
GLM-5.2 landed on June 13, 2026 with two things that matter more to a working developer than any benchmark: a usable 1-million-token context window and MIT-licensed open weights. The first means you can hold a large codebase in context for repo-scale work; the second means you can self-host it commercially without restriction. Z.ai shipped it with no benchmarks at launch — which tells you to evaluate it on capability and fit, not on numbers it hadn't published yet. Here's what GLM-5.2 actually is, in coding terms, and why those two features change what's possible for real repository and long-horizon work.
Model details verified against Z.ai's repository and reporting as of June 2026. This is a brand-new release with details still settling — confirm current specs, availability, and any benchmarks at the official Z.ai repository before relying on them. Model specs and pricing change; always check the official source before production decisions.
GLM-5.2 in One Paragraph
Z.ai's new flagship and key specs
GLM-5.2 is the new flagship coding model from Z.ai (the international brand of Zhipu AI, a Beijing company spun out of Tsinghua University), announced June 13, 2026. It's a Mixture-of-Experts model — reported at roughly 753B total parameters with about 40B active per token, built for long-horizon, agentic software engineering rather than chat. The headline features: a usable 1-million-token context window (with up to ~128K-131K output tokens per response), a new dual thinking-effort system (High and Max modes), and an architectural optimization (called IndexShare in reporting) that reduces per-token compute at extreme context lengths. The MoE design with ~40B active parameters is what keeps a 753B-class model's inference cost manageable — you're not paying dense-753B compute per token.

MIT open weights and commercial implications
The licensing is as important as the architecture. GLM-5.2's weights are released under the MIT License — a fully permissive open-source license, not a restricted or research-only one. At launch (June 13) access was through Z.ai's paid Coding Plan, with the standalone API, chatbot, and open weights following shortly after on Hugging Face and ModelScope. For builders, MIT weights mean you can self-host GLM-5.2, customize it, and use it commercially without the restrictions that come with non-standard "open" licenses — a meaningfully different deployment position than closed API-only models or open-weight models under restrictive community licenses. Verify the current availability and the exact license terms on the official repository, since a just-released model's distribution is still settling.
Why the 1M Context Window Matters for Real Coding Work
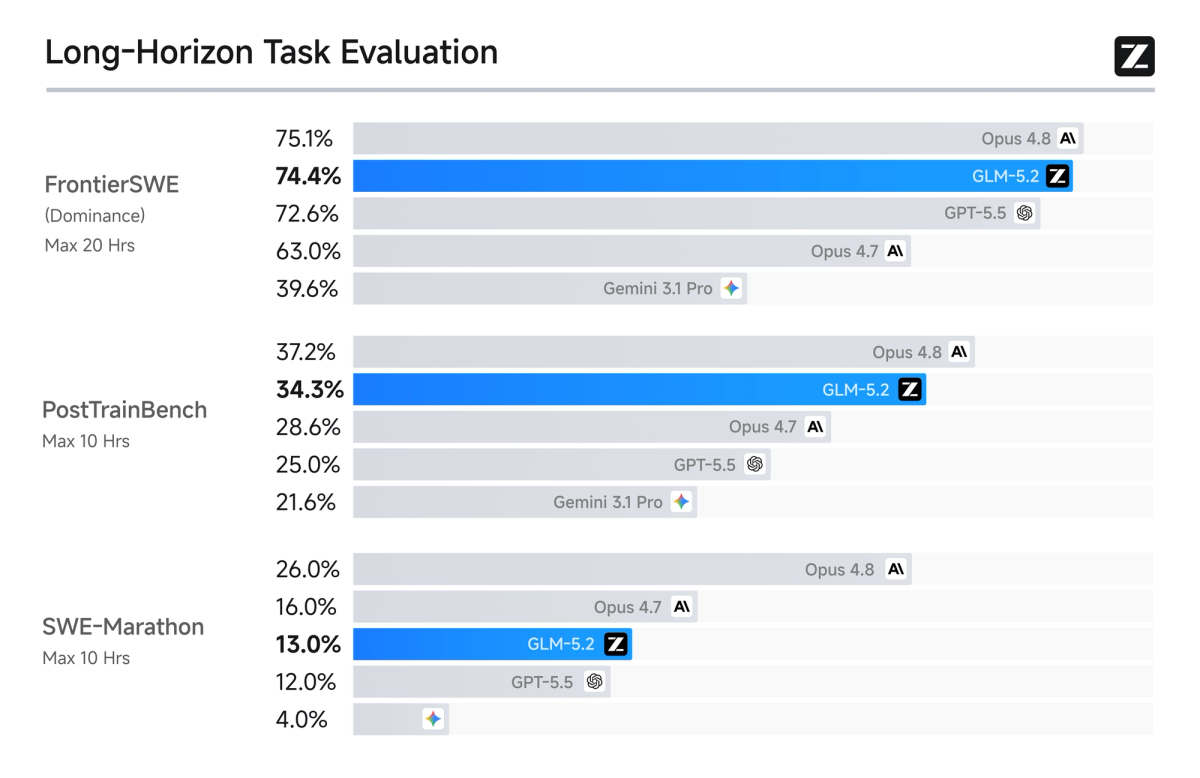
Whole-repository context and long-horizon agents
The 1M-token window is the feature most relevant to real coding, because it changes what fits in a single context. At GLM-5.1's 200K window, you chunk a large codebase and lose cross-file context; at 1M, you can hold a substantial repository — many files, their relationships, the relevant history — in one pass. For repo-scale work (migrations spanning dozens of files, debugging that correlates code across modules, understanding an unfamiliar codebase) and for long-horizon agents (tasks that run many steps and need to remember earlier decisions), that larger window directly addresses the bottleneck. Z.ai specifically describes training the model on long-horizon agent trajectories at 1M context, which is the part that matters: a large window is only useful if the model was trained to reason coherently across it, not just accept the tokens.
Usable context vs theoretical maximum
The word "usable" is doing real work in Z.ai's framing, and it's the right skeptical lens to apply to any large-context claim. A model can advertise a 1M window but degrade badly past a few hundred thousand tokens — accepting the input without reasoning well across it. Z.ai's claim is that 1M is usable (coherent reasoning across the full window), and the IndexShare optimization (reported to cut per-token FLOPs ~2.9× at 1M) is the mechanism meant to make filling that window economical rather than ruinously expensive. The honest position for a builder: treat "usable 1M" as a claim to verify on your own large-context tasks, not a guarantee. Load a real large codebase and test whether the model actually reasons across it, because the gap between theoretical and usable context is exactly where long-context models tend to disappoint.
High vs Max Effort Modes
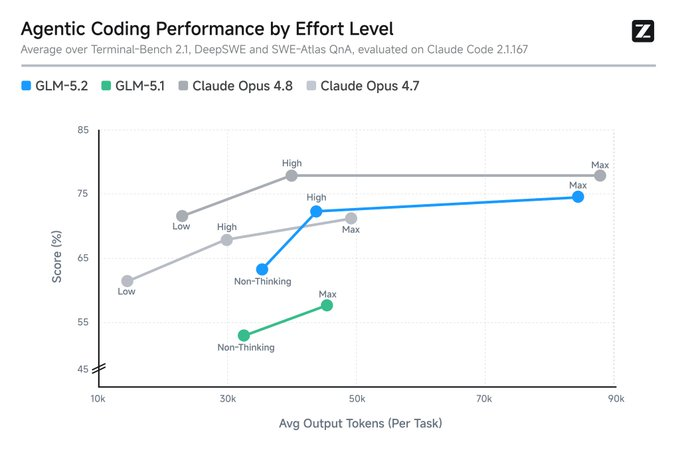
Speed vs quality tradeoffs in practice
GLM-5.2 introduces a dual thinking-effort system: High and Max. This is a tuning knob for the speed/quality tradeoff — High for faster responses on simpler work, Max for spending more compute (and tokens, and time) on harder reasoning. The practical use: route simple, high-volume tasks to High to keep things fast and cheap, and reserve Max for the genuinely complex, multi-step coding problems where the extra reasoning depth changes the outcome. The tradeoff is the familiar one — Max costs more compute and time per task, so defaulting everything to Max wastes resources on work that didn't need it. The value of the two modes is exactly that you don't have to pick one setting for all work; match the mode to the task's difficulty, using Max where reasoning depth pays off and High where it doesn't.
How GLM-5.2 Differs from Typical Chat Models
Agentic tool use and multi-file editing strengths
GLM-5.2 is built for agentic coding, which is a different design target than a general chat model. The distinction shows in what it's optimized for: tool use and function calling (so it can act in an agent loop — run commands, read results, iterate), multi-file editing (handling changes that span many files coherently), and long-horizon task execution (staying on-task across many steps). It supports the major agentic coding tools out of the box (Claude Code, Cline, Roo Code, and others), and because it speaks an OpenAI-compatible chat-completions API, it generally drops into agent frameworks that allow a custom endpoint as a configuration swap. The point for a builder: GLM-5.2 is meant to be the model inside a coding agent, not a chatbot you converse with — its strengths are in the agentic, repo-scale, multi-file work that the 1M context and effort modes are designed to support.
What's Confirmed vs What's Still Evolving
Because GLM-5.2 is days old, it's worth separating what's settled from what isn't:
- Confirmed: it exists, released June 13, 2026; it's a Z.ai MoE flagship for coding; it has a usable 1M context window and High/Max effort modes; the weights are MIT-licensed; it supports major agentic coding tools.
- Still settling / verify yourself: the exact total parameter count (reported at ~753B, but confirm against Z.ai's official materials), the precise rollout state of the API and full weights (these followed the initial Coding Plan launch and you should confirm current availability), and — most importantly — performance. Z.ai published no benchmarks at launch, and the benchmark figures that have since circulated are vendor-reported or early third-party, without broad independent verification.
On benchmarks specifically: figures like a SWE-Bench Pro score in the low 60s or a Terminal-Bench 2.1 score around 81 have appeared in coverage, but these are Z.ai-reported or early and unverified — treat them as claims to confirm, not established facts, and weight your own testing over any published number. (For context, even the circulated Terminal-Bench figure sits below Claude Opus 4.8's reported score, so the framing is "competitive," not "dominant" — and none of it is independently confirmed.)
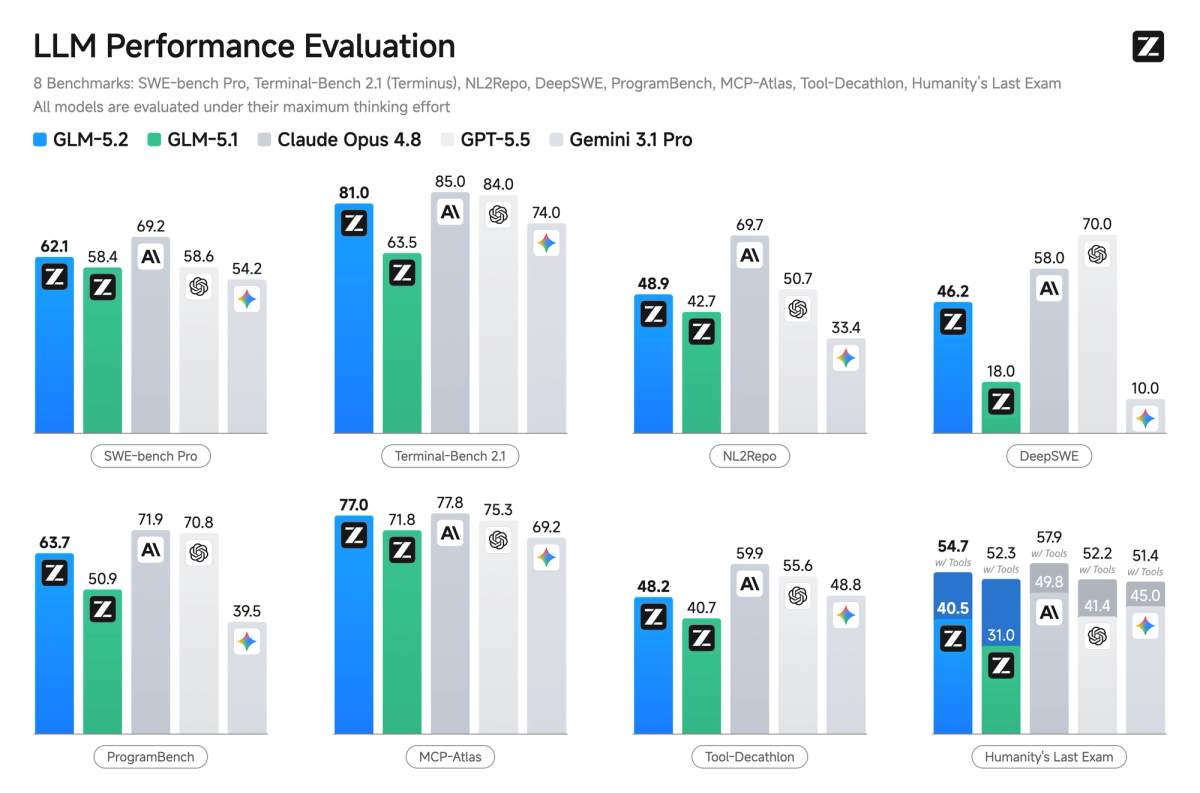
FAQ
How does the 1M context actually behave with large real-world repositories?
That's exactly what you should test rather than assume. Z.ai describes the 1M window as "usable" and says it trained the model on long-horizon agent trajectories at that context length, which is the right kind of claim — but real-world behavior on your repository is an empirical question. A large window can still degrade on coherence or speed past a certain fill level, and the only way to know how GLM-5.2 handles your codebase is to load a representative large context (many real files, real cross-file dependencies) and observe whether it reasons accurately across them, how latency holds up, and what it costs. Treat "usable 1M" as a claim to verify on your actual repos, not a guaranteed capability.
When do GLM-5.2's effort modes make a noticeable difference?
The Max mode matters most on genuinely hard, multi-step reasoning — complex refactors, intricate debugging, architectural work where deeper reasoning changes the result. On simpler, high-volume tasks (routine edits, straightforward generation), High mode is faster and cheaper and the extra depth of Max wouldn't change the outcome. So the noticeable difference appears at the hard end of your task distribution: that's where Max's additional compute and time pay off, and where defaulting to High might leave quality on the table. The practical approach is to route by difficulty — High for the volume, Max for the hard problems — rather than picking one mode for everything.
What should builders verify before committing to GLM-5.2 in a production pipeline?
Three things. First, performance on your own work: GLM-5.2's benchmarks are vendor-reported or early third-party with no broad independent verification, so run it on a representative sample of your real tasks and measure completion, correctness, and cost rather than trusting any published score. Second, current availability and license terms (API access, full weights, and exact MIT terms were still settling at launch). Third, operational realities — latency at long context, cost per task at your volumes, and tool-call reliability in your harness. The summary: don't commit on benchmarks (self-reported and unverified) — commit on your own repo-level evaluation.
How does the open-weight status change long-term deployment options?
Significantly. MIT-licensed weights mean you can self-host GLM-5.2 on your own infrastructure — code never leaves your machines, no per-token API cost (you pay for compute), and freedom to customize and use commercially without the restrictions of non-standard "open" licenses. For teams with data-residency, regulatory constraints, or a need to avoid hosted-API dependency, that's a categorical advantage over closed API-only models. The trade-off is hardware: a 753B-class MoE needs serious infrastructure to self-host (the ~40B active parameters help inference cost, but you still hold all weights in memory). So open weights expand your options — hosted API now, self-hosted later, or both — but self-hosting stays a data-center undertaking, not a casual local run.
Conclusion
GLM-5.2 is best understood, in coding terms, as an open-weight flagship built for repo-scale and long-horizon agentic work — with two features that genuinely matter to builders: a usable 1M-token context window for whole-repository work, and MIT-licensed weights that make commercial self-hosting an option closed models can't offer. The High/Max effort modes give you a difficulty-based tuning knob, and the agentic design targets the multi-file, tool-using work where large context pays off. The honest caveat is its newness: Z.ai shipped it without benchmarks, the figures circulating since are self-reported or unverified, and the exact parameter count and rollout state were still settling at launch. So the right move is to evaluate GLM-5.2 on your own repos — test the usable context, the effort modes, and the agentic behavior on real tasks — rather than on any number you read. For builders who value open weights and long-context coding, it's a serious option worth testing; just bring your own verification.
Related Reading
