
Fable 5 became the Claude Code default for Pro and Max on June 9, 2026, and the instinct is to assume newer-and-more-capable means better-for-your-work. Not so fast. Fable 5 costs exactly 2× Opus 4.8, burns roughly 2× the usage credits after June 22, can fall back to Opus 4.8 on certain requests, and — per independent testing — landed mid-table on real vulnerability-fixing tasks while racking up record timeouts. The upgrade question isn't "is Fable 5 more capable?" (it is, on benchmarks). It's "does upgrading my working Opus 4.8 setup actually pay off, or does the cost and fallback overhead drag it down?" Here's the honest trade-off.
Pricing and behavior verified against Anthropic's official documentation and independent testing as of June 2026. This is a fast-moving rollout — the usage-credits change took effect June 22, 2026 — so confirm current details at the official Claude API docs before deciding.
Fable 5 and Opus 4.8 in One Paragraph
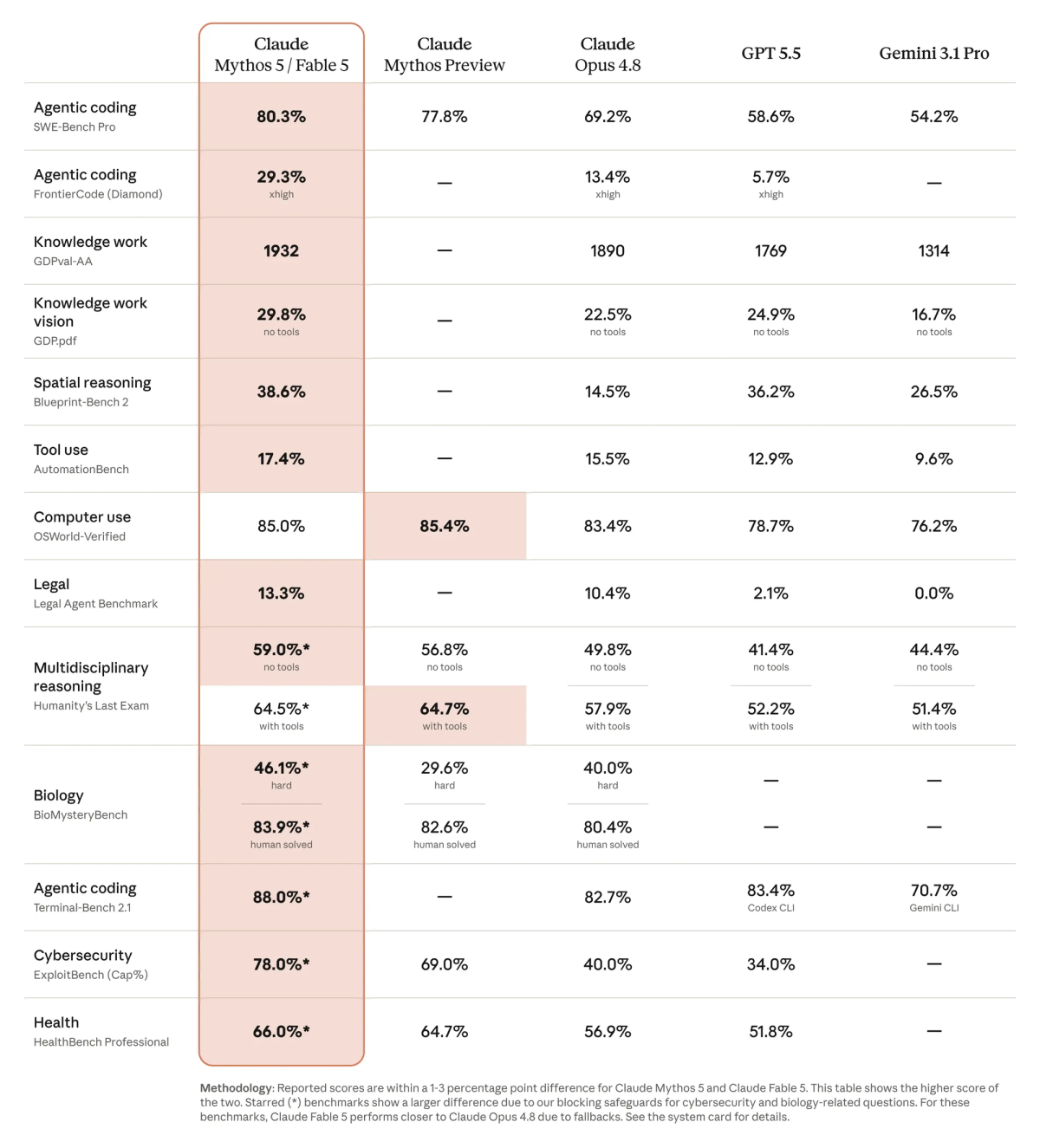
Fable 5 is Anthropic's first generally available Mythos-class model (a tier above Opus), released June 9, 2026, built for long-horizon agentic work. Opus 4.8 is the established frontier Opus-line model — highly capable, half the cost, and the model Fable 5 falls back to when it declines a request. Both share a 1M-token context window and a January 2026 knowledge cutoff. The headline difference for builders is cost: Fable 5 is $10/$50 per million input/output tokens versus Opus 4.8's $5/$25 — exactly 2×. The decision isn't about which model is more capable in the abstract; it's whether Fable 5's capability advantage on your specific work justifies twice the cost and the fallback overhead.
The Upgrade Question — What Actually Changes
Long-running task reliability
Fable 5's clearest advantage is long-horizon autonomous work — extended coding sessions where the model maintains coherence across many steps. This is the use case Anthropic built the Mythos tier for, and where Fable 5's capability gap over Opus 4.8 is most real. If your workflow involves ambitious multi-hour autonomous runs, Fable 5's stamina is the upgrade's strongest justification.
But there's a documented caveat. Independent testing (more below) found Fable 5's always-on extended thinking caused an unusually high rate of per-instance timeouts on long tasks — the very long-running scenarios where it's supposed to shine. The reliability advantage is real when the agent gets fast feedback (e.g., a terminal flagging errors immediately), but the extended-thinking overhead can work against it on tasks without tight feedback loops. The upgrade helps long-running reliability conditionally, not universally.
Multi-file code changes and migrations
For changes spanning many interconnected files — large refactors, framework migrations — Fable 5's stronger reasoning helps track cross-file dependencies. This is genuine territory for the upgrade: the kind of work that strains weaker models benefits from the Mythos-class capability. If you regularly do large migrations and find Opus 4.8 losing track on the biggest ones, Fable 5 is worth testing on exactly those tasks.
One cost wrinkle to know: Fable 5 uses the tokenizer introduced with Opus 4.7, which produces roughly 30% more tokens for the same text than older models. On large multi-file work, that token inflation compounds with the 2× per-token price — so a big migration can cost meaningfully more than the headline 2× suggests. Factor this into the ROI for large-context work specifically.
Testing and self-verification depth
Fable 5's agentic strength includes running tests and iterating within the agent loop. With its stronger reasoning, the self-verification loop tends to be more reliable — it catches and fixes more of its own errors before handing back. On benchmarks where the harness gives immediate error feedback (like Terminal-Bench), Fable 5 and Opus 4.8 stay close, which tells you the gap narrows when the workflow provides good feedback signals.
The practical read: if your Claude Code setup already has strong feedback loops (tests that run automatically, linters, fast error surfacing), the self-verification advantage of Fable 5 over Opus 4.8 shrinks — Opus 4.8 with good feedback performs close to Fable 5. The upgrade matters most when you're relying on the model's raw capability rather than workflow feedback to catch errors.
What Independent Testing Shows (Beyond Vendor Benchmarks)
Anthropic's published benchmarks show Fable 5 leading (high SWE-Bench scores). Those are vendor numbers. The more useful signal for an upgrade decision comes from independent testing on realistic tasks, which tells a more nuanced story.
Endor Labs: mid-table on real vuln-fix tasks, extended-thinking timeouts
Endor Labs benchmarked Fable 5 (with Claude Code) on 200 real-world vulnerability-fixing tasks. The result was, in their words, an average scorecard with a twist. Fable 5 landed mid-table on their leaderboard — 59.8% FuncPass and 19.0% SecPass — not the standout the launch hype implied. Their conclusion was pointed: AI may find a bug, but often doesn't understand the underlying vulnerability or how to fix it properly.
Two specific findings matter for an upgrade decision. First, Fable 5's extended thinking caused more per-instance timeouts than any model-and-harness combination Endor Labs had ever tested, directly costing it points — the extended-thinking overhead is a real liability on some tasks. Second, the twist: Fable 5 solved four vulnerability-fixing tasks no previous model-and-agent combination had ever solved (flaws in Streamlit, jwcrypto, lxml, and scrapy-splash). So the picture is genuinely mixed — average overall, with occasional breakthroughs on the hardest problems.
Why lab benchmarks and your workload can diverge
The Endor Labs result illustrates the central point: a model can lead one benchmark (Anthropic's offensive-security evals) and land mid-table on another (Endor's safe-code-fixing tasks), because they measure different things. Anthropic's headline cyber benchmarks mostly measure offensive progress (exploit generation, vulnerability reproduction); Endor's tests whether the agent writes safe production code that fixes the vulnerability while preserving functionality. Different capability, different result.
For your upgrade decision, the lesson is that no benchmark — vendor or independent — predicts performance on your specific workload. The only reliable signal is testing Fable 5 against Opus 4.8 on your actual tasks. The benchmarks tell you the upgrade is plausible; your own A/B test tells you whether it pays off.
The Hidden Cost: Fallback and Credit Overhead
When coding requests fall back to Opus 4.8
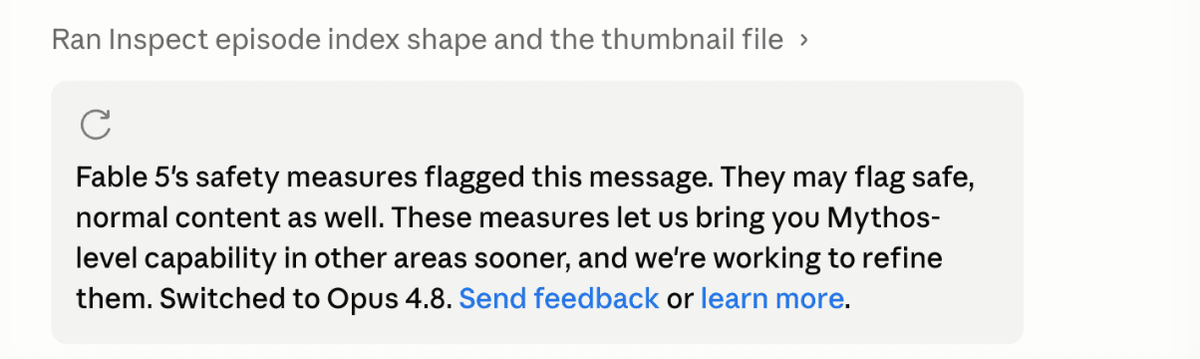
Fable 5 includes safety classifiers that decline requests in high-risk domains (cybersecurity, biology/chemistry, and reasoning-extraction/distillation). When it declines, the request falls back to Opus 4.8. A classifier refusal returns as a successful response (HTTP 200 with a refusal stop reason), not an error, and Anthropic doesn't bill for a request refused before output. For coding work touching security tooling or related domains, expect some requests to route to Opus 4.8 rather than run on Fable 5.
Official ~5% claim vs community-reported reality
Here's where the two-sided picture matters. Anthropic estimates this rerouting happens in fewer than 5% of queries, and says it considers that conservative. But Anthropic also notes the rate varies a lot by work type — and that's the catch. Anthropic's own system card reports that on Terminal-Bench, 20.9% of Fable trials hit a safety refusal and fell back to Opus 4.8 — far above the 5% average, on a coding-relevant benchmark. There's no public baseline for typical coding workloads, so the honest framing is: the average may be under 5%, but security-adjacent or certain coding tasks can trigger fallback at much higher rates. If your work is in or near the flagged domains, budget for materially more fallback than the headline 5%.
The implication for upgrade ROI: if a meaningful share of your requests fall back to Opus 4.8 anyway, you're paying Fable 5 prices for Fable 5 to decline and Opus 4.8 to do the work — which weakens the case for defaulting to Fable 5 on fallback-prone workloads.
June 22 usage credits: Fable burns ~2x Opus per task
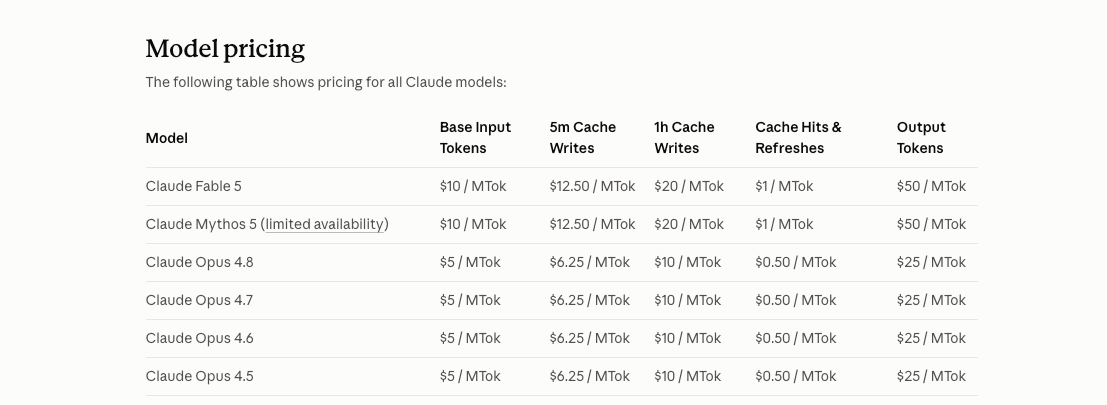
The cost reality that most directly affects throughput: on June 22, 2026, Anthropic's usage-credits system for Claude Code Pro/Max took effect, and Fable 5 consumes roughly 2× the credits of Opus 4.8 per task (tracking its 2× API cost). For a Pro/Max subscriber, this effectively halves your monthly throughput if you run Fable 5 as the default versus staying on Opus 4.8 — each task eats about twice the quota. (Exact credit ratios weren't published as a final table at launch; treat the 2× figure as a working approximation and verify against your own usage.)
For an engineering manager doing ROI math: defaulting your team to Fable 5 roughly doubles per-task cost and halves quota-bound throughput. That's justified only if Fable 5's capability advantage on your team's actual work is worth it — which, given the mixed independent results, is exactly what you should A/B test before committing.
When to Upgrade vs Stay on Opus 4.8
Upgrade if
Upgrade to Fable 5 if your work is genuinely ambitious long-horizon coding — complex migrations, hard multi-step implementations, research-grade tasks where you're pushing against Opus 4.8's ceiling and the extra capability would change outcomes. If you regularly hit tasks Opus 4.8 can't complete cleanly, Fable 5's capability advantage may justify the cost. The upgrade pays off when you're capability-bound, not when you're doing routine work.
Stay on Opus if
Stay on Opus 4.8 if you have a stable, working coding workflow, if you're cost-sensitive (it's half the price and half the credit burn), if your work is high-volume routine editing where the capability gap doesn't matter, or if your work is in fallback-prone domains (security, bio/chem) where a meaningful share of requests would route to Opus 4.8 anyway. For most everyday coding, Opus 4.8 with good feedback loops performs close enough to Fable 5 that the 2× cost isn't justified. A hybrid is often best: Opus 4.8 as the default, Fable 5 reserved for the specific hard tasks that need it.
A point that outlasts this particular model comparison: the biggest reliability gains usually come from the workflow, not the model upgrade. A disciplined workflow — Plan-First decomposition, diff review, tests that give the agent feedback, and rollback when something goes wrong — improves outcomes more reliably than swapping to a pricier model. Workflow-layer tools like Verdent formalize that structure (planning, isolated execution, verification gates), and the principle holds regardless of whether you run Opus 4.8 or Fable 5 underneath: a better workflow beats a more expensive model for most real engineering.
FAQ
Is Fable 5 better than Opus 4.8 for coding?
On benchmarks, Fable 5 scores higher — it's a Mythos-class model, a tier above Opus. In practice, "better for coding" depends on your work. For ambitious long-horizon tasks and complex migrations, Fable 5's capability advantage is real. For routine coding with good feedback loops, Opus 4.8 performs close to Fable 5 at half the cost — and independent testing (Endor Labs) found Fable 5 landed mid-table on real vulnerability-fixing tasks with record timeouts, so the lead isn't universal. It's better on the hardest work, roughly equivalent (and cheaper to run on Opus) for everyday coding. Test on your actual tasks.
How should builders A/B test Fable 5 against Opus 4.8?
Run the same representative tasks on both and measure what matters: completion rate, correctness, cost per task, and time-to-done. Pick tasks that reflect your real distribution — a mix of routine edits, multi-file changes, and your hardest migrations. Track how often Fable 5 falls back to Opus 4.8 (it shows in your usage), since fallback-heavy workloads weaken Fable 5's case. Compare cost-per-successful-task, not just raw capability — Fable 5 winning a task at 2× the cost may not beat Opus 4.8 winning it more cheaply. The goal is cost-adjusted outcome on your work, not benchmark scores.
Does the Opus 4.8 fallback make Fable 5 unreliable for agents?
Not unreliable, but it adds overhead to plan for. Anthropic estimates fallback under 5% of queries on average but says it varies by work type — and its own system card shows 20.9% fallback on Terminal-Bench. For security-adjacent coding, expect higher than 5%. The fallback is handled cleanly (refusals aren't billed, the request routes to Opus 4.8), so it's not a reliability failure — but if much of your work falls back, you're paying Fable 5 prices for Opus 4.8 results, an ROI problem more than a reliability one.
Is the ~2x cost worth it for daily coding?
For most daily coding, no. Fable 5 costs 2× Opus 4.8 per token and burns ~2× the credits (after June 22, 2026), effectively halving quota-bound throughput. Where Opus 4.8 with good feedback loops performs close to Fable 5, the premium isn't justified. The 2× cost is worth it for ambitious long-horizon tasks and hard migrations where capability changes outcomes. The cost-effective pattern for most teams is hybrid: Opus 4.8 as the default, Fable 5 for the specific hard tasks that need it.
Related Reading
