
Most model releases are incremental. xAI's February 2026 release of Grok 4.20 Beta is structurally different: instead of routing every query through a single model inference pass, it runs four specialized sub-agents in parallel, has them cross-verify each other's outputs, and synthesizes a single response. That architecture is the story, not the benchmark scores.
This article explains how the four-agent system works, what the 16-agent Heavy variant adds, where it helps in coding workflows, and where the single-model approach still wins. It also flags clearly what xAI has publicly documented versus what circulates as community inference.
Why Grok 4.20 Went Multi-Agent
The bet — cross-verification beats single-pass reasoning
The standard frontier model architecture is a single large model making one forward pass per query, sometimes extended with chain-of-thought reasoning before output. The core failure mode is self-consistency bias: the same model that generates an answer is also the model evaluating whether that answer is correct. When the generation goes wrong, the evaluation tends to agree with it.
Grok 4.20 bets on a different approach: multiple agents with distinct roles reason independently, then debate before synthesis. The coordination overhead is real — latency is higher, cost is higher — but the claim is that cross-agent disagreement surfaces errors that single-model self-review consistently misses.
xAI's own published claim is a 65% reduction in hallucinations (from approximately 12% to 4.2%) compared to single-model baselines. This is xAI's self-reported figure, not an independently verified benchmark at the time of writing. The independent Artificial Analysis Omniscience benchmark rated Grok 4.20 at 78% non-hallucination rate, while xAI claims 83% in internal testing. Both figures favor the multi-agent architecture over comparable single-model results, but treat them as directional signals rather than verified ground truth until third-party replication catches up.
How the 4 Agents Divide Work
A sourcing note: The four agent names — Grok, Harper, Benjamin, and Lucas — are widely reported across community sources and corroborated by multiple independent accounts of the system's behavior. However, as of this writing, xAI has not published a formal technical specification naming and defining these agents in official documentation. Treat the names and role assignments as community-documented observations rather than xAI-confirmed architecture.
Grok as the coordinator
The Grok agent (also referred to as "Captain" in community descriptions) handles task decomposition and final synthesis. When a query arrives, it analyzes complexity, breaks the problem into sub-tasks appropriate to the other agents' specializations, dispatches work in parallel, and adjudicates disagreements before producing the final response. Users can observe this process through a live thinking interface that shows progress and notes from each agent in real time.
The coordinator role is meaningfully different from being a simple aggregator. When Benjamin and Harper's outputs contradict each other, Grok decides which takes precedence or requests additional verification — the arbitration logic is not publicly documented by xAI, which means the specific decision-making mechanism is opaque.
Harper (research), Benjamin (logic/math), Lucas (contrarian check)
Harper is the research agent. Its structural advantage over competing models is direct API access to the X Firehose — approximately 68 million English-language posts per day — enabling real-time retrieval of market sentiment, breaking news, and social signal data. Harper also performs web searches and document retrieval to supply factual evidence before Benjamin verifies and Grok synthesizes.
Benjamin handles logic, mathematics, and code verification at what xAI describes as "mathematical proof-level precision." Benjamin's role in coding queries is to generate code and verify logical correctness, running step-by-step reasoning chains that pure text generation tends to shortcut. A practical validation: mathematician Paata Ivanisvili reportedly used an early Grok 4.20 internal beta to achieve new mathematical discoveries related to Bellman functions — a domain requiring exactly the formal verification Benjamin is designed for.
Lucas is the contrarian. Community descriptions of the role vary — "creative synthesis," "divergent thinking," "output optimization" — but the common thread is that Lucas exists to challenge the conclusions of Harper and Benjamin rather than extend them. If Harper's research supports a claim and Benjamin's logic confirms it, Lucas generates the counterargument. This creates internal disagreement that Grok must resolve, which is where the hallucination-reduction mechanism actually operates.
How outputs are cross-verified
The cross-verification runs in four phases:
- Decomposition — Grok analyzes the query and routes sub-tasks to Harper, Benjamin, and Lucas simultaneously.
- Parallel analysis — All three agents independently approach their assigned components from their respective domains.
- Internal debate — Agents review each other's outputs. If Benjamin's mathematical conclusion contradicts Harper's retrieved evidence, the discrepancy is flagged. If Lucas's alternative interpretation undermines both, that surfaces too. This debate phase is where hallucinations are caught before synthesis.
- Aggregated output — Grok synthesizes the final response, resolving disagreements. Only conclusions that survive cross-agent scrutiny reach the user.
The internal debate mechanism is what distinguishes this from simple ensemble averaging. The agents are not just producing independent outputs that get averaged or majority-voted — they are actively reviewing and contesting each other's reasoning before synthesis.
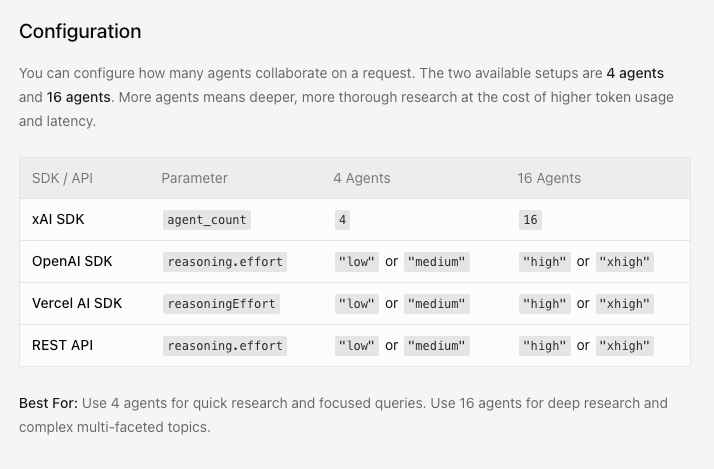
Grok 4.20 Heavy — The 16-Agent Variant
What changes when you scale from 4 to 16 agents
Grok 4.20 Heavy is the 16-agent variant of the same architecture, available to SuperGrok Heavy subscribers ($300/month). It was confirmed by Elon Musk on March 12, 2026, who described it as "extremely fast for deep analysis" — the first direct performance characterization from xAI for the Heavy mode.
The 4-to-16 agent scaling adds more specialized roles beyond the base four. Community accounts describe domain-specific agents for tasks like financial analysis, compliance, and structured content — but xAI has not published a named list of Heavy mode agents. What is documented: the same parallel-reasoning and cross-verification architecture applies at 16-agent scale, with correspondingly more specialization depth and more points of internal disagreement before synthesis.
The latency tradeoff is significant. 4-agent mode is noticeably slower than single-model inference for simple queries. 16-agent mode amplifies that latency further. For tasks that benefit from this depth — multi-domain reasoning, compliance-sensitive research, complex investment analysis — the accuracy improvement may justify the wait. For anything where speed matters or where the task is simple enough for one model to handle cleanly, Heavy mode is overkill.
When Heavy is worth the latency and cost
The rule of thumb from community observation: use Heavy when the cost of an error is higher than the cost of latency and the $300/month subscription. High-stakes compliance review, medical document analysis, and investment research are the suggested use cases from multiple sources. Routine coding tasks, creative writing, and quick factual lookups are not.
What This Means for Coding Workflows
Strengths — complex reasoning, ambiguous requirements, multi-step problems
For coding tasks specifically, the 4-agent architecture's strengths map to where single-model coding assistants tend to fail:
Ambiguous requirements: Benjamin generates code, Lucas immediately challenges whether the implementation matches the stated requirements, Harper checks for documentation precedents. This catches interpretive mistakes before the user reviews a diff.
Multi-file or multi-system problems: When a coding task spans multiple components — an API change that cascades across services, a data model migration with downstream effects — the parallel agents can decompose by component and recombine at synthesis.
Math-heavy implementations: Benjamin's formal verification role means numerical and algorithmic code gets scrutinized beyond "does this look syntactically correct?" This is where the hallucination-reduction claim is most practically meaningful for developers.
Weaknesses — latency, cost, single-model still wins often
The latency is real and measurable. For simple, self-contained coding tasks — fix this typo, generate this boilerplate, explain this function — a single-model response from Claude or GPT-5.4 arrives faster and the multi-agent overhead adds nothing. Community testers consistently report that Grok 4.20 is "slower for simple queries" despite its strengths on complex ones.
No self-hosting path exists. Grok 4.20's weights are not publicly available; the entire system runs on xAI's infrastructure. Teams with data sovereignty requirements or compliance constraints on where code is processed cannot use it.
The cross-agent arbitration logic is opaque. You see the synthesized output; you don't see which agent won which disagreement or on what basis. For debugging or auditing agent behavior, this is a meaningful limitation compared to orchestration frameworks where you define the arbitration logic yourself.
In-Model Multi-Agent vs External Multi-Agent Platforms
Grok's internal sub-agents vs Claude sub-agents vs external parallel agent platforms
Grok 4.20's multi-agent system is an in-model architecture — the agent coordination happens inside xAI's infrastructure, with a single API call producing the synthesized output. This is architecturally different from external multi-agent platforms where developers orchestrate separate model calls with explicitly defined handoffs.
| Dimension | Grok 4.20 in-model | External orchestration (LangGraph, CrewAI) | Parallel worktree platforms (Verdent, OMX) |
|---|---|---|---|
| Control | Opaque — arbitration by xAI | Full — you define every handoff | Varies — platform-defined with config |
| Latency | Higher than single-model, lower than chained calls | Scales with # of calls + orchestration overhead | Depends on parallelism strategy |
| Customization | None — role definitions are fixed | Complete — any role, any model, any logic | Config-driven within platform constraints |
| Cost | Single API call (more tokens) | Multiple API calls | Platform pricing + underlying model |
| Transparency | Cross-agent debate not auditable | Full observability over each agent turn | Platform-level logging |
| Setup overhead | Zero — use grok-4.20-multi-agent-0309 | High — build and maintain orchestration layer | Medium — install and configure platform |
Claude sub-agents within Claude Code Routines or external Claude Code sessions represent a different hybrid: Claude as the orchestrator spinning up subagents for specific subtasks, with the developer controlling the orchestration logic. That gives you transparency and control that Grok 4.20's in-model approach doesn't, at the cost of more engineering work.
Where each approach fits — and where it breaks down
In-model multi-agent (Grok 4.20) fits when: you want cross-verification without building the orchestration layer yourself, latency is acceptable for your use case, and task types match Grok's role specializations (research-heavy, math-heavy, or multi-domain reasoning).
External orchestration fits when: you need full control over agent roles and arbitration logic, you need to mix models (Claude for planning, GPT for execution, Grok for research), or you need the workflow to be auditable and debuggable at each step.
Parallel worktree platforms fit when: you're working on codebases where multiple agents need to work on independent branches simultaneously — the isolation primitive is git-level, not reasoning-level. Tools like oh-my-codex or Verdent's multi-agent deck handle filesystem isolation and branch coordination, which is a different problem than Grok 4.20's cross-agent reasoning verification.
The two approaches are not competing for the same slot in a stack. A team could reasonably use Grok 4.20 for complex research and compliance-sensitive reasoning tasks while using an external orchestration platform for parallel codebase work on independent branches.
Pricing, API Access, and Availability
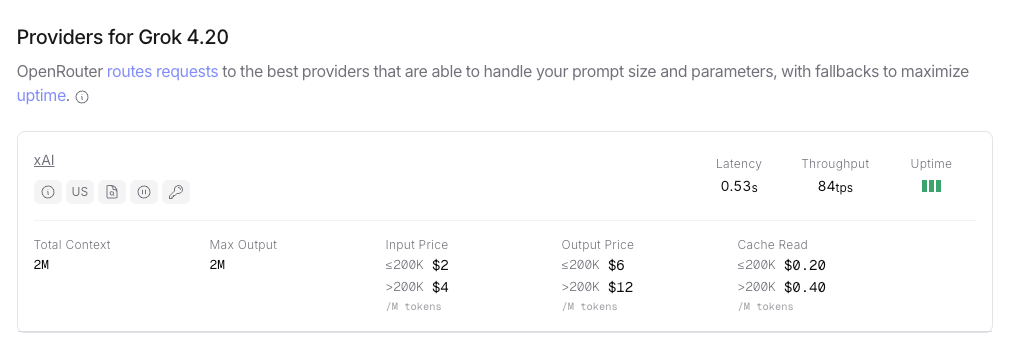
API pricing (as of April 2026): Grok 4.20 is priced at $2.00/M input tokens, $6.00/M output tokens via the xAI API and OpenRouter. This is the flat rate across non-reasoning, reasoning, and multi-agent variants. The reasoning and multi-agent variants consume more output tokens due to reasoning traces and internal agent communication, so effective per-query cost is higher for those modes.
Subscription access:
- Free tier: grok.com, usage limits apply
- SuperGrok: ~$30/month, unlimited Grok 4.20 access
- X Premium+: ~$40/month bundled with X platform
- SuperGrok Heavy: $300/month, 16-agent Heavy mode
Model IDs in the API:
grok-4.20-0309-reasoninggrok-4.20-0309-non-reasoninggrok-4.20-multi-agent-0309
All three share the same token pricing. The multi-agent variant exposes the 4-agent architecture through a single API call — coordination happens server-side, not in your client code.
Cursor: Grok 4.20 is listed in Cursor's model documentation, accessible through Cursor's model selector with a 200K default context window and up to 2M in long-context mode.
Known Limits and Open Questions
Rapid-learning updates and stability trade-offs
xAI described Grok 4.20 as updating its capabilities on a weekly cadence based on real-world usage — with release notes accompanying each update. This is unusual for a production model: most labs train a model, ship it, and version-freeze until the next major release. Weekly updates introduce a stability question: a prompt that worked last week may behave differently this week, and the model ID alone doesn't guarantee consistent behavior across updates.
For developers building on Grok 4.20, this means testing assumptions more frequently than you would with a version-frozen model. The flexibility to specify grok-4.20-0309 (a date-pinned model ID) exists and is recommended for production workflows where consistency matters.
No public transparency on cross-agent arbitration logic
The internal debate and arbitration mechanism is documented at the behavioral level — agents argue, Grok decides — but the decision logic is not publicly specified. When two agents disagree, what determines which wins? Is it confidence scores, majority rule, source authority, Grok's own reasoning? xAI has not published this. For applications where the reasoning path matters — compliance, medical, legal — the opacity is a meaningful audit limitation. You can observe that cross-verification happened; you cannot observe how it resolved.
FAQ
Is Grok 4.20 good for coding?
For complex, multi-step coding tasks — particularly those requiring mathematical reasoning, cross-file consistency, or verification against documentation — the multi-agent architecture produces measurably better results than single-pass inference in user reports. For simple, self-contained tasks, single-model alternatives are faster and cheaper. The practical test: if the task would benefit from an adversarial reviewer catching errors in your implementation plan, Grok 4.20's contrarian Lucas agent is doing exactly that internally.
How do I access it?
Via grok.com (free tier with limits), SuperGrok ($30/month), or the xAI API (grok-4.20-multi-agent-0309). Cursor also supports Grok 4.20 via its model selector. Heavy mode (16 agents) requires the SuperGrok Heavy subscription at $300/month.
What's the difference between Beta, Beta 2, and Heavy?
Beta launched February 17, 2026 — the initial public release with the 4-agent system. Beta 2 launched March 3, 2026 — five targeted fixes: better instruction following, fewer capability hallucinations, improved LaTeX support, more accurate image search, better multi-image rendering. Heavy is the 16-agent variant available to SuperGrok Heavy subscribers, confirmed by Musk in March 2026 as "extremely fast for deep analysis."
Is it the same as Grok Code Fast 1?
No. Grok Code Fast 1 is an entirely separate model — a purpose-built coding model with its own architecture, released in late 2025, initially under the codename "sonic." It's a smaller, faster, cheaper model ($0.20/$1.50 per million tokens) focused on agentic coding tool use with grep, terminal, and file editing. It integrates with Cursor, Cline, Kilo Code, and others. It does not use the 4-agent cross-verification architecture of Grok 4.20.
Does it work in Cursor?
Yes. Grok 4.20 is listed in Cursor's model documentation. The integration uses a 200K default context window with up to 2M in long-context mode. Note that Cursor presents Grok 4.20 as a single model interface — the multi-agent coordination happens server-side; you don't select between variants within Cursor's interface.
Bottom Line
Grok 4.20's multi-agent architecture is a real architectural difference from single-model inference, not a marketing description of something that already exists. The cross-verification mechanism between Harper, Benjamin, and Lucas — running in parallel, debating before synthesis — is the source of both its accuracy improvements and its latency/cost tradeoffs.
Two things to hold simultaneously: the architecture is meaningfully different, and the specific agent names and internal logic are community-documented rather than officially specified. The system works as described at the behavioral level; the internals are opaque.
For coding teams, the decision is practical. Use Grok 4.20 multi-agent when you're working on tasks complex enough that internal adversarial review adds value. Use simpler, faster single-model alternatives when you're not. The two paths address different points on the complexity-speed-cost tradeoff curve — they're not interchangeable, and understanding where each fits is more useful than declaring one universally better.
Related Reading
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- What Is oh-my-codex (OMX)? Orchestration Layer for Codex CLI
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
- Superpowers vs Vibe Coding: Structured Agents vs Freeform Prompts
