
A 31-billion-parameter model that competes with models twenty times its size — and you can run it on your own hardware, fine-tune it, and ship it in a product, all under Apache 2.0. That's the headline for Gemma 4, Google DeepMind's open model family. For coding-agent builders, the open-weight angle is the real story: a capable model you fully control, with no per-token cost and no code leaving your infrastructure. This is what Gemma 4 means for agentic coding workflows, and where its limits actually are.
Verified against Google's official Gemma 4 documentation and announcement as of June 2026. Model details and availability change — confirm at the official model card before relying on specifics.
Gemma 4 in One Paragraph
Google's open model family for builders
Gemma 4 is Google DeepMind's family of open-weight models, released April 2, 2026, built on the same research that powers the proprietary Gemini 3 models. The defining facts for builders: it's licensed under Apache 2.0 (a first for the Gemma family, removing the legal-review friction the old custom license created), it ships as downloadable weights you run on your own hardware, and it's multimodal (text and image input, with audio support) with up to 256K context. The Gemma 4 model family spans from phone-sized edge models to workstation-class models, all designed to deliver strong performance at each size.

The Apache 2.0 license matters more than it sounds. The old Gemma license required legal review and blocked some enterprises whose compliance frameworks demanded standard open-source terms. Apache 2.0 eliminates that — you can use Gemma 4 commercially, modify it, fine-tune it, sell the result, and deploy it without restriction (attribution being the only requirement). For enterprise builders, that's the difference between "can't use it" and "can deploy it in production."
Why coding-agent teams care
For teams building coding agents, the Google Gemma 4 release offers something closed APIs can't: complete control over the model layer. You can run it locally (code never leaves your machine), self-host it on your own infrastructure (no third-party data transit), fine-tune it on your codebase (specialize it for your domain), and eliminate per-token costs (run unlimited inference for the cost of compute). For privacy-sensitive, cost-sensitive, or high-volume agentic workloads, those properties are the reason to evaluate an open model over a closed API.
What Gemma 4 Changes for Developer Workflows
Open-weight model control
The core shift is control. With a closed API, you call a model you don't own, on infrastructure you don't control, paying per token, with your data transiting a third party. With Gemma 4's open weights, you own the deployment end to end. For coding agents specifically, this means you can run the agent's model inside your security perimeter, audit exactly what it does, and modify it if needed. The Apache 2.0 license makes all of this legally clean for commercial use.
This control is most valuable when it solves a real constraint: data residency requirements that prohibit sending code to external APIs, cost structures where per-token pricing is prohibitive at your volume, or the need to fine-tune on proprietary data. If none of those constraints apply, a closed API may be simpler. If they do, open weights are the answer.
Local and self-managed inference options
Gemma 4 has broad day-one runtime support: Hugging Face Transformers, vLLM, llama.cpp, MLX, Ollama, LM Studio, NVIDIA NIM, SGLang, and more. The weights are downloadable from Hugging Face, Kaggle, and Ollama. For testing without setup, Google AI Studio hosts the 31B and 26B MoE in-browser, and Google AI Edge Gallery runs E2B and E4B on phones. This deployment flexibility means you can match the inference setup to your needs — a managed cloud deployment, a self-hosted GPU cluster, a local workstation, or an on-device edge model.
For coding-agent builders, the practical options are: self-host the 26B or 31B on your own GPU infrastructure for a controlled agentic backend, or run a smaller variant locally for development and privacy-sensitive work. The runtime breadth means you're not locked into one deployment path.
Multimodal and agentic workflow potential
Google explicitly positions Gemma 4 for agentic workflows, coding, and multimodal understanding. The models support function calling (the mechanism agents use to invoke tools), which is foundational for agentic behavior. The multimodal capability (image input alongside text) opens workflows like reasoning over screenshots, diagrams, or UI mockups as part of a coding task.
The agentic potential is real but bounded by what an open model on your hardware can deliver versus a frontier cloud model. Gemma 4 supports the building blocks (function calling, long context, multimodal input); whether it delivers the agentic reliability your workflow needs is something to validate on your actual tasks rather than assume from the positioning.
Gemma 4 for Coding Agents
Code generation and repo reasoning
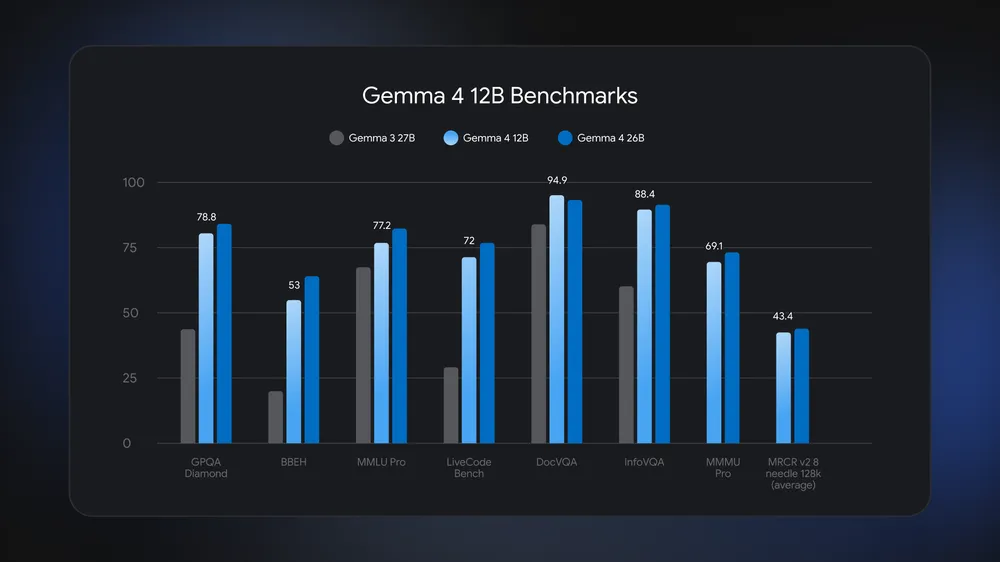
Gemma 4 handles code generation and reasoning across languages, with the larger variants (26B MoE, 31B Dense) competitive on coding benchmarks for their size. The 31B Dense ranks #3 among open models on Arena's text leaderboard; the 26B MoE ranks #6. For a coding agent, this translates to capable code generation, repo reasoning, and the kind of multi-step work an agent loop requires — within the ceiling that an open model on your hardware imposes.
The realistic framing: Gemma 4 is strong for an open model you control, suitable for code generation, explanation, scoped edits, and repo reasoning. For the hardest agentic coding tasks at frontier difficulty, closed frontier models still lead — Google's own positioning acknowledges that proprietary systems lead the hardest benchmarks. Gemma 4's value isn't being the absolute best model; it's being a capable model you fully own and control.
Local model routing in agent systems
A common pattern in production agent systems is model routing: send routine, high-volume work to a cheaper or local model, and reserve a premium model for the hardest tasks. Gemma 4 fits the local/cost-efficient role in this pattern well. An agent system could route bulk work (code explanation, simple edits, test generation) to a self-hosted Gemma 4, keeping costs and data local, while routing the hardest reasoning to a frontier model when needed.
This is where the open-weight model earns its place in an agent architecture — not as the only model, but as the controllable, cost-efficient layer that handles the volume. The model and runtime are the model layer of the system. The workflow layer — how tasks are decomposed, how agents are coordinated and isolated, how output is verified before integration — is a separate concern. Tools like Verdent operate at that workflow layer (Plan-First decomposition, parallel agents on isolated Git worktrees, verification gates), which is model-agnostic: the structure works whether the underlying model is a self-hosted Gemma 4 or a cloud frontier model. Choosing the model and structuring the workflow are independent decisions.
Gemma 4 Model Sizes: Avoiding Confusion
E2B, E4B, 26B MoE, and 31B Dense
The original Gemma 4 lineup, released April 2, 2026, has four sizes:
- E2B (Effective 2B) — edge model for mid-range phones, runs in under 1.5 GB RAM
- E4B (Effective 4B) — edge model for flagship phones and laptops, the on-device default
- 26B MoE (also called 26B A4B — 26B total, 4B activated per token) — the speed-oriented mid-tier, ranked #6 open model on Arena
- 31B Dense — the workstation flagship, ranked #3 open model on Arena, the highest-quality variant
These four are the original family. For coding-agent work, the 26B MoE and 31B Dense are the relevant choices (capable enough for serious agentic work), with the edge models (E2B, E4B) suited to on-device or lightweight local use.
Where Gemma 4 12B Unified fits
Here's the point of frequent confusion, worth getting right: Gemma 4 12B Unified is not part of the original four-model lineup. The original April 2, 2026 release shipped E2B, E4B, 26B MoE, and 31B Dense. Google added a 12B Unified model as a separate follow-up on June 3, 2026 — it is not the original lineup's "12B Dense."
The 12B Unified is architecturally distinct: an encoder-free multimodal model where vision and audio flow directly into the LLM backbone, positioned as a mid-tier bridge between the edge-friendly E4B and the more capable 26B MoE. It's a legitimate option (it runs on consumer laptops with reasoning approaching the 26B), but when discussing the Gemma 4 family, it should be treated as the distinct June 2026 addition it is — not conflated with the original four-model lineup. If you see a comparison treating "Gemma 4 12B" as the original mid-size model, that's the error to avoid.
Limits Builders Should Watch
Open model does not mean production-ready agent
The most important caveat: an open-weight model is not an agent, and a capable model is not a production-ready agentic system. Gemma 4 gives you a strong, controllable model. Turning it into a reliable coding agent requires the harness around it — the agent loop, tool definitions, context management, error recovery, and verification — none of which the model provides. The open weights are the foundation; the agentic system is what you build on top.
This matters because "Gemma 4 supports agentic workflows" can be misread as "Gemma 4 is a coding agent." It isn't. It's a model with the building blocks (function calling, long context) that an agent system uses. The reliability of the resulting agent depends as much on the harness as on the model.
Local setup, context, and eval constraints
Running Gemma 4 locally introduces practical constraints. The larger variants (26B, 31B) need substantial memory — workstation or server-class hardware for full-quality inference. Context, while large on paper (256K), is bounded in practice by your hardware's memory (long context inflates the KV cache). And the model's actual performance on your specific coding tasks needs validation — benchmark rankings (Arena #3 for 31B) indicate general capability, not performance on your codebase.
The reliable approach to evaluation: run Gemma 4 on a representative sample of your actual coding tasks, on your target hardware, and measure the outcomes you care about — correctness, latency, and how well it handles your domain. Open weights make this evaluation easy (no API gatekeeping), but the evaluation still has to happen. Treat Google's benchmark positioning as orientation, not as a guarantee of fit for your work.
FAQ
What is Gemma 4?
Google DeepMind's open-weight model family, released April 2, 2026, built on the same research as the proprietary Gemini 3 models. It's Apache 2.0 licensed (commercial use, modification, redistribution with attribution), multimodal (text/image, audio supported), and supports up to 256K context. The original lineup has four sizes: E2B and E4B (edge), 26B MoE, and 31B Dense (#3 open model on Arena). Available on Hugging Face, Kaggle, Ollama, Google AI Studio, and AI Edge Gallery.
Can Gemma 4 be used for coding agents?
Yes, with the right framing. Gemma 4 (especially 26B MoE and 31B Dense) handles code generation, repo reasoning, and multi-step work, and supports function calling — the foundation of agentic tool use. But the model is the model layer, not a complete agent: turning it into a coding agent requires building the harness (agent loop, tools, context management, verification) around it. It suits the controllable, cost-efficient role in an agent system. Validate on your actual tasks first.
Is Gemma 4 12B part of the original Gemma 4 lineup?
No. The original Gemma 4 release (April 2, 2026) shipped four sizes: E2B, E4B, 26B MoE, and 31B Dense. The 12B Unified was a separate follow-up release on June 3, 2026 — an encoder-free multimodal model positioned as a mid-tier bridge between E4B and 26B, not the original lineup's "12B Dense." It's a legitimate model, but it's a distinct later addition with a different architecture. When discussing the original Gemma 4 family, the mid-size options are the 26B MoE and 31B Dense, not a "12B."
When should builders choose Gemma 4 over closed models?
When you have a constraint open weights solve: data residency rules that prohibit external APIs, per-token pricing that's prohibitive at your volume, the need to fine-tune on proprietary data, or running inference inside your own security perimeter. Apache 2.0 makes all of these legally clean for commercial use. Choose a closed frontier model when you need maximum capability on the hardest tasks without those constraints. Many systems use both — self-hosted Gemma 4 for high-volume work, a frontier model for the hardest tasks.
Related Reading
