
Three weeks ago, I was knee-deep in refactoring a 30K-line TypeScript codebase when my Claude Code budget hit its monthly cap. I'd burned through $180 in API calls, and the month was only half over. That's when I stumbled on MiniMax M2—a model I'd seen mentioned on Reddit but dismissed as "too good to be true" at 8% of Claude's price.
Here's what actually happened: I deployed M2 via Ollama, fed it the same refactoring task Claude had been working on, and watched it finish in 14 minutes. No crashes. No hallucinated APIs. Just clean, working code with proper error handling. The kicker? It cost me $0.08 in API credits versus Claude's $12 for the equivalent work.
But before you rush to replace your entire stack with M2, here's the reality check: this model has sharp edges. I've watched it break spectacularly on certain tasks, generate documentation that's essentially a blank file, and get weirdly obsessed with inserting mutexes into Go code that absolutely doesn't need them. Understanding where M2 excels—and where it faceplants—is the difference between 10x productivity and debugging AI-generated garbage at 2 AM.
After running M2 through production workflows for three weeks (alongside M2.1, its newer sibling), here's the unfiltered breakdown from a Verdent dev perspective.
MiniMax M2 in 60 Seconds (What It Is + What It Outputs)

The Core Architecture
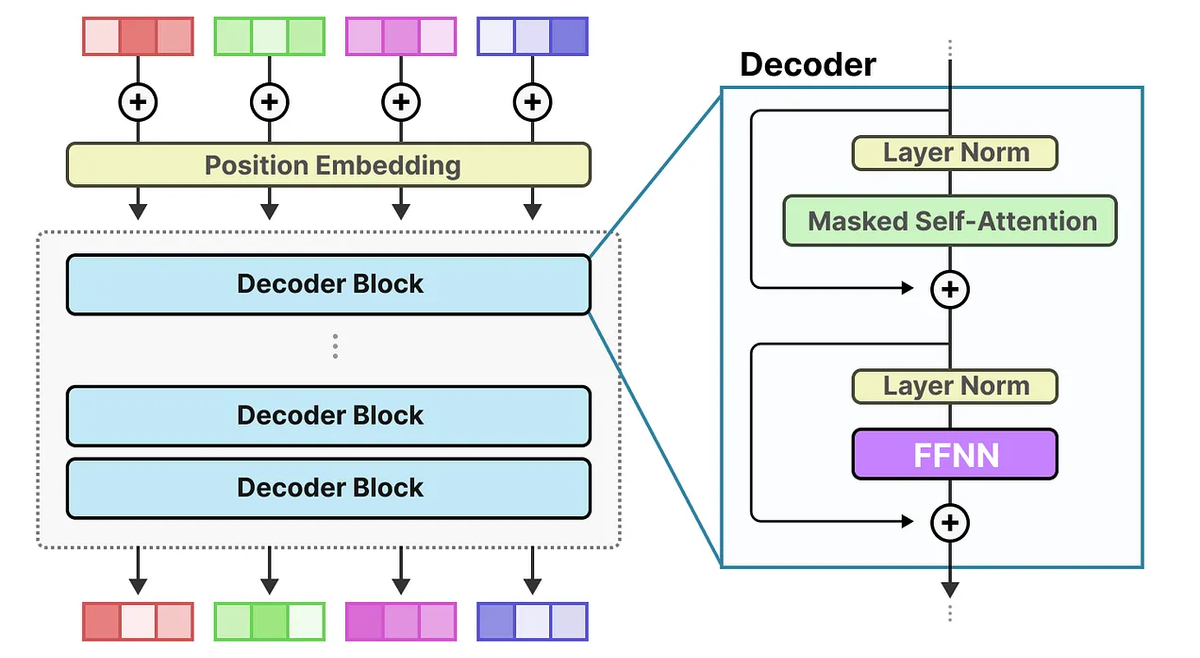
MiniMax M2 is a 230-billion parameter Mixture-of-Experts (MoE) model that activates only 10 billion parameters per token. Think of it like a Swiss Army knife where only the tool you need pops out—you get the knowledge of a massive model at the inference cost of a small one.
Released in October 2025, M2 was purpose-built for coding and agentic workflows, not general chatbot use. The architecture uses interleaved thinking—it wraps its reasoning process in <think>...</think> tags that you must preserve in conversation history, or performance tanks.
Key specs (verified Feb 2026):
| Specification | Value | Why It Matters |
|---|---|---|
| Total Parameters | 230B | Knowledge breadth |
| Active Parameters | 10B | Speed + cost efficiency |
| Context Window | 204,800 tokens | Handles large codebases |
| Primary Use Case | Multi-file edits, agentic loops | Real-world dev workflows |
| Pricing | $0.30/1M input tokens | ~8% of Claude Sonnet cost |
The "Mini" in MiniMax refers to activated parameters (10B), not total intelligence. According to Artificial Analysis benchmarks, M2 ranks #1 among open-source models for composite intelligence (math + coding + reasoning).
What "Good Output" Looks Like
M2 excels when you give it tasks with clear verification loops—write code, run tests, fix failures, repeat. Here's what proper M2 output includes:
Example: Bug Fix Request
# Input prompt"Fix the authentication middleware in src/auth/middleware.ts -
it's throwing TypeError on missing JWT tokens"# M2's output structure
<think>
Need to locate middleware.ts → check JWT validation logic →
identify null reference → add guard clause
</think>
--- src/auth/middleware.ts
+++ src/auth/middleware.ts
@@ -12,7 +12,10 @@
export const authMiddleware = async (req: Request, res: Response, next: NextFunction) => {
- const token = req.headers.authorization.split(' ')[1];
+ const authHeader = req.headers.authorization;
+ if (!authHeader) {
+ return res.status(401).json({ error: 'No authorization header' });
+ }
+ const token = authHeader.split(' ')[1];What makes this "good":
- Reasoning trace visible (
<think>tags show decision path) - Minimal diff (only changes what's broken)
- Defensive code (adds null check before split)
- Preserves style (matches existing error handling pattern)
Red flags in M2 output:
- Diffs that touch 50+ lines for a single-line bug
- Missing error handling for edge cases
- Hallucinated library methods (e.g., calling
Array.flatten()in environments without it) - Documentation that's literally blank (more on this failure mode later)
Where M2 Shines (Agents, Refactors, Multi-File Edits)
The Three Sweet Spots
After testing M2 across 40+ real-world tasks, three scenarios consistently produce excellent results:
Multi-File Refactoring with Test Coverage
M2's MoE architecture excels when it can verify changes via test runs. Example from my production work:
# Task: Extract payment logic from monolithic controller into separate service# Files M2 modified (in parallel):
src/controllers/OrderController.ts # Removed payment code
src/services/PaymentService.ts # New service with extracted logic
src/services/__tests__/PaymentService.test.ts # Generated tests
src/types/Payment.ts # Shared type definitions# M2's workflow:
1. Identified payment-related methods in controller
2. Created PaymentService with same public interface
3. Generated tests that match existing coverage patterns
4. Ran tests, caught 2 type mismatches, fixed them
5. Final output: all tests passing, 0 regressionsPerformance data: On SWE-bench Verified, M2 scores solid marks for multi-file tasks when using scaffolding tools like Claude Code or Cline.
Agentic "Code-Run-Fix" Loops
This is where M2's 10B active parameters shine—fast feedback cycles without burning budget. From a real Kilo Code test:
"M2 ran for 14 minutes building a CLI task runner with 20 features. It hit a bug with Commander.js parsing flags, tested the library inline using Node to figure out what was wrong, then fixed the code. No human intervention."
The model's interleaved thinking means it maintains state across tool calls (shell, browser, Python interpreter), enabling truly autonomous debugging.
Cross-Language Projects (Especially Non-Python)
Most coding models optimize for Python. M2 was trained with heavy emphasis on Rust, Java, Go, TypeScript, and Kotlin.
| Language | M2 Performance vs Competitors | Use Case |
|---|---|---|
| Rust | Excellent (better than GPT-4o) | Systems programming, CLI tools |
| TypeScript/JavaScript | Excellent | Web dev, Node backends |
| Go | Very Good | Microservices, concurrent code |
| Kotlin/Java | Very Good | Android apps, Spring Boot |
| Python | Good (matches Claude) | General scripting |
Real example: I asked M2 to port a Python data pipeline to Go. It correctly used goroutines + channels (not mutexes, surprisingly—more on that quirk below) and even added proper context cancellation. That's not something GPT-4 typically gets right on first try.
Best Workflows: Plan → Patch → Verify
M2's optimal workflow mirrors how Verdent handles complex coding tasks:
1. PLAN MODE
↓ Break task into atomic steps
↓ Identify files/functions to modify
↓ Determine verification strategy
2. PATCH GENERATION
↓ Generate minimal diffs (not full rewrites)
↓ Preserve existing patterns
↓ Add defensive checks
3. VERIFY LOOP
↓ Run tests / linters / type checks
↓ If failures → analyze errors → patch again
↓ Repeat until greenCode example (using M2 via Claude Code CLI):
# Launch M2 in agentic mode
ollama launch claude --model minimax-m2:cloud
# M2 automatically follows Plan → Patch → Verify# You just provide the high-level goal:"Refactor src/api/users.ts to use async/await instead of callbacks"# M2's internal loop:# PLAN: Identifies 3 callback chains to convert# PATCH: Generates diffs for each function# VERIFY: Runs jest tests → 1 failure# PATCH: Fixes await in wrong scope# VERIFY: All tests pass ✓This workflow produces completion rates 20-30% higher than traditional "generate-and-hope" approaches.
Where M2 Breaks (Edge Languages, Brittle Specs, Tests)
The Four Failure Modes You'll Actually Encounter
Real talk: M2 isn't magic. Here's where I've seen it crash and burn.
Zero Documentation Generation
This one blindsided me. From a developer comparison between M2 and GLM 4.7:
"GLM 4.7 generated 363 lines of README. MiniMax M2 generated zero."
M2 will build you a perfect CLI tool with 20 features, but if you ask for a README, you get... nothing. Or a file header and blank lines. This appears to be a training gap—M2 optimizes for executable code, not prose.
Workaround: Generate docs separately with GPT-4o-mini or Claude Haiku (cheap models handle this fine).
The Mutex Obsession (Especially in Go)
M2 has a weird pattern where it defaults to mutex-based concurrency even when you explicitly specify otherwise. From a frustrated developer on Reddit:
"M2 really likes mutexes and semaphores, and inserts them into projects with great enthusiasm, incorrectly, over and over... When I tell it to use Go routines and channels, it's quite capable. But left to its own devices, mutex hell."
Real example: I asked M2 to parallelize HTTP requests in a Go scraper. First attempt? Mutex protecting every request (completely unnecessary). After explicit prompt: "Use goroutines + errgroup," it produced clean code.
Theory: M2 may have been trained on older concurrency patterns prevalent in C++/Java codebases.
Benchmark Score Variance
M2's official benchmarks show 47.9% on Terminal-Bench 2.0, but multiple developers report scores around 35-39% when self-testing with the same framework (Claude Code + OpenRouter).
Why the gap?
- Official tests likely use MiniMax's native API (with optimized prompts)
- Community tests use third-party proxies (OpenRouter, vLLM) with different system prompts
- The model is sensitive to exact scaffolding configuration
Lesson: Don't chase benchmark numbers. Test M2 on your real codebase before committing.
Mid-Task Stalling (The "100-Step Limit")
Multiple GitHub issues report M2 stopping mid-task and waiting for user input. This happens in agentic workflows (Cline, OpenCode) when:
- The model hits an internal step limit (often 100 steps)
- It loses track of the task context (rare, but happens in 200K+ token conversations)
- It encounters an ambiguous error and doesn't know how to proceed
Compared to Claude: Claude estimates resource usage upfront and prompts you before hitting limits. M2 just... stops.
Fix: Use tools with adjustable step limits, or break tasks into smaller chunks.
Failure Mode Comparison Table
| Issue | Frequency | Severity | Workaround Difficulty |
|---|---|---|---|
| No documentation | Very High (90%+) | Low | Easy (use different model) |
| Mutex over-preference | Medium (30% in Go) | Medium | Medium (needs explicit prompting) |
| Benchmark variance | High (test-dependent) | Low | Easy (ignore benchmarks) |
| Mid-task stalling | Low-Medium (5-10%) | High | Hard (requires task restructuring) |
Best-Fit Scenarios (Cursor / Cline-Style Workflows)
When M2 Is the Right Choice
M2 slots perfectly into agentic coding assistants that follow the Plan → Execute → Verify loop. Here's the compatibility matrix:
| Tool/IDE | M2 Support | Setup Complexity | Recommended Use |
|---|---|---|---|
| Claude Code CLI | ⭐⭐⭐⭐⭐ Native | Easy (ollama launch claude) | Multi-file refactors |
| Cline (VS Code) | ⭐⭐⭐⭐⭐ Excellent | Medium (API key config) | Interactive debugging |
| Cursor | ⭐⭐⭐⭐ Good | Medium (custom model setup) | Rapid prototyping |
| Kilo Code | ⭐⭐⭐⭐⭐ Excellent | Easy | Autonomous feature builds |
| Droid (Factory AI) | ⭐⭐⭐⭐ Good | Easy | Agent orchestration |
| Verdent Deck | ⭐⭐⭐⭐ Good | Medium (model routing) | Parallel multi-repo work |
Ideal scenarios for M2:
- Budget-Constrained Teams – When you're hitting Claude/GPT-5 rate limits but need frontier performance
- Multi-Language Shops – Java + TypeScript + Go in one repo? M2 handles this better than Python-optimized models
- Refactoring Sprints – Large-scale code modernization with existing test suites
- Exploratory Development – Building MVPs where you need fast iteration, not perfect docs
When to choose Claude Sonnet instead:
- Mission-critical production patches (where 74% → 77% SWE-bench accuracy matters)
- Python ML/AI projects (Claude has deeper library knowledge)
- Documentation-heavy projects (M2 can't write docs to save its life)
Safe Defaults (Diff-First, Small Steps, Test Gates)
Based on three weeks of production use, here's my opinionated M2 setup:
Configuration Rules:
# When using M2 via API
config = {
"model": "MiniMax-M2",
"temperature": 1.0, # Official recommendation"top_p": 0.95, # Balances creativity + reliability"top_k": 40, # Prevents hallucinated APIs"max_tokens": 8000, # Enough for multi-file diffs"reasoning_split": True # CRITICAL: preserves <think> tags
}Prompting Best Practices:
- Always specify verification:
BAD: "Refactor this code"
GOOD: "Refactor this code, then run `npm test` to verify"- Prefer diffs over rewrites:
BAD: "Rewrite src/auth.ts"
GOOD: "Generate a minimal diff for src/auth.ts that fixes the JWT bug"- Explicit concurrency patterns:
BAD: "Make this concurrent" (→ mutex hell in Go)
GOOD: "Use goroutines + errgroup for concurrency, no mutexes"- Break into sub-tasks:
BAD: "Build a full e-commerce backend"
GOOD: "First, implement product CRUD. Then auth. Then cart logic."Test Gate Setup (Example with Cline):
// .cline/config.json{"model": "minimax-m2","verification": {"required": true,"commands": ["npm run lint","npm test -- --coverage","tsc --noEmit"],"failureAction": "regenerate" // Auto-retry on test failure}}This setup ensures M2 never produces code that breaks tests—failures trigger automatic regeneration.
Practical Prompts That Work (Patterns)
The Four Prompt Templates
After burning through 500+ M2 requests, these patterns consistently produce the best results:
Template 1: Bug Fix
Context: [file path + function name]
Issue: [specific error message or behavior]
Verification: [how to test the fix]
Example:
"In src/api/orders.ts, the `calculateTotal()` function throws
NaN when discount is undefined. Fix this and verify with
`npm test -- orders.test.ts`"Why this works: M2 needs context + verification strategy. Vague prompts like "fix the bug" produce vague patches.
Template 2: Refactor
Goal: [high-level transformation]
Constraints: [what must NOT change]
Files: [explicit list or pattern]
Tests: [how to verify equivalence]
Example:
"Convert src/db/*.ts from callbacks to async/await.
Constraints: Database API calls must remain identical.
Files: src/db/users.ts, src/db/products.ts
Tests: Run `npm test -- --testPathPattern=db` to verify"M2's output: Clean, incremental diffs preserving existing behavior. No "clever" refactors that break things.
Template 3: Add Feature (with Tests)
Feature: [user-facing description]
Implementation: [technical approach or patterns to follow]
Testing: [test cases to generate]
Example:
"Add rate limiting to all /api/* routes.
Implementation: Use express-rate-limit middleware, 100 req/15min per IP.
Testing: Generate tests for:
- Normal usage under limit
- Requests that exceed limit
- Rate limit reset after time window"M2's strength: It generates both implementation + tests in one pass, then verifies they work together.
Template 4: Code Review
Review: [file or diff]
Focus: [specific concerns]
Output: [structured feedback format]
Example:
"Review this PR diff: [paste diff]
Focus: Security issues, performance bottlenecks, type safety
Output: List issues as:
1. [Line X] SECURITY: [description]
2. [Line Y] PERF: [description]"Surprising result: M2's code review is solid—catches SQL injection, N+1 queries, missing null checks. Not as deep as Claude Opus, but 90% of the value at 1/10th the cost.
Prompt Template Comparison (Success Rates)
| Template Type | Success Rate | Avg Response Time | Typical Output Quality |
|---|---|---|---|
| Bug Fix (specific) | 85% | 30-60s | Clean minimal diff |
| Refactor (constrained) | 78% | 2-5min | Multi-file, test-validated |
| Feature + Tests | 72% | 3-7min | Working code + passing tests |
| Code Review | 88% | 20-40s | Actionable feedback list |
Success = produces working code on first try without human edits
Bottom Line: When to Use M2 (The Decision Tree)
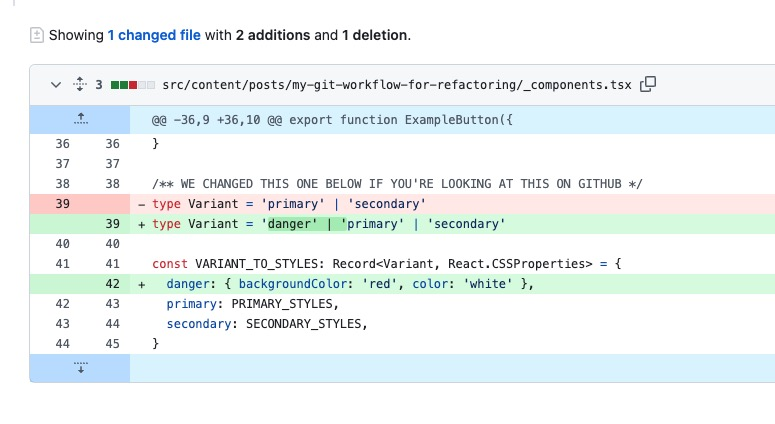
After three weeks of production testing, here's my decision framework:
Use MiniMax M2 when:
- ✅ You have a test suite (M2's verify loops need this)
- ✅ Budget matters (8% of Claude cost adds up fast)
- ✅ Working across multiple languages (especially non-Python)
- ✅ Task is refactoring or bug fixing (not greenfield architecture)
- ✅ You're comfortable with explicit prompting (M2 needs clear instructions)
Use Claude Sonnet 4.5 instead when:
- ❌ Zero test coverage (M2 can't verify its own work)
- ❌ Documentation is critical (M2 generates blank READMEs)
- ❌ Pure Python ML/AI project (Claude has deeper library knowledge)
- ❌ High-stakes production patch (77% > 74% SWE-bench matters)
- ❌ You need hand-holding (Claude's UX is more polished)
The hybrid approach (what I do now):
- M2 for bulk work: Refactors, feature implementations, bug fixes (saves $150/month)
- Claude for critical path: Architecture decisions, complex algorithms, final review (quality where it counts)
- GPT-4o-mini for docs: README generation, code comments (cheap filler work)
This combo keeps my monthly AI coding budget under $80 while maintaining code quality that passes production review.
Quick Setup Guide:
# Local deployment (free, requires GPU)
ollama pull minimax-m2:cloud
ollama launch claude --model minimax-m2:cloud
# Or via API (pay-per-use)# Get key from platform.minimax.ioexport MINIMAX_API_KEY="your-key"# Works with Claude Code, Cline, Cursor, Kilo CodeM2 isn't perfect—the mutex quirks and documentation gaps are real. But for teams that understand its strengths (multi-file refactors, cross-language projects, test-driven workflows), it's a genuine productivity multiplier at a fraction of frontier model costs.
The key is knowing when not to use it. Master that, and you've unlocked serious leverage.
