
Three weeks ago I was staring at an intermittent 500 in our Verdent multi-agent orchestrator. Six hypotheses. Zero repro. My usual instinct was to throw the entire stack trace at the AI and pray.
Here's what I've learned after months of doing exactly that wrong: the model doesn't need more context. It needs the right contract. Gemini 3.1 Pro launched on February 19, 2026, and its improved SWE and agentic capabilities make it genuinely useful for debugging—but only if you stop treating it like a search engine and start treating it like a junior engineer who needs a proper ticket.
This is the playbook I wish I'd had on day one.
The Debugging Contract: What Gemini Needs to Give You a Good Fix

This confused me for an embarrassingly long time. I kept pasting stack traces and getting refactors I didn't ask for. The fix? Stop giving Gemini an open-ended mandate.
A good debugging prompt has exactly four components:
| Component | What to Include | Why It Matters |
|---|---|---|
| Scope | "Only touch auth/token.go" | Prevents scope creep |
| Context | Relevant stack trace + surrounding 20–30 lines | Gives the model enough signal |
| Constraint | "Do not change method signatures" | Protects callers |
| Output format | "Return a unified diff + one sentence explanation" | Makes review fast |
Miss any of these and you're gambling. I've shipped three sweeping refactors I never asked for because I forgot to define scope. That's expensive in a production codebase.
One more thing: set thinking_level to MEDIUM for most debugging tasks. The new MEDIUM parameter in Gemini 3.1 Pro is genuinely useful here—it gives you structured chain-of-thought reasoning at 60–70% lower cost than HIGH, which you only need for genuinely novel algorithm problems. Debugging is analytical, not creative. MEDIUM is your default.
Stack Trace Triage Prompts That Work
The "3 hypotheses + discriminating test" prompt
This is the one I use almost every time now. Instead of asking "what's wrong?", ask this:
You are debugging a production issue. Here is the stack trace:
[PASTE STACK TRACE]
Here is the relevant surrounding code (20–30 lines):
[PASTE CODE]
Do the following:
1. Generate exactly 3 hypotheses for the root cause, ranked by likelihood.
2. For each hypothesis, propose ONE discriminating test (a log statement, assertion,
or minimal code change) that would confirm or rule it out.
3. Do not propose a fix yet.Why does this work? Because it forces Gemini to reason about the problem space before the solution space. Nine times out of ten, hypothesis #1 is right. But the two alternatives surface blind spots you hadn't considered.
Here's what that looks like in Python against the API:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
stack_trace = """
goroutine 1 [running]:
main.processToken(...)
/app/auth/token.go:47 +0x1a4
...
"""
code_context = """
func processToken(ctx context.Context, raw string) (*Token, error) {
decoded, err := base64.StdDecode(raw) // line 47
...
}
"""
prompt = f"""
You are debugging a production issue. Stack trace:
{stack_trace}
Surrounding code:
{code_context}
Generate exactly 3 hypotheses ranked by likelihood.
For each, propose ONE discriminating test.
Do not propose a fix yet.
"""
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents=prompt,
config={"thinking_config": {"thinking_level": "MEDIUM"}}
)
print(response.text)How to frame ambiguous runtime errors
Runtime errors without a clean stack trace are worse. My template here is the "observable vs. expected" frame:
Observable behavior: [what you actually see—response code, log line, metric spike]
Expected behavior: [what should happen]
Last code change: [commit hash or description]
Environment delta: [any config, dependency, or infra change in the last 48h]
Based only on this information, what are the 2–3 most plausible explanations?
Do not look beyond the scope of [specific file or module].The "last code change" and "environment delta" fields cut diagnosis time in half. Gemini can't read your git log, but it can reason about causation if you hand it the timeline.
Generating a Minimal Reproduction Automatically
Here's where the 1M token context window pays off. Paste the entire failing test file—or even a full module—and ask Gemini to reduce it to the smallest reproducible case:
Given this failing test suite:
[PASTE FULL TEST FILE]
And this error output:
[PASTE TEST RUNNER OUTPUT]
Write a standalone script of ≤ 30 lines that reproduces only the failing behavior.
The script must:
- Import no internal packages
- Run with `python script.py` or `go run script.go`
- Fail with the same errorI've found this halves the time it takes to write a bug report. The model is surprisingly good at stripping out noise—as long as you're explicit about the "≤ 30 lines" constraint. Without that, you get a 200-line reproduction that's only marginally simpler than the original.
Patch Generation with Guardrails
Constraining scope ("fix only what's broken, list what you didn't change")
This is the most important habit I've developed. Every patch request now ends with:
Fix only the specific issue described above.
At the end of your response, include a section titled "Unchanged" that lists
every function and struct you deliberately did not modify.That "Unchanged" section is your contract. If Gemini touches something not on that list, the patch fails review immediately. It also makes code review faster—your reviewer can scan the unchanged list and confirm scope in 30 seconds.
Catching sweeping refactors before they land
Run this check before accepting any patch:
Review the following diff:
[PASTE DIFF]
Answer these questions:
1. Does this diff touch anything outside [target file/function]? List each deviation.
2. Are there any signature changes? List them.
3. Does this fix introduce any new dependencies?
Answer only Yes/No + specifics. Do not suggest improvements.I've caught three unintended interface changes with this pattern in the last two months. The "Answer only Yes/No" constraint is critical—without it you get a helpful but verbose code review that buries the actual red flags.
Regression Test Generation and Verification
Once you have a patch, generate the regression test in the same prompt session (preserving thought signatures for multi-turn context—this matters for Gemini 3.1 Pro's multi-turn agentic behavior):
Given this patch:
[PASTE DIFF]
Write regression tests that:
1. Reproduce the original failure (should fail without the patch)
2. Pass with the patch applied
3. Cover at least one edge case adjacent to the bug
Use [pytest / go test / jest] conventions. No mocks unless absolutely necessary.The "should fail without the patch" constraint is non-negotiable. If Gemini writes a test that passes both before and after the fix, it's not a regression test—it's noise. I've started verifying this by asking:
For each test you just wrote, explain in one sentence why it would FAIL on
the unpatched code. If you cannot explain this, the test is invalid.That second prompt catches about 20% of generated tests that are technically correct but diagnostically useless.
A Real Incident Walk-Through (Anonymized)
Here's how this played out on a real Verdent incident—sanitized but structurally accurate.
The bug: Intermittent context deadline exceeded errors under load in our agent task dispatcher. Reproducible roughly 1-in-50 requests at >20 concurrent agents.
Step 1 — Hypothesis prompt. I pasted the goroutine dump and 40 lines of the dispatcher. Gemini returned three hypotheses: (1) mutex contention on the task queue, (2) a missing context propagation to a downstream call, (3) a ticker leak in the timeout handler. Likelihood order: 2 > 1 > 3.
Step 2 — Discriminating test. For hypothesis 2, it suggested adding a context.WithTimeout log on entry and a matching log on the downstream call. Within one test run, the log gap confirmed the context wasn't being forwarded.
Step 3 — Minimal patch. One line change: passing ctx instead of context.Background() to the downstream client constructor. Scope: one function, no signature changes, unchanged list confirmed.
Step 4 — Regression test. Generated a test that simulates a pre-cancelled context and asserts the function returns context.Canceled within 100ms. Verified it failed on the original code.
Total time from goroutine dump to merged fix: 47 minutes. My previous average for this class of bug was closer to 3 hours.
When Gemini Debugging Fails—and What to Do Instead
I want to be straight with you here: this workflow isn't magic. There are failure modes.
When it breaks down:
| Situation | Why It Fails | What to Do Instead |
|---|---|---|
| Bug requires business context (e.g., "this user's subscription tier") | Model has no domain knowledge | Annotate the code with inline comments explaining invariants |
| Flaky test that's infrastructure-dependent | Model can't see your CI environment | Provide explicit env diff; use thinking_level: HIGH |
| Cross-service bugs spanning 3+ repos | Context gets too diffuse | Isolate the call boundary first; debug one side at a time |
| Undocumented legacy behavior | Model hallucinates intent | Ask for hypotheses only; never ask it to infer "what was intended" |
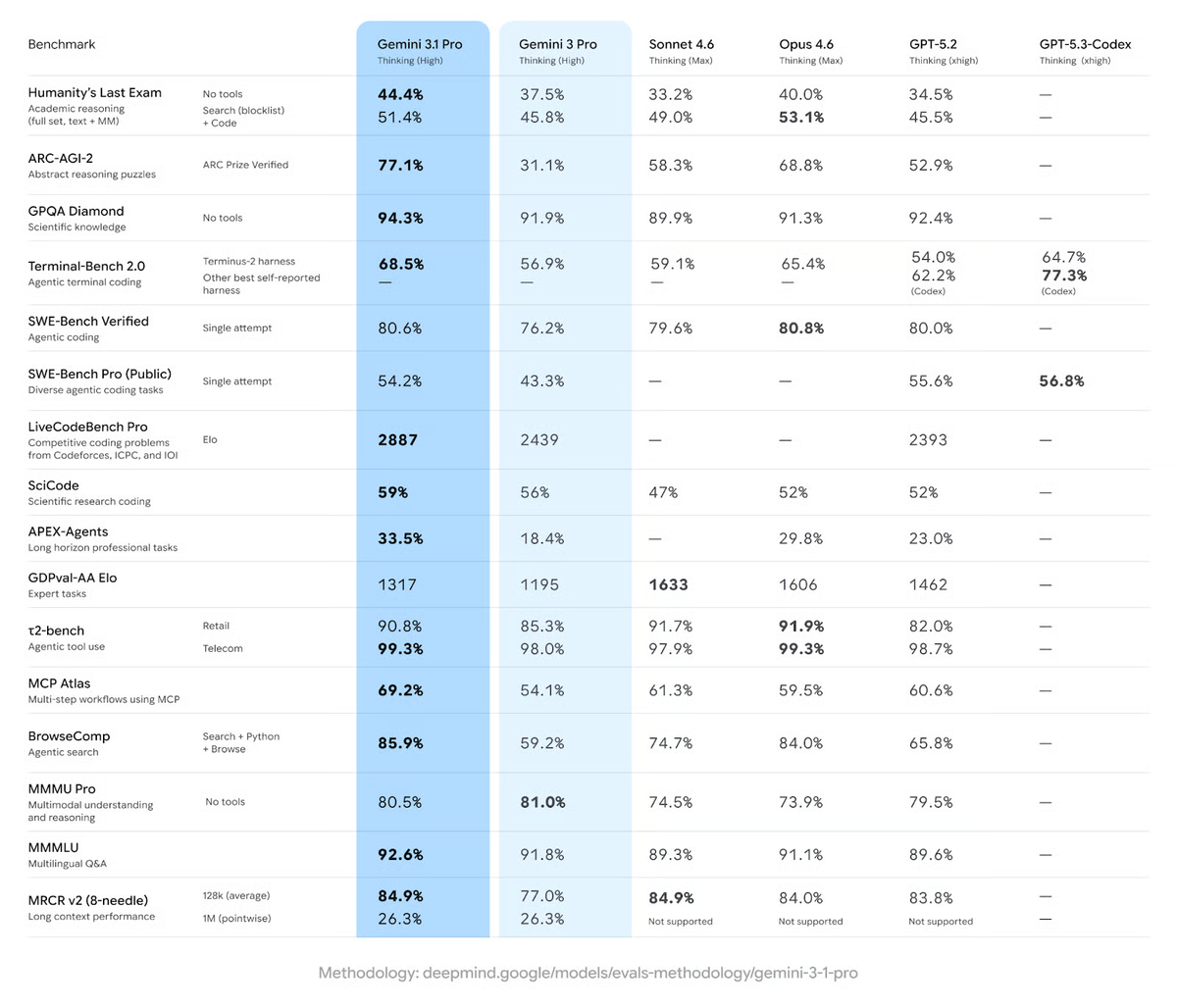
On SWE-Bench Verified, Gemini 3.1 Pro scores 80.6%—essentially a four-way tie at the frontier with Claude Opus 4.6 (80.8%), GPT-5.2 (80.0%), and Sonnet 4.6 (79.6%). The practical takeaway isn't that one model wins. It's that the quality gap has collapsed. Your prompting discipline matters more than model choice at this tier.
Maybe I'm slightly biased toward the patterns above because they've worked in my environment. Your mileage will vary. The one thing I'm confident about: constraints always outperform open-ended prompts for debugging. Every time.
Tested On / Last Updated
| Item | Detail |
|---|---|
| Model | gemini-3.1-pro-preview (launched February 19, 2026) |
| API access | Google AI Studio, Vertex AI, Gemini CLI |
| Thinking level used | MEDIUM for triage; HIGH for complex multi-file bugs |
| Pricing | $2/M input tokens, $12/M output (≤200K tokens) —official Gemini API pricing |
| Context window | 1M tokens — full codebase ingestion viable |
| Last verified | February 25, 2026 |
related post:
https://www.verdent.ai/de/guides/best-ai-coding-assistant-2026
https://www.verdent.ai/de/guides/best-ai-for-code-review-2026
https://www.verdent.ai/de/guides/claude-sonnet-5-release-tracker
https://www.verdent.ai/de/guides/claude-sonnet-5-swe-bench-verified-results
https://www.verdent.ai/de/guides/codex-app-worktrees-explained
https://www.verdent.ai/de/guides/gpt-5-3-codex-vs-claude-opus-4-6-guide
https://www.verdent.ai/guides/minimax-2-5-coding-which-model
https://www.verdent.ai/guides/what-is-minimax-m2-coding
https://www.verdent.ai/guides/best-ai-coding-model-2026-sonnet5-gpt5-codex-gemini3
https://www.verdent.ai/guides/claude-sonnet-5-pricing-reality-check
