoning correctly over it. A model with a million-token window can still misunderstand the code it's looking at, draw the wrong conclusion from a document, or apply a correct piece of context to the wrong part of the task.
Research on long-context models has consistently shown that effective use of context degrades well before the maximum window size — models attend more reliably to information at the beginning and end of a long context than to information buried in the middle. A large advertised context window doesn't guarantee the model uses all of it equally well. For builders, this means the context length is a ceiling on what's possible, not a guarantee of what's reliable. The only way to know how well a model uses its context on your work is to test it on your work.
What This Means for Coding Agents
Large codebase understanding
The appeal for coding agents is loading more of a codebase into context for tasks that need cross-file understanding. Instead of an agent reading files one at a time and reconstructing relationships from fragments, a long-context model can take in many related files at once and reason about how they connect.
The caveat from the previous section applies directly: a model that can hold the codebase in context hasn't necessarily understood it. The middle of a large context — which, in a big codebase load, is most of the code — is where attention reliability degrades. Test whether the model actually reasons correctly about code in the middle of a large load, not just code at the edges.
Cross-file reasoning and refactor planning
Refactors that span multiple files are where cross-file reasoning matters most. A long-context model can, in principle, hold all the affected files and plan changes that maintain consistency. This is genuinely useful for the planning phase — understanding what needs to change and how the pieces relate before any code is modified.
But planning is not execution, and reasoning over context is not verification. A model that produces a sound refactor plan from a large-context analysis still needs the plan executed correctly, the changes tested, and the diffs reviewed. The long context helps the model form a better plan; it doesn't confirm the resulting code is correct.
Agent memory vs retrieved context
There's an architectural choice between holding everything in a long context and retrieving relevant context on demand (RAG-style). Long-context models lean toward the former: put it all in context, let the model attend to what matters. Retrieval-based approaches lean toward the latter: find the relevant pieces, load only those.
For coding agents, the trade-off is real. Long context is simpler — no retrieval infrastructure to build — but more expensive per query (you're paying for all those tokens) and subject to the middle-of-context attention degradation. Retrieval is more complex to build but can be cheaper and more focused. SkyClaw's "ultra-low cost" positioning is relevant here: if the per-token cost is low enough, the economic argument against long context weakens, making the simpler long-context approach more viable for cost-sensitive workloads.
Skywork AI and the Builder Ecosystem
Skywork as the organization behind SkyClaw
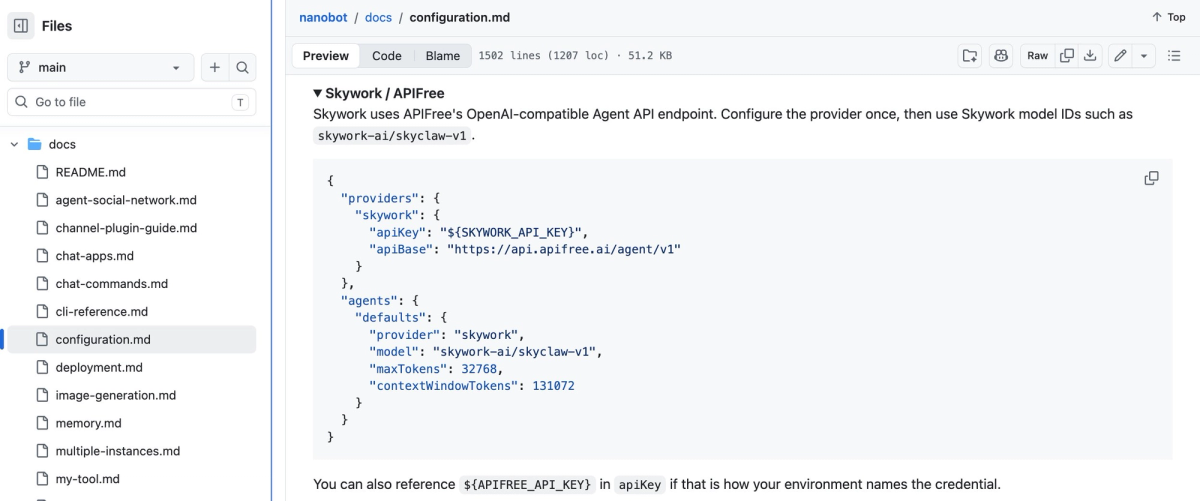
Skywork AI (associated with Kunlun Wanwei) is the organization behind SkyClaw-v1.0. Beyond the model, Skywork operates a broader agent ecosystem — the Skywork platform includes a research agent and desktop product, and the SkyClaw model is positioned to integrate with third-party agent frameworks. SkyClaw-v1.0 is listed as a first-class provider in Nanobot's configuration documentation, and Skywork states it's optimized for OpenClaw and Hermes as well.
The model is published on GitHub (SkyworkAI/skyclaw) with an accompanying technical page, and Skywork has stated an intention to progressively open-source each version after the trial period. The open-source commitment, if followed through, would distinguish SkyClaw from closed agent models and matter to teams that want self-hosting options.
Why this is not just a company profile
Understanding who builds an agent model matters for builders making adoption decisions, but the relevant question isn't the company's profile — it's the integration support and ecosystem fit. A model optimized for OpenClaw, Hermes, and Nanobot is most relevant if you're using those frameworks. A model that promises open-sourcing matters if self-hosting is a requirement. The ecosystem context tells you whether SkyClaw fits your stack, which is more actionable than knowing the company's background.
For builders not already in the OpenClaw/Hermes/Nanobot ecosystem, the integration story is less immediately relevant — you'd need to evaluate whether SkyClaw works with your existing agent framework before the model's capabilities matter to you.
Limits and Open Questions
Benchmarks need careful reading
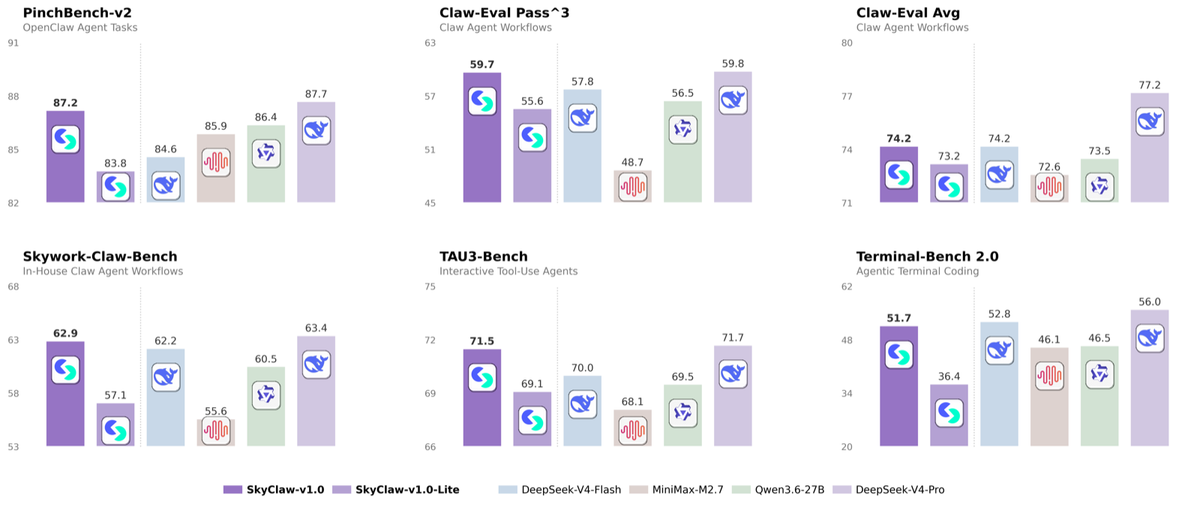
Skywork reports that both SkyClaw-v1.0 and the lite variant outperform Minimax 2.7, DeepSeek V4 Flash, and Qwen 3.6 models across agent benchmarks including PinchBench, Claw-Eval (with a stability test), and Skywork-Claw-Bench. The critical caveat: Skywork-Claw-Bench is Skywork's in-house agent evaluation suite, built on the OpenClaw environment. A model evaluated favorably on its creator's in-house benchmark, in an environment it was optimized for, is showing results under conditions favorable to it.
This doesn't mean the results are wrong. It means they're the kind of self-reported, home-field benchmark results that require independent verification before being treated as general conclusions. The comparison set (Minimax 2.7, DeepSeek V4 Flash, Qwen 3.6) is also a specific selection — notably, the comparison emphasizes models in a similar cost/size class rather than frontier models like Claude Opus 4.8 or GPT-5.5.
Long context can still amplify wrong assumptions
A subtle risk of long-context models: more context can mean more opportunity for the model to anchor on an incorrect assumption and reason extensively from it. If the model misreads a key piece of code early in a large context, it may build a long chain of reasoning on that misreading — and the length of the reasoning can make the error look more authoritative, not less. Long context amplifies whatever reasoning the model does, correct or not.
Integration support matters more than model claims
For production use, the model's benchmark performance matters less than whether it integrates cleanly into your workflow. Does it work with your agent framework? Is the API stable? Are the tools you depend on supported? Is the rate limit compatible with your usage? A model with slightly lower benchmark scores that integrates cleanly into your existing stack is more useful than a higher-scoring model that requires rebuilding your workflow. For SkyClaw specifically, the integration story is strongest if you're already using OpenClaw, Hermes, or Nanobot.
When Builders Should Pay Attention
Complex repo analysis
If your work involves analyzing large codebases holistically — understanding architecture, planning large refactors, tracing behavior across many files — long-context agent models are worth evaluating. SkyClaw's combination of large context and low cost is specifically relevant for high-volume codebase analysis where premium model costs would be prohibitive. Test whether the model's effective context use (not just its maximum window) holds up on your actual codebase.
Multi-agent planning and review
In multi-agent coding workflows, different agents handle different parts of a task. A long-context model can serve as the planning or orchestration agent that needs broad context to coordinate, while lighter models handle scoped execution. SkyClaw-v1.0-lite (the faster, cheaper variant) is positioned for exactly this kind of high-volume, scoped role within a larger workflow.
This is where the model layer and the workflow layer connect. SkyClaw represents a model capability — long context, low cost, agent-optimized. Tools like Verdent represent the workflow layer: Plan-First task decomposition, parallel agent execution on isolated Git worktrees, and diff review with verification before integration. A long-context model can improve the quality of context each agent works with; the workflow layer is what coordinates the agents, isolates their work, and verifies their output. The model and the workflow are complementary concerns — a better model doesn't replace the orchestration and verification structure, and the structure doesn't replace the need for a capable model.
Model evaluation for internal tooling
If you're building internal AI tooling and evaluating which models to use, SkyClaw is worth including in your evaluation set specifically for cost-sensitive, agent-heavy, long-context use cases. The free trial period (and the stated open-sourcing intention) lowers the barrier to evaluation. Run it against your actual tasks alongside the alternatives, and weight the integration fit with your stack as heavily as the raw capability.
FAQ
What is SkyClaw-v1.0?
SkyClaw-v1.0 is an agent model from Skywork AI, positioned as a million-context model optimized for low-cost agent workflows. It comes in two variants — the main SkyClaw-v1.0 and the faster, lower-cost SkyClaw-v1.0-lite — and is optimized for the OpenClaw, Hermes, and Nanobot agent frameworks. Skywork reports it was trained for complex tool use and multi-turn task execution, with a free trial period and a stated intention to progressively open-source each version. Verify current capabilities and availability at the official SkyClaw page, as this is a recent release and details may change.
How could SkyClaw help coding agents?
Potentially in two ways: large-context tasks (holding more of a codebase in context for cross-file reasoning and refactor planning) and cost-sensitive high-volume agent work (where its low-cost positioning makes long-context agent operations economically viable). The lite variant is positioned for scoped, high-frequency roles within multi-agent workflows. Whether these translate to better outcomes on your specific work depends on testing — context length is a ceiling on capability, not a guarantee of correctness. Consult the official documentation for current integration support and capabilities.
Does long context make AI coding agents more reliable?
Not by itself. A large context window lets a model hold more information at once, but holding information is not the same as reasoning correctly over it. Research consistently shows that models attend more reliably to information at the start and end of a long context than to information in the middle — so a large advertised window doesn't guarantee uniform reliability across it. Long context can also amplify errors: if a model anchors on an incorrect assumption early, more context means more reasoning built on that error. Long context is useful for tasks that need broad information, but reliability still requires testing, verification, and review regardless of context length.
When should builders evaluate long-context agent models?
When your work involves tasks that genuinely need broad context held simultaneously — large codebase analysis, cross-file refactor planning, long-document implementation, or long-running multi-step agent sessions. Also when cost is a constraint and a lower-cost long-context model makes high-volume agent work economically viable. Evaluate by testing on your actual tasks, measuring not just whether the model can hold your context but whether it reasons correctly across all of it (especially the middle). Weight integration fit with your existing agent framework alongside raw capability. Consult official documentation for current benchmark methodology, pricing, and integration support before committing.
Related Reading
- Claude Opus 4.8 for Coding Agents: What Builders Should Know
- What Is DeepSeek-TUI? A Terminal Coding Agent on V4
- Kimi K2.6 Agent Swarm: Parallel Sub-Agents for Coding
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- AI Coding Agents Need Better Search: What AnySearch Shows About the Next Workflow Layer
