
Here's something I keep getting asked in engineering channels lately: "Should we be running Nemotron 3 Super or something from the Qwen family for our coding agents?" The question makes sense — both are open-weight, both are competitive on coding benchmarks, and both have been making noise in the past few months. The answer isn't obvious. Let me break it down.
Version note: This comparison covers Nemotron 3 Super 120B-A12B (released March 11, 2026) against Qwen3-Coder-Next 80B-A3B (released February 3, 2026) and Qwen3.5-122B-A10B (the comparable-size Qwen MoE). All benchmark data is from official technical reports and independent third-party evaluations published no earlier than February 2026.
What Each Model Is Optimized For
Nemotron for agentic workflows

Nemotron 3 Super was built for one specific job: being the planning and orchestration brain in a multi-agent coding stack. NVIDIA's framing is explicit — when a pipeline needs to decompose complex tasks, hold full codebase context, and route work to multiple worker agents, that's where Super is positioned. It's not a general-purpose conversational model, and NVIDIA doesn't pretend it is.
The NVIDIA technical report (March 11, 2026) describes the post-training pipeline as three sequential phases: pretraining on 25 trillion tokens, SFT across agentic task types, and reinforcement learning against verifiable outcomes in 15 distinct agentic environments — including software engineering, cybersecurity, and financial analysis. The RL phase is what produces the model's strong multi-step reasoning and tool-call sequencing.
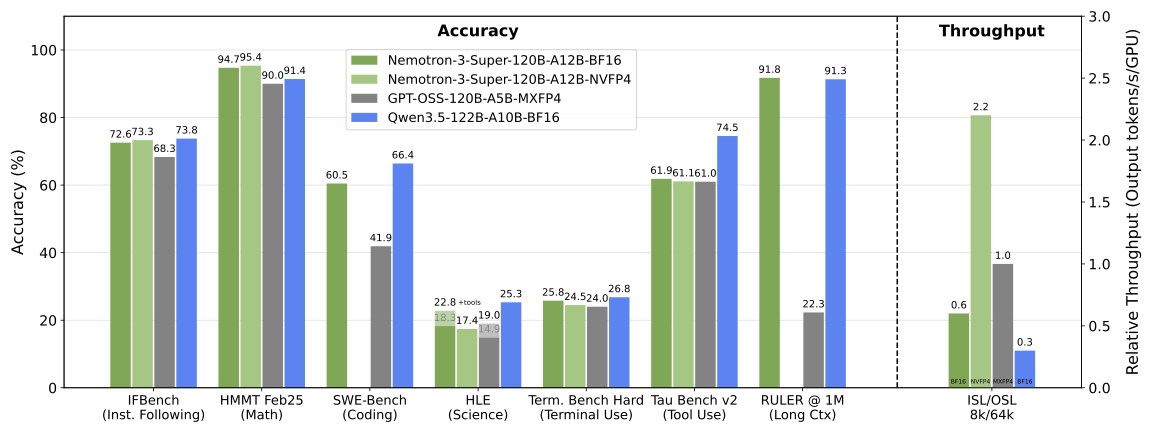
Where Nemotron 3 Super is not optimized: general knowledge breadth and conversational quality. Its Arena-Hard-V2 score of 73.88% trails GPT-OSS-120B's 90.26%, and its GPQA score of 79.23% lags behind Qwen3.5-122B's 86.60%. If you need a model for broad scientific Q&A or high-quality chat generation, this isn't the right choice.
Qwen for general coding strength
The Qwen family takes a broader approach. Qwen3-Coder-Next was trained on 800K verifiable executable tasks across agentic environments, with reinforcement learning for long-horizon reasoning, tool sequencing, test execution, and recovery from failing runs. But it also performs competitively across general knowledge benchmarks where Nemotron 3 Super gives ground — MMLU-Pro at 86.70% vs. Nemotron's 83.73%, GPQA at 86.60% vs. 79.23%.
Qwen3-30B-A3B scores 69.6% on SWE-Bench Verified and 91.0 on ArenaHard, positioning it competitively across both coding and conversational tasks. The larger Qwen3.5-122B-A10B pushes this further: it leads Nemotron 3 Super on SWE-Bench Verified (66.40% vs. 60.47%) and scientific reasoning while maintaining a comparable MoE efficiency profile.
Where Qwen is not optimized: long-context retention at extreme lengths. Qwen3.5-122B tops out at 128K context natively, and while Qwen3-Coder-Next supports 256K, neither matches Nemotron 3 Super's 1M token window. For pipelines that need to load entire large codebases into a single context without retrieval, that gap matters.
Architecture Differences That Matter
Active parameters and efficiency
Both models use Mixture-of-Experts to keep inference costs down, but the efficiency ratios are meaningfully different:
| Nemotron 3 Super | Qwen3-Coder-Next | Qwen3.5-122B | |
|---|---|---|---|
| Total parameters | 120B | 80B | 122B |
| Active parameters | 12B (10%) | 3B (3.75%) | 10B (~8.2%) |
| Architecture | Hybrid Mamba-2 + Transformer + LatentMoE | Hybrid GatedDeltaNet + Gated Attention + MoE | Dense Transformer MoE |
| Context window | 1M tokens (native) | 256K tokens | 128K tokens |
| License | NVIDIA Open Model License | Apache 2.0 | Apache 2.0 |
Nemotron 3 Super activates 12B parameters per forward pass. Qwen3-Coder-Next activates only 3B — making it dramatically cheaper to serve per token, runnable on consumer hardware (64GB MacBook, RTX 5090), and better suited for high-volume concurrent deployments on modest infrastructure.
Qwen3-Coder-Next's ultra-sparse MoE activates 10 out of 512 experts per token, allowing it to deliver reasoning capabilities that rival much larger systems while maintaining the low deployment costs and high throughput of a lightweight local model.
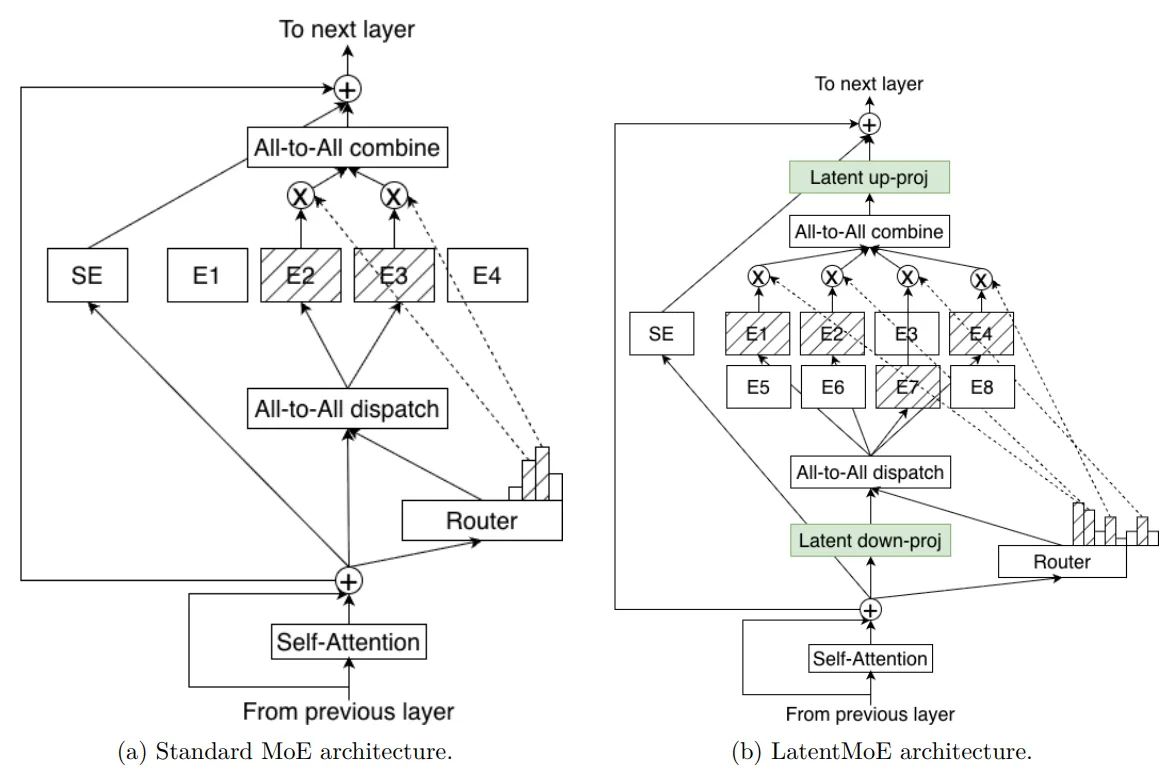
Nemotron 3 Super's three architectural innovations stack differently. LatentMoE compresses tokens from a 4096-dimension hidden space to 1024 before expert routing — a 4x compression that allows 512 total experts with 22 active per token at the same compute cost as a standard MoE with fewer experts. The Mamba-2 layers handle sequence processing with linear-time complexity. Multi-Token Prediction provides built-in speculative decoding.
The practical outcome: Nemotron 3 Super is optimized for serving efficiency at high output token volume with heavy context loads. Qwen3-Coder-Next is optimized for cost-per-task on shorter-context, high-frequency concurrent workloads.
Context and throughput implications
Nemotron 3 Super achieves up to 2.2x and 7.5x higher inference throughput than GPT-OSS-120B and Qwen3.5-122B respectively, on 8K input / 16K output settings. That throughput advantage is significant for multi-agent orchestration systems where many agents are running in parallel.
At 1 million tokens, Nemotron 3 Super scores 91.75% on RULER, while GPT-OSS-120B drops to 22.30%. Qwen3.5-122B's 128K hard cap means it simply can't compete on full-million-token retrieval tasks. Qwen3-Coder-Next reaches 256K natively with reasonable retention, but the 1M figure is only available via positional interpolation extrapolation — not the same as native training.
One practical caveat: the default context configuration for Nemotron 3 Super is 256K tokens due to VRAM constraints, with 1M accessible via explicit flag. So both models operate at 256K out of the box in most managed API environments; the 1M advantage requires deliberate infrastructure planning.
Coding and Tool-Use Comparison
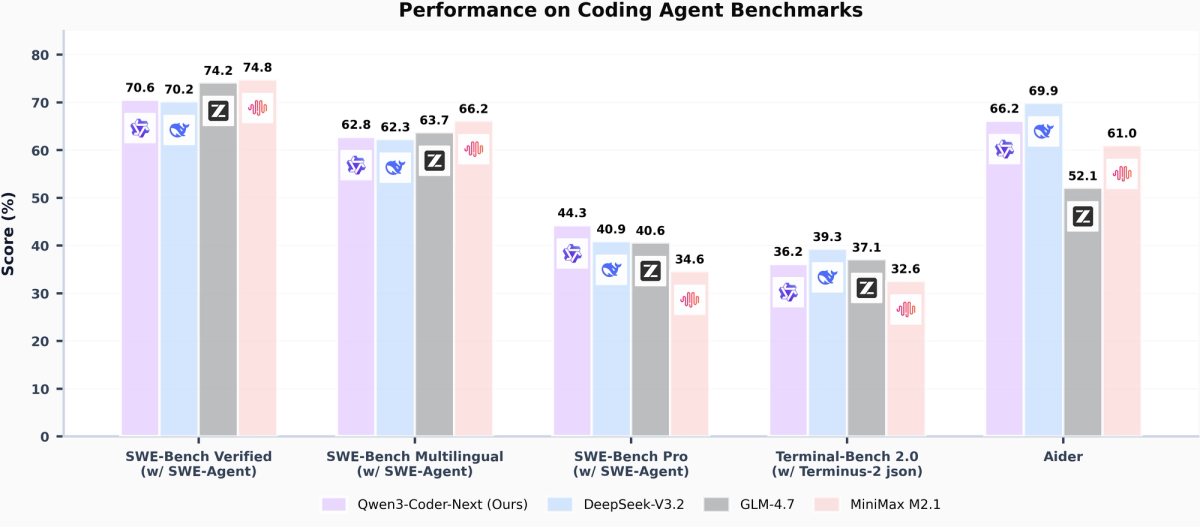
All scores below use the scaffolds and dates specified. Do not cross-compare numbers run on different harnesses — SWE-Bench Verified scores vary significantly based on the agent scaffold used.
SWE-Bench Verified — SWE-Agent scaffold (March 2026 data)
| Model | SWE-Bench Verified | SWE-Bench Multilingual | SWE-Bench Pro |
|---|---|---|---|
| Qwen3-Coder-Next 80B-A3B | 70.60% | 62.80% | 44.30% |
| Qwen3.5-122B-A10B | 66.40% | — | — |
| Nemotron 3 Super 120B-A12B | 60.47% (OpenHands) | 45.78% | — |
| DeepSeek-V3.2 | 70.20% | 62.30% | 40.90% |
| GLM-4.7 | 74.20% | 63.70% | 40.60% |
Sources: Qwen3-Coder-Next technical report (Feb 2026); NVIDIA technical report (Mar 2026); VentureBeat (Feb 4, 2026). Note: Nemotron figures use OpenHands harness; Qwen figures use SWE-Agent scaffold. Direct numerical comparison is illustrative, not definitive.
Important caveat on benchmark harnesses: Nemotron 3 Super's 60.47% figure uses the OpenHands agent scaffold. Qwen3-Coder-Next's 70.6% uses SWE-Agent. These two scaffolds produce systematically different scores on the same model — different tooling, different prompting, different pass@k strategies. The numbers above are not directly comparable in a strict sense. Both official technical reports use different harnesses, so take the cross-model delta with appropriate skepticism.
What the data does support clearly: at 60.47% on SWE-Bench Verified, Nemotron 3 Super sits roughly 6 points behind Qwen3.5 but delivers 2.2x the throughput — for multi-agent systems running many agents concurrently, that throughput-per-accuracy trade-off matters.
LiveCodeBench (independent, March 2026)
On LiveCodeBench — an independent benchmark that tests current, non-contaminated coding problems — Nemotron 3 Super scores 81.19% versus Qwen3.5-122B's 78.93%. This is one category where Nemotron leads Qwen at the comparable size tier, and it uses a benchmark less susceptible to training data contamination than older coding evaluations.
Tool calling
Qwen3-Coder-Next is explicitly tuned for tool calling and integrates with IDE and CLI environments such as Qwen-Code, Claude Code, Cline, and other agent frontends. It does not support thinking mode (<think> blocks) — responses are generated directly without visible reasoning steps.
Nemotron 3 Super supports both reasoning and non-reasoning modes. The GPQA "with tools" score (82.70%) jumps 3.5 points over the "no tools" variant — evidence that tool-calling training directly improves grounded reasoning, not just task execution.
Both models handle the 43 programming languages required for multilingual agent workflows. Qwen3-Coder-Next's SecCodeBench score of 61.2% (code vulnerability repair) beats Claude Opus 4.5 at 52.5% — a meaningful differentiator if security-aware code generation is part of your stack.
Deployment Differences
NIM vs common open-model routes
These two models have meaningfully different deployment ecosystems. Understanding the path to production matters as much as benchmark scores.
Nemotron 3 Super deployment options (as of March 13, 2026):
| Route | Details |
|---|---|
| NVIDIA NIM microservice | Packaged inference container; vLLM, TensorRT-LLM, SGLang supported |
| build.nvidia.com | Free-trial API access |
| Google Cloud Vertex AI, OCI, CoreWeave, Together AI | Managed cloud APIs |
| Hugging Face | BF16, FP8, NVFP4 checkpoints |
| Self-host | 8x H100-80GB minimum (BF16); 4x H100 viable at FP8 |
The NVIDIA NIM packaging is a genuine advantage for enterprise teams: standardized inference containers, SLA-backed cloud deployments, and a clear path to on-prem via NIM on private infrastructure. The tradeoff is that the license is the NVIDIA Open Model License, not Apache 2.0 — it's permissive for commercial use but includes a patent termination clause if you litigate against NVIDIA.
Qwen3-Coder-Next deployment options (as of March 13, 2026):
| Route | Details |
|---|---|
| Hugging Face | 4 weight variants: BF16, GGUF Q4/Q8, FP8 |
| Together AI | Production API, FP8 variant |
| Kaggle | Model hosting with free inference |
| Local (Ollama, LMStudio, llama.cpp) | Runs on 64GB MacBook, RTX 5090, RX 7900 XTX |
| License | Apache 2.0 — fully permissive commercial use |
Qwen3-Coder-Next achieves performance comparable to Claude Sonnet 4.5 on coding benchmarks while using only 3B activated parameters, making it feasible to run on high-end consumer hardware. For a developer who wants to run a powerful coding agent entirely locally — no API costs, full data control — Qwen3-Coder-Next is the most viable option in this tier as of March 2026. Nemotron 3 Super requires a minimum 8x H100-80GB setup to self-host; that's a meaningful barrier for individual developers or small teams.
API pricing comparison (March 2026, DeepInfra / Together AI spot pricing):
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Nemotron 3 Super | ~$0.10–$0.30 | ~$0.50–$0.80 |
| Qwen3-Coder-Next | ~$0.06–$0.18 | ~$0.20–$0.50 |
Prices vary by provider and will change. Check provider pages directly before budgeting.
Which One to Choose
Choose Nemotron 3 Super if…
- You're building a multi-agent orchestration system where one model needs to plan, decompose, and route complex tasks across worker agents — this is the explicit design target
- You need 1M token context that actually holds up under retrieval benchmarks (91.75% on RULER@1M), not just context that technically accepts 1M tokens
- You're running high-volume concurrent agent workloads on NVIDIA Blackwell infrastructure and the 2.2x+ throughput advantage materially reduces serving cost
- Your team needs enterprise deployment support — NIM packaging, cloud SLAs, and a clear path to on-prem private deployment through NVIDIA infrastructure
- Multilingual code is a priority: 45.78% on SWE-Bench Multilingual versus GPT-OSS-120B's 30.80% is a genuine differentiator for non-English codebases
- You want full training transparency: NVIDIA released weights, 10 trillion pretraining tokens, 40 million post-training samples, and 21 RL environment configurations
Don't choose it if you need Apache 2.0 licensing freedom, broad scientific reasoning depth, consumer-grade hardware deployability, or strong conversational quality alongside coding capability.
Choose Qwen 3 if…
- You want the highest raw SWE-Bench Verified score in the open-weight class at comparable parameter budgets — Qwen3-Coder-Next at 70.6% (SWE-Agent) currently leads this tier
- You need to run entirely locally on consumer hardware — Qwen3-Coder-Next on a 64GB MacBook or RTX 5090 is a real deployment path, not a theoretical one
- Apache 2.0 licensing is a hard requirement — no patent clauses, no attribution requirements beyond the license terms, maximum commercial flexibility
- You're running high-frequency short-context tasks where 3B active parameters means dramatically lower per-task cost at scale
- Security-aware code generation matters: 61.2% on SecCodeBench beats larger closed models in this category
- You need broader general intelligence alongside coding — Qwen3.5-122B leads on MMLU-Pro, GPQA, and ArenaHard for teams that need one model to serve multiple use cases beyond pure agent orchestration
Don't choose it if your pipeline depends on 1M token native context with validated retention, you need NVIDIA NIM enterprise packaging, or you're running high-output concurrent orchestration workloads on Blackwell hardware where NVFP4 efficiency becomes decisive.
Bottom line: these aren't competing for the same job. Nemotron 3 Super is built to be the brain of a multi-agent system running on enterprise NVIDIA infrastructure. Qwen3-Coder-Next is built to be a cost-effective, locally deployable, Apache-licensed coding agent with strong raw benchmark numbers. The right choice depends almost entirely on your deployment constraints and stack architecture — not just which number is bigger on a leaderboard.
If you're still deciding, the fastest path is running both against your actual workloads. Both offer free-tier API access. Use it.
Related Articles
- Best AI Coding Model in 2026: Sonnet 5, GPT-5, Codex, Gemini 3 Compared
- Multi-Agent Coding Tools: How to Build a Real Agent Stack
- Best AI Coding Assistant in 2026: What Senior Devs Are Actually Using
- How to Run Parallel Claude Code Agents in Your Workflow
- AI Coding Tools Predictions 2026: What's Actually Changing
