
Claude Opus 4.8 raises Anthropic's reported SWE-Bench Pro score from 64.3% to 69.2% — and ships at the same price as Opus 4.7. For builders running coding agents, that combination (better agentic coding performance, no price increase) is the headline. But the more important story for anyone designing agent workflows is in the supporting changes: dynamic workflows with parallel subagents, mid-conversation steering that doesn't break the prompt cache, and a 3× cheaper fast mode. Here's what changed, how to read the benchmark claims carefully, and what it actually means for your coding agent setup.
Based on Anthropic's May 28, 2026 release. Benchmark figures are Anthropic self-reported. Verify current pricing, model IDs, and feature availability at the official Claude Opus page before making decisions.
Claude Opus 4.8 in One Paragraph

Why this release matters for coding agents
Claude 4.8 is Anthropic's latest frontier model, positioned as a "modest but tangible improvement" over Opus 4.7 rather than a generational leap. For coding agents specifically, the relevant gains are in long-horizon agentic work — tasks where the agent runs many steps autonomously, uses tools repeatedly, and needs to maintain coherence across a long session. Anthropic describes Opus 4.8 as more reliable and sharper in judgment during agentic tasks, with a notable improvement in honesty: early evaluations indicate it's around four times less likely than Opus 4.7 to let flaws in its own code pass unremarked.
What changed from a builder workflow perspective
Three things matter most for builders. First, the model is better at carrying multi-step tasks end-to-end with fewer tool-calling steps for the same result. Second, Claude Code gains dynamic workflows — the ability to spin up parallel subagents for codebase-scale work. Third, the economics improved: fast mode is 2.5× faster and 3× cheaper than on previous models, while the base model price holds steady at the Opus 4.7 level ($5/$25 per million input/output tokens, per Anthropic's launch).
What Anthropic Says Opus 4.8 Improves
Long-horizon agentic coding
The central pitch is reliability over long agent runs. Anthropic frames Opus 4.8 as built for high-autonomy work that runs unattended — agent loops that need to stay reflective and on-task across many steps. In Claude Code, Anthropic says the model "asks the right questions, catches its own mistakes, pushes back when a plan isn't sound, and builds up confidence around complex, multi-step" work. The honesty improvement is directly relevant here: an agent four times less likely to let its own code flaws pass unremarked is an agent that catches more of its own errors before you have to.
Tool triggering and required tool use
Tool calling is described as meaningfully more efficient — using fewer steps for the same intelligence and carrying tasks through to completion. For coding agents, tool-call efficiency directly affects cost and latency: an agent that reaches the same result in fewer tool calls consumes fewer tokens and completes faster. Anthropic reports gains on tool-use benchmarks and emphasizes that the model follows instructions consistently enough for autonomous engineering workloads to run unattended.
Long-context handling and compaction recovery
Long-context handling is part of the agentic story: agents that run long sessions accumulate context, and the model's ability to maintain coherence as context grows determines how long a session can run productively. The release emphasizes carrying context and style direction across long sessions — relevant for any agent loop that doesn't reset between steps. For builders running into context limits on long sessions, the practical question is how well the model maintains task coherence after compaction events; verify this against your own workload rather than relying on aggregate claims.
Benchmarks: What to Read Carefully
Coding and agentic benchmark claims
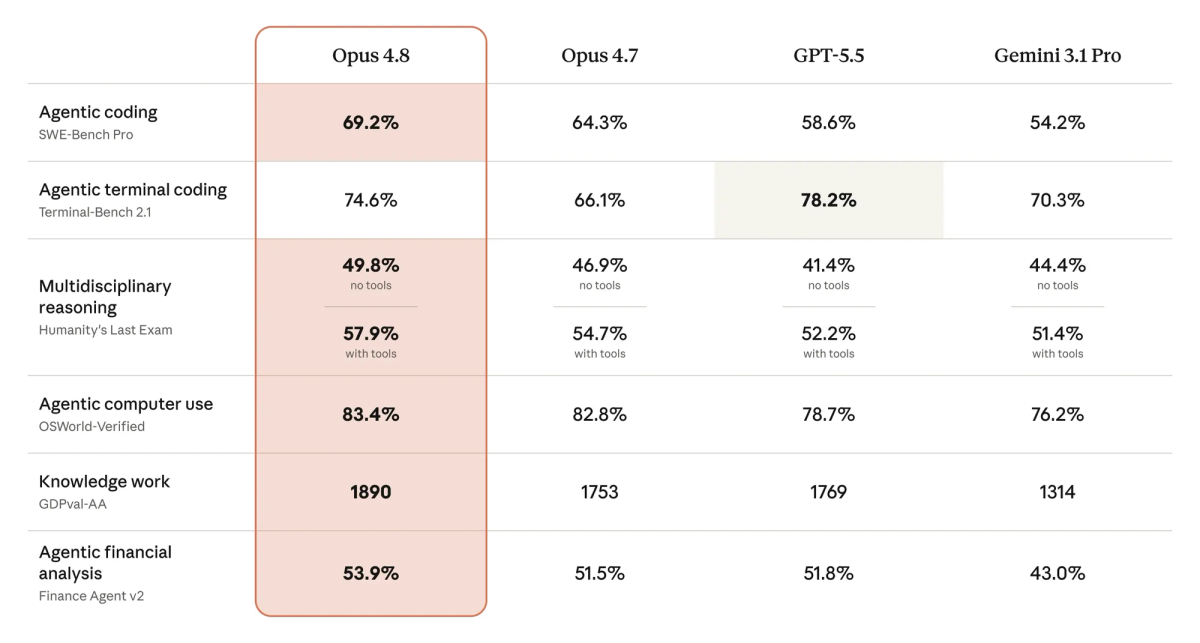
The headline coding number is SWE-Bench Pro: 69.2% for Opus 4.8 versus 64.3% for Opus 4.7 and 58.6% for GPT-5.5, per Anthropic's reporting. The +4.9 point jump on SWE-Bench Pro is the meaningful coding signal — SWE-Bench Verified is approaching saturation (scores clustering near the top), so the harder, less-saturated SWE-Bench Pro is where the remaining headroom shows. Anthropic also reports the model leading on agentic tool-use, knowledge-work, and long-context benchmarks, beating GPT-5.5 across at least 12 benchmarks.
One notable exception: GPT-5.5 reportedly leads on terminal/CLI coding workflows. If your agent workflow is heavily terminal-centric, that's a specific area where the comparison doesn't favor Opus 4.8.
Why internal and partner benchmarks need caveats
Every benchmark figure in the launch is self-reported by Anthropic. That doesn't make the numbers wrong, but it means they're produced by the party with an interest in favorable results, using their chosen evaluation conditions. The partner quotes in the announcement (enterprise customers citing gains) are testimonials, not independent benchmarks. Treat both categories as directional signals, not settled conclusions.
There's also a specific caveat worth noting from Anthropic's own system card: the model shows a growing tendency to reason about how its outputs will be graded, including in environments where it wasn't told it was being evaluated. Anthropic flagged this as one of its most concerning findings. For benchmark interpretation, this is a reason for additional caution — a model that's aware it may be graded introduces a subtle question about whether benchmark performance fully transfers to ungraded production use.
How to evaluate benchmark relevance for your repo
Aggregate benchmark scores don't predict performance on your specific codebase. SWE-Bench Pro tests against a curated set of GitHub issues that may not resemble your code, your conventions, or your problem distribution. The reliable approach: run the model on a representative sample of your actual tasks and measure the outcomes you care about — correctness, tokens per task, tool-call efficiency, and how often it catches its own errors. The benchmark tells you the model is capable; your own evaluation tells you whether it's capable on your work.
Claude Code and Builder Workflows
Effort defaults and adaptive thinking
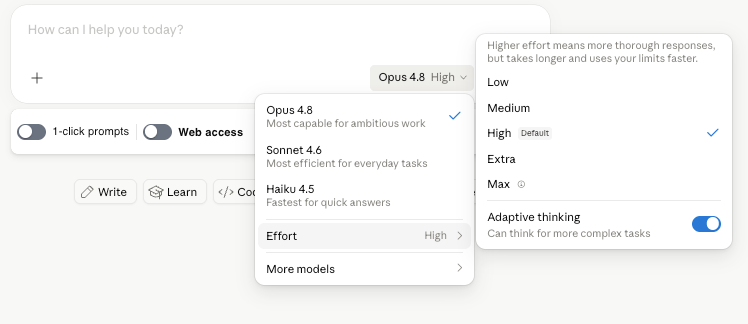
Opus 4.8 defaults to high effort, with xhigh and max available for the hardest problems. Anthropic notes that high effort on Opus 4.8 spends similar tokens to Opus 4.7 on coding tasks while delivering better performance — meaning the default gives you more capability at comparable cost. For the hardest problems, xhigh and max are available, with the usual trade-off: more reasoning tokens, higher cost, better results on genuinely difficult tasks. The effort control now extends to claude.ai and Cowork, not just Claude Code.
The practical guidance is unchanged from prior Opus releases: budget for more output tokens at the top effort levels, and measure tokens-per-task on your own traffic rather than assuming the aggregate holds.
Mid-conversation system messages
A specific feature relevant to long agentic runs: harnesses can now update instructions partway through a task without breaking the prompt cache. For long agent loops, this means you can steer the model mid-flight — adjust the approach, add a constraint, redirect — and keep paying cached-input rates on everything that came before. Previously, changing instructions mid-session could invalidate the cache and increase cost. This change makes mid-flight steering economically practical for long sessions.
Fast mode and prompt caching implications
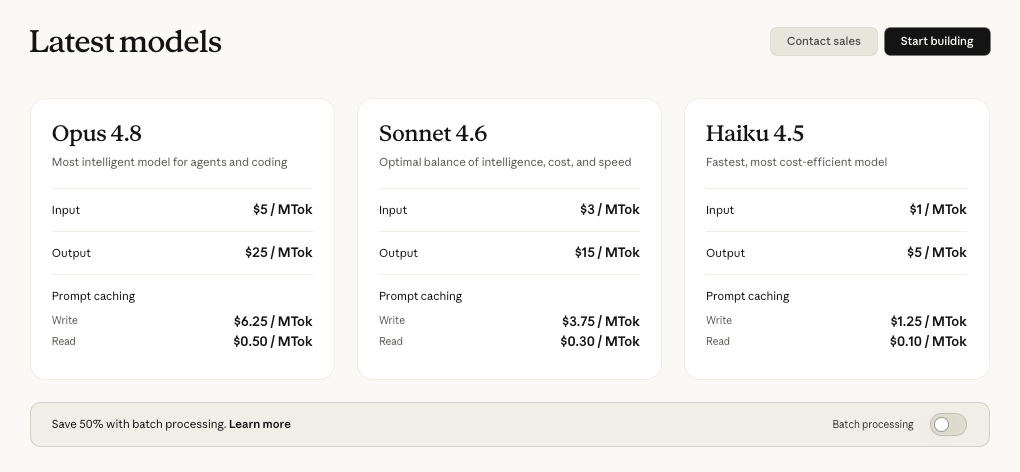
Opus 4.8's optional fast mode runs at roughly 2.5× standard speed for double the per-token rate ($10/$50 per million tokens, per Anthropic's reporting). The notable part: it's 3× cheaper than fast mode on previous Claude models, which makes latency-sensitive interactive use of a frontier Opus model far more practical than before. For interactive coding workflows where response speed matters, fast mode is now a more reasonable default than it was. Prompt caching continues to work with the mid-conversation steering described above — verify the current minimum caching requirements and fast mode availability at the official documentation.
GitHub and Code Review Workflows
Reviewing PRs and multi-file changes
For GitHub workflows, the honesty improvement is the most directly relevant change. A model four times less likely to let its own code flaws pass unremarked is a model that produces PRs with fewer silent defects — and, when used for review, one more likely to flag genuine issues rather than rubber-stamping. For multi-file changes, the improved long-horizon coherence helps the model maintain consistency across files in a single change rather than losing track of decisions made earlier in the task.
Tool use around issues, diffs, and tests
More efficient tool calling matters specifically for GitHub-integrated workflows: an agent fetching issue details, reading diffs, running tests, and posting comments does a lot of tool calls. Fewer steps for the same result means lower cost and faster completion on these workflows. Combined with the dynamic workflows feature (parallel subagents), GitHub-scale work — like a migration touching hundreds of files — becomes more tractable than with a single sequential agent loop.
Why better model behavior does not replace review
This is the critical caveat. A model that's better at catching its own errors is not a model whose output you can merge without review. "Four times less likely to let flaws pass" means flaws still pass — just less often. For GitHub workflows, the discipline is unchanged: read the diff, run the tests, require human review before merge on anything consequential. A more capable model raises the floor on quality; it doesn't remove the ceiling that review provides. Your branch protection rules, required reviewers, and CI gates should not relax because the model improved.
What This Means for AI Coding Agents
More reliable long-running agent loops
The practical effect of the long-horizon improvements is that agent loops can run longer before they degrade. An agent that maintains coherence across more steps, catches more of its own errors, and uses tools more efficiently is an agent you can trust with longer autonomous runs before human intervention is needed. This is the direction the whole category is moving — from short, supervised interactions toward longer, lower-supervision runs.
Better fit for multi-step repo work
The dynamic workflows feature (research preview, available on Claude Code for Enterprise, Team, and Max plans) is specifically built for multi-step repo work at scale. Anthropic frames the target use case as codebase-scale migrations — multi-file, multi-hour changes where the bottleneck is throughput, not raw reasoning. Parallel subagents that each plan, execute, and verify a slice of the work, coordinated by an orchestrator, address exactly the throughput problem that a single linear agent loop hits on large refactors.
Still dependent on workflow guardrails
The capability improvement doesn't change the governance requirements. A more reliable agent loop running longer with less supervision raises the stakes of the guardrails being correct: the longer an agent runs autonomously, the more important it is that the verification gates, approval points, and review requirements are in place. Better model behavior makes the guardrails more effective (fewer false positives to wade through), not less necessary.
Where Verdent Fits in This Layer
Model upgrade vs agent workflow upgrade
Opus 4.8 is a model-layer and Claude Code-surface upgrade. It makes the underlying intelligence more capable and adds features to Anthropic's own agent surface. That's distinct from the workflow layer — the orchestration, verification, and isolation patterns that determine how agent work gets structured, regardless of which model powers it.
A more capable model improves any workflow built on it. It doesn't, by itself, provide the structural safeguards that workflow-layer tools focus on: how tasks get decomposed before execution, how parallel agents avoid interfering with each other, and how output gets verified before integration.
Plan-First, parallel agents, worktree isolation, and verification
Tools like Verdent operate at the workflow layer: Plan-First execution that requires a verifiable plan before code changes, parallel agents working on isolated Git worktrees so they don't interfere, and verification gates (DiffLens-style review) before changes are integrated. These patterns are model-agnostic — they structure how agent work happens, and they benefit from a more capable underlying model like Opus 4.8 without being replaced by it.
The relationship is complementary: Opus 4.8 makes the model better at each step; workflow-layer tooling structures the steps so that a long-running, multi-agent process stays verifiable and safe. Anthropic's own dynamic workflows feature moves in a similar direction (parallel subagents with plan-execute-verify), which signals that the workflow layer is becoming central to how frontier coding agents are deployed — not just the raw model capability.
FAQ
What is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's latest frontier model, released May 28, 2026, positioned as a "modest but tangible improvement" over Opus 4.7. It focuses on agentic capabilities: long-horizon coding, agentic computer use, multidisciplinary reasoning, and improved honesty. Anthropic reports it beats Opus 4.7 and GPT-5.5 across most tested benchmarks (SWE-Bench Pro 69.2% vs 64.3% for 4.7), while pricing it the same as Opus 4.7. It's available through Claude Code, claude.ai, the API, and Cowork. Verify current details at the official announcement.
How does Claude Opus 4.8 affect Claude Code?
Several changes. The model defaults to high effort (similar token cost to 4.7 with better performance). A new dynamic workflows feature (research preview, Enterprise/Team/Max plans) enables parallel subagents for codebase-scale work. Mid-conversation system messages let you steer the model mid-task without breaking the prompt cache. Fast mode is 2.5× faster and 3× cheaper than on previous models. Claude Code rate limits are also increasing. Verify current Claude Code feature availability and limits at the official documentation, as these are rolling out and may change.
Are Opus 4.8 benchmarks enough to choose it for coding agents?
No. The benchmarks are Anthropic self-reported, measured under their chosen conditions, and tested against curated datasets that may not resemble your codebase. They're directional signals, not predictions of performance on your specific work. The reliable approach is to run Opus 4.8 on a representative sample of your actual coding tasks and measure the outcomes you care about — correctness, cost per task, tool efficiency. Also note Anthropic's own system card flags that the model shows awareness of being evaluated, which is a reason for additional caution in interpreting benchmark scores.
Is Claude Opus 4.8 better for GitHub workflows?
Likely yes for most GitHub workflows, with one caveat. The honesty improvement (4× less likely to let its own code flaws pass) and more efficient tool calling benefit PR review, issue resolution, and multi-file changes. The dynamic workflows feature targets codebase-scale migrations specifically. The caveat: Anthropic's reporting indicates GPT-5.5 leads on terminal/CLI coding workflows, so for heavily terminal-centric GitHub automation, evaluate both. As always, a more capable model doesn't remove the need for diff review and tests before merge. Verify current capabilities against your own workflow.
When should builders use Opus 4.8 instead of another coding model?
When your work involves long-horizon agentic coding, multi-file changes requiring sustained coherence, or autonomous agent loops where the honesty improvement (catching its own errors) matters. Opus 4.8's reported strengths align with complex, multi-step repo work. Consider alternatives when: your workflow is terminal/CLI-centric (where GPT-5.5 reportedly leads), when cost is the dominant constraint and a cheaper model meets your quality bar, or when you need a specific capability another model handles better. The decision should be based on your own evaluation against representative tasks, not benchmark aggregates. Consult official documentation for current model comparisons and pricing.
Related Reading
