
The difference between a coding-agent loop that helps and one that quietly burns a week's token budget is almost never the model. It's whether the loop knows when it's done, when to stop trying, and when to hand control back to you. A loop without those is just an agent running in a while True with no floor — it'll happily churn code forever, or confidently "finish" something broken. This guide is the practical build: a loop with an observable contract, isolated execution, a real check on every iteration, review gates where they matter, and exit and recovery paths that stop it safely. The components are tool-agnostic — they apply whether you're wiring up Claude Code, Codex, or your own harness.
Define the Loop Contract
Turn the task into observable acceptance criteria
A loop needs a contract before it needs anything else: a definition of "done" the loop itself can check. This is the single most important design decision, because everything downstream — when to stop, when to retry, when to escalate — depends on it. "Improve the module" is not a contract; the loop can never know it's satisfied. "All tests in auth/ pass, the linter returns zero errors, and the new endpoint returns 200 for a valid request" is a contract, because each clause is observable — the loop can run a check and get an unambiguous yes or no.
Write the acceptance criteria as concrete, machine-checkable conditions: tests that must pass, commands that must exit zero, outputs that must match. If a criterion can only be judged by a human ("the code is clean"), it isn't part of the automated contract — it belongs at a review gate (below), not in the loop's exit logic. The discipline is to push as much of "done" as possible into observable checks, so the loop's self-assessment means something rather than being the agent's own opinion of its work.
Set retry limits and escalation conditions
The contract also has to define failure, not just success. Decide upfront: how many attempts the loop gets before it stops (a hard iteration cap), what budget it may spend (a token or time ceiling), and what triggers an escalation to a human rather than another retry. Without these, a loop that can't solve the problem doesn't fail — it spins, retrying indefinitely while cost accumulates and nothing improves.
Set a concrete iteration cap and a budget ceiling, and treat hitting either as a stop-and-escalate event, not a "try harder" signal. Distinguish the conditions that warrant a retry (a transient error, a test that failed in a way the agent can diagnose) from those that warrant immediate escalation (repeated identical failures, an error the agent can't interpret, a check that's regressing). A loop that retries the same action after the same failure isn't making progress; the retry rules are what prevent that spin.
Isolate the Execution Environment
Assign branches or worktrees before agents edit
Before the agent touches any code, give it an isolated place to work. A git worktree — a native git feature that checks out a branch into a separate working directory — lets the loop operate on a real copy of the repository without touching your main branch or other work. Assign the worktree (or at minimum a dedicated branch) before the first edit, so everything the agent does is contained and nothing lands on your trunk by accident.
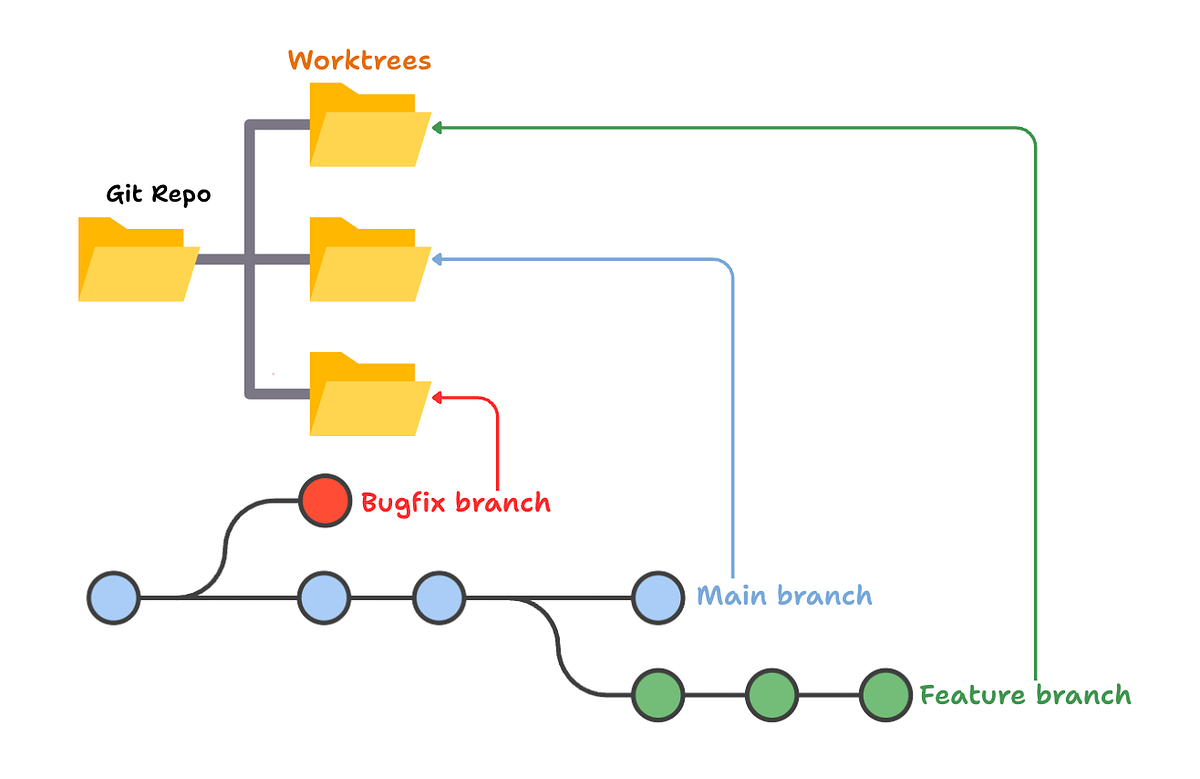
This isolation does two jobs: it contains mistakes (a bad change is confined to the branch, not your working tree), and it makes the loop's output reviewable as a discrete unit (a branch you can inspect, test, merge, or discard as a whole). It's the same discipline of keeping each agent's work in its own space, so a failed attempt is thrown away cleanly rather than untangled from everything else. Isolation first, edits second.
Keep credentials and destructive tools scoped
The loop runs unattended, so scope what it can reach to what the task actually needs. Give the loop its own scoped identity rather than your personal credentials — an agent committing under your name with your full access is both an attribution problem and a blast-radius problem. Limit the tools it can call to the ones the task requires, and be especially deliberate about destructive operations (force-push, deleting branches, anything touching production, anything that spends money).
The principle is least privilege: an unattended loop with broad credentials and unrestricted tools is a much larger risk than the same loop scoped to a sandbox with a service identity and a narrow toolset. Decide what the loop may do before it runs, default to the minimum, and expand only with evidence — because an autonomous loop will exercise exactly the permissions you gave it, including the ones you forgot to restrict.
Run the Action-and-Check Cycle
Let the agent make one bounded change
The heart of the loop is a tight cycle: the agent makes a change, the loop checks it, the result feeds the next iteration. Keep each change bounded. An agent that rewrites half the codebase in one step produces a result you can't diagnose when it fails — you don't know which part of the sprawling change broke things. A small, focused change per iteration (fix this function, add this test, handle this case) keeps each step diagnosable and each failure attributable.
This is the reason-then-act rhythm at the core of agent loops, formalized in the reason-and-act pattern: the agent reasons about the next step, takes one action, observes the result, and reasons again. Small steps make that observation meaningful — when the check runs after a bounded change, its result tells you something specific, which is what lets the loop course-correct rather than thrash.
Run tests and capture structured results
After each change, run the check — and make it a real, independent check, not the agent's own claim that it succeeded. Run the test suite, the linter, the type checker, the build; whatever the contract specified as observable. The feedback the loop acts on is only as honest as these checks, so the validation has to be something other than the agent grading its own homework.
Capture the results in a structured form the next iteration can use. A raw error dump is less useful than structured feedback: which check failed, the relevant error, the code involved, and whether this is a new failure or a repeat of one already seen. Flagging repeated-versus-new failures matters specifically because it's how the loop detects it's stuck — the same error twice is a signal to change approach or escalate, not to retry identically.
Route failures back into the next attempt
When a check fails, the loop feeds that failure back as the input to the next attempt — but route it deliberately. The next iteration should get the structured failure (what broke, in what code, with what error) so the agent can diagnose and adjust rather than guess. This is where a loop either learns or spins: a loop that feeds back "it failed, try again" with no detail invites the same failure; a loop that feeds back "this specific test failed with this error in this function" gives the agent something to reason about.
Crucially, before routing a failure into another attempt, check it against your retry rules. If this is the Nth identical failure, or the budget is exhausted, the failure routes to escalation, not to another iteration. The action-and-check cycle and the retry limits work together: the cycle drives progress, the limits prevent it from becoming an infinite, expensive loop that never converges.
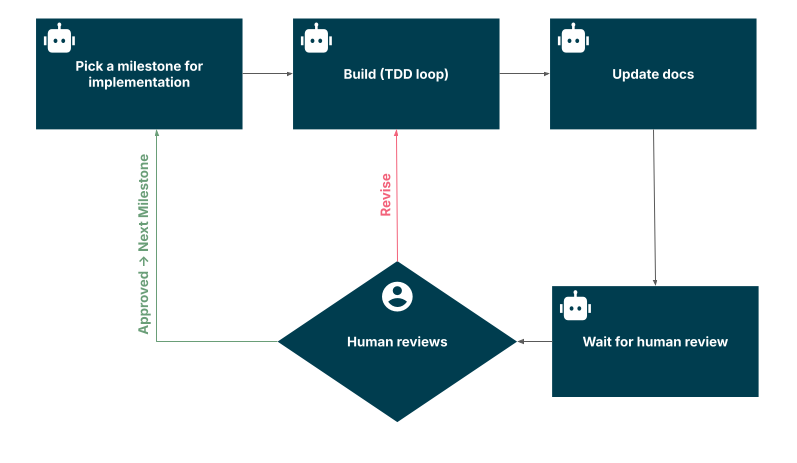
Add Review Gates
Compare the plan, diff, and test evidence
A review gate is a point where the loop pauses for a human to look before it proceeds. Where you place gates is a mechanism question (this section); which categories of action must always pass through one is a policy question that belongs to your human-in-the-loop rules. Mechanically, the most useful gate gives the reviewer three things together: the plan (what the agent intended), the diff (what it actually changed), and the test evidence (what the checks show). Seeing all three at once is what makes review fast and meaningful — you can confirm the change matches the intent and the evidence supports it, rather than reverse-engineering what happened from a diff alone.
Build the gate so it surfaces these together at the decision point, with a clear approve/reject that the loop respects. The planning-then-execution structure that tools like Verdent formalize as Plan-First makes this gate natural: when the agent produces a plan before acting, the reviewer has the intent to compare the diff against, which turns review from guesswork into a check.
Stop for architectural or security-sensitive decisions
Some decisions shouldn't be made by an unattended loop at all, and the gate is where you stop for them. Mechanically, this means the loop detects a class of change and halts for approval before proceeding rather than at the end. The detection can be as simple as path-based (changes under a security-sensitive directory pause automatically) or criteria-based (changes that touch authentication, data handling, public interfaces, or infrastructure).
The mechanism to build is a conditional stop: when the agent's proposed change matches a flagged category, the loop pauses and routes to a human before applying it, regardless of where it is in its iteration count. This is distinct from the end-of-loop review — it's an inline gate that catches high-stakes changes the moment they're proposed, so a security-relevant edit never gets applied autonomously just because it happened mid-loop. (Which categories qualify as "must stop" is a policy decision; the gate is how you enforce whatever policy you set.)
Define Exit and Recovery Paths
End when acceptance criteria are met
The loop's happy exit is simple if the contract was well-defined: when every acceptance criterion checks out — all specified tests pass, all commands exit clean, all observable conditions are met — the loop is done and stops. This is why the contract matters so much: a precise, observable definition of done gives the loop a clean, unambiguous exit. A vague one means the loop never confidently terminates, which is how "done" loops keep running.
When the criteria are met, have the loop stop and present its result for final review rather than auto-merging — the acceptance checks confirm the change satisfies the contract, but the final human review (the gate above) is what confirms it's something you'll actually accept. Met criteria are necessary for done, not always sufficient for merge.
Preserve state when the loop cannot continue
The unhappy exit matters as much as the happy one. When the loop hits its retry cap, exhausts its budget, or can't make progress, it has to stop in a recoverable state, not just halt. Before exiting on failure, preserve what's useful: commit the partial work to the branch (so it isn't lost), record the loop's log (what it tried, what failed, where it got stuck), and leave the worktree/branch intact for a human to inspect.
The goal is that a failed loop hands a person everything they need to pick up where it left off — the partial changes, the failure history, and the state. Because the work was isolated in its own branch/worktree, this preservation is clean: the partial result is a discrete artifact someone can examine, salvage from, or discard. A loop that fails by vanishing its work forces a restart from scratch; a loop that fails by preserving state turns a dead end into a handoff.
FAQ
How should flaky tests affect retry decisions?
Flaky tests (ones that pass or fail nondeterministically) corrupt a loop's feedback signal, so handle them before they drive bad retries. The danger is a loop reacting to a flaky failure as if it were real — retrying, "fixing" something that wasn't broken, and churning. The defenses: identify known-flaky tests and treat their results as low-confidence (re-run before acting on a failure, or quarantine them from the acceptance criteria), and watch for the signature of flakiness — a check that fails then passes with no relevant change. If the loop's exit depends on a flaky test, it may never terminate or may terminate falsely, so a reliable acceptance signal means either stabilizing those tests or excluding them from the contract. The loop's decisions are only as trustworthy as the checks behind them.
What state must survive when an agent restarts?
Enough for the loop (or a human) to continue without redoing finished work or repeating failed approaches. Concretely: the committed partial changes (so completed work survives), a log of what's been attempted and the outcomes (so the restart doesn't repeat a known failure), the current position against the acceptance criteria (what's done, what remains), and any decisions already made or approved. The principle is that a restart should resume, not reset — without preserved state, a restarted loop relitigates solved sub-problems and re-encounters the same dead ends. Persisting state to the branch and a durable log, rather than holding it only in the agent's context, is what lets a loop survive a restart, a crash, or a handoff between a machine and a person.
How can parallel loops avoid editing identical files?
Assign non-overlapping ownership before launching them, and isolate each in its own worktree. The isolation (separate worktrees) prevents the loops from corrupting each other's working state mid-run, but it doesn't prevent two loops from independently editing the same file and producing changes you must later reconcile at merge. So the real prevention is upfront design: scope each parallel loop to a distinct area of the codebase (one to the API layer, one to the frontend, one to tests) so their file ownership doesn't overlap. When loops genuinely must touch shared files, sequence those parts rather than running them truly in parallel. Designing non-overlapping ownership before launch is far cheaper than untangling conflicting parallel edits afterward, and the worktree isolation is the safety net, not the whole solution.
When should a failed loop escalate to an engineer?
When retrying has stopped being productive — which your retry rules should define concretely. Escalate when the loop hits its iteration cap or budget ceiling, when it produces the same failure repeatedly (a signal it can't solve the problem with its current approach), when it encounters an error it can't interpret, or when a check is regressing rather than improving. The principle separating retry from escalate is whether the next attempt would have new information: if the loop is repeating an action that already failed identically, another attempt won't help and it should hand off to a human. Escalation isn't loop failure — it's the loop correctly recognizing the limit of what it can do autonomously and routing the problem to someone who can break the impasse, with its preserved state and failure log making that handoff useful rather than a cold start.
Conclusion
A coding-agent loop that stops safely isn't built from a clever model — it's built from the structure around it: an observable contract that defines done and failure, an isolated environment that contains the work, an action-and-check cycle that validates every step with independent checks, review gates where human judgment matters, and exit-and-recovery paths that stop the loop cleanly whether it succeeds or gives up. Get the contract and the stopping conditions right and the rest follows; skip them and you've built a confident, expensive way to generate unreviewed changes. The discipline that runs through all of it — observable checks, isolation, independent validation, deliberate gates — is what turns an autonomous loop from a liability into a multiplier. Build the loop to know when it's done, when to stop, and how to hand off, and it becomes something you can trust to run while you're not watching.
Related Reading
