
Meta spent nine months and roughly $14 billion rebuilding its AI stack from scratch. On April 8, 2026, the result shipped: Muse Spark. If you're evaluating frontier models for agent workflows and want to know where it actually sits — including the parts Meta acknowledges aren't ready yet — here's what the first day of independent benchmarks shows.
What Is Muse Spark?
Muse Spark is Meta's first proprietary frontier reasoning model, announced in Meta's official blog post. Its internal codename was "Avocado." It's natively multimodal — text, image, and speech input — with tool-use, visual chain-of-thought reasoning, and multi-agent orchestration built in. Meta describes it as "small and fast by design, yet capable enough to reason through complex questions in science, math, and health."
It now powers the Meta AI assistant across the Meta AI app and meta.ai, with a rollout to WhatsApp, Facebook, Instagram, Messenger, and Meta's Ray-Ban AI glasses coming in the following weeks.
The headline number: Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing it fourth among models benchmarked — behind Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview, but ahead of Claude Sonnet 4.6. For comparison, Llama 4 Maverick scored 18 on the same index at launch. That's a substantial jump in a single release cycle.
The model has three reasoning modes:
- Instant: Fast, conversational — the default for most interactions
- Thinking: Extended step-by-step reasoning for complex problems
- Contemplating: Multiple agents reasoning in parallel, designed to compete with Gemini Deep Think and GPT-5.4 Pro on demanding scientific tasks
Contemplating mode is already available at launch. It uses a "thought compression" technique developed during reinforcement learning — the model is penalized for excessive reasoning token use, forcing efficient multi-step problem solving.
What Muse Spark Can and Can't Do
Muse Spark's strengths are clearly documented:
Vision and multimodal reasoning — The model was built with strong visual perception from the ground up. Snap a photo and ask about nutritional content, compare products, or identify items. Meta collaborated with over 1,000 physicians to curate health-related training data, making health reasoning a genuine differentiator.
Scientific and frontier reasoning — In Contemplating mode, Muse Spark scores 50.2% on Humanity's Last Exam (No Tools) and 38.3% on FrontierScience Research, both ahead of GPT-5.4 Pro and Gemini Deep Think on those specific benchmarks. Physics remains an exception — Muse Spark scores 82.6 on IPhO 2025 Theory, behind GPT-5.4 Pro (93.5) and Gemini 3.1 Deep Think (87.7).
Token efficiency — Muse Spark used 58M output tokens to complete the full Artificial Analysis Intelligence Index evaluation, comparable to Gemini 3.1 Pro Preview (57M) and well below Claude Opus 4.6 (157M) and GPT-5.4 (120M). This matters for cost and inference speed at scale.
Where it doesn't lead:
Coding and agentic workflows — Meta's technical blog states directly: "We continue to invest in areas with current performance gaps, specifically long-horizon agentic systems and coding workflows." Fortune confirmed this wording in its launch coverage. The benchmark numbers back the admission up. Terminal-Bench 2.0 (agentic terminal coding): Muse Spark 59.0 vs GPT-5.4 75.1 and Gemini 3.1 Pro 68.5. GDPval-AA Elo (real-world office and work tasks): Muse Spark 1,427 vs Claude Sonnet 4.6 at 1,648 and GPT-5.4 at 1,676. On Terminal-Bench Hard, Muse Spark trails Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro. These numbers are from Artificial Analysis (third-party), not Meta's own benchmarks.
Abstract reasoning — ARC-AGI-2 score: Muse Spark 42.5 in Thinking mode, against GPT-5.4 at 76.1 and Gemini 3.1 Pro at 76.5. This benchmark tests novel pattern recognition — the ability to generalize from minimal examples to unseen problem types.
How It Compares to Frontier Models
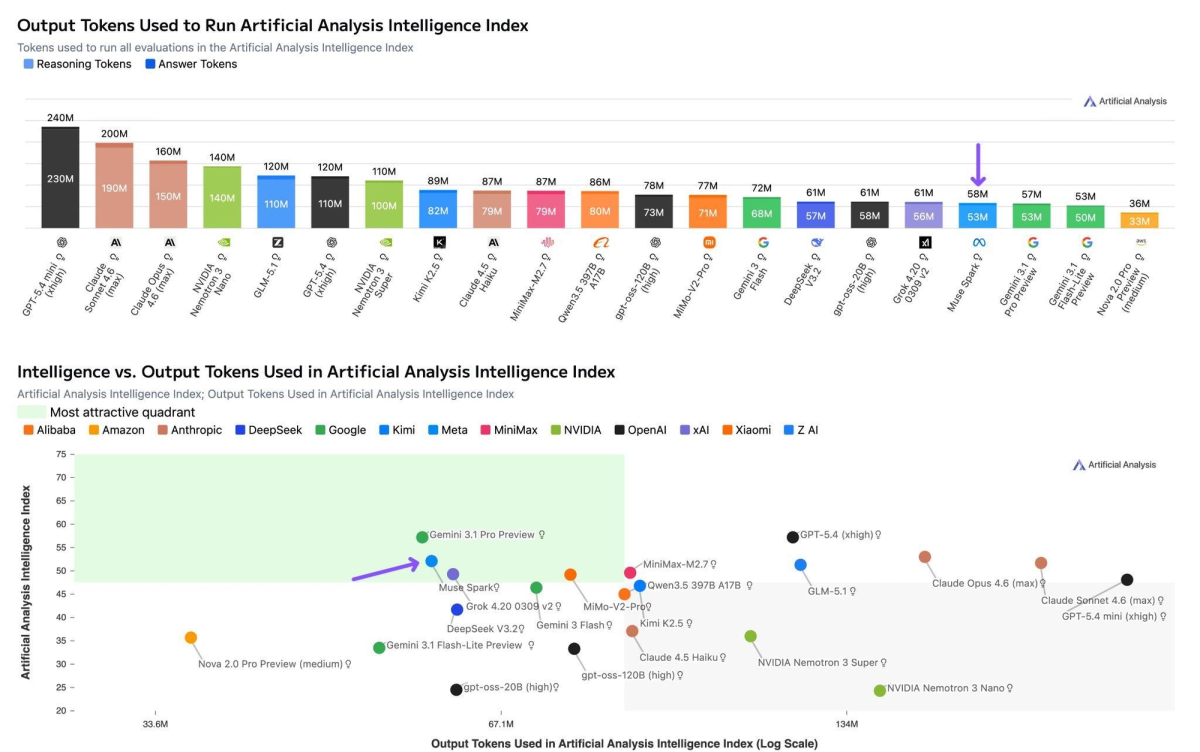
| Benchmark | Muse Spark | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| AA Intelligence Index | 52 | 57 | 53 | 57 |
| Terminal-Bench 2.0 | 59 | 75.1 | — | 68.5 |
| GDPval-AA Elo | 1,427 | 1,676 | 1,606 | 1,320 |
| ARC-AGI-2 (Thinking) | 42.5 | 76.1 | — | 76.5 |
| HLE No Tools (Contemplating) | 50.20% | 43.90% | — | 48.40% |
| MMMU-Pro (vision) | 80.50% | — | — | 82.40% |
| Token efficiency (AA eval) | 58M | 120M | 157M | 57M |
Sources: Artificial Analysis Intelligence Index v4.0; Meta AI technical blog. AA Intelligence Index ranking: 1. Gemini 3.1 Pro Preview (57), 2. GPT-5.4 (57), 3. Claude Opus 4.6 (53), 4. Muse Spark (52). Terminal-Bench 2.0 and ARC-AGI-2 competitor scores from Artificial Analysis and officechai.com launch coverage. Some cells marked — where scores were not published at time of writing.
The pattern is consistent: Muse Spark is genuinely competitive on reasoning, scientific tasks, and multimodal understanding. The gap widens on tasks requiring sustained agentic execution, precise code generation, and abstract pattern recognition.
Access and Availability
Consumer access: Available now at meta.ai and in the Meta AI app. Free to use, requires a Meta account (Facebook or Instagram login).
API access: No public API at launch. Meta has a "private API preview" open to unspecified select partners, with plans for paid API access to a wider audience at a later date. No pricing has been announced. If you're evaluating this for integration, you're waiting.
Rollout: Muse Spark will appear inside Facebook, Instagram, WhatsApp, and Messenger in the coming weeks. Ray-Ban Meta AI glasses support is also planned.
Privacy note: Using Muse Spark requires logging in with a Meta account. Meta has not explicitly stated whether Facebook or Instagram account data will be used to personalize Muse Spark responses, though this is likely given Meta's general data practices. Developers building on API access should review Meta's terms when they become available.
Why Muse Spark Is Proprietary, Not Open-Weight
This is the significant departure. Every previous Meta frontier model — the entire Llama family — shipped with open weights. Muse Spark doesn't.
The launch marks a controversial departure from Meta AI's open-source roots, as VentureBeat noted. Wang acknowledged the shift on X, noting that "plans to open-source future versions" remain. TechCrunch reported that Meta is also experimenting with API access as a new revenue stream. Meta has said they "hope" to open-source future versions — "hope" being the operative word.
The competitive logic is straightforward. Llama 4 Maverick had significant benchmark weaknesses and was openly criticized. Muse Spark is positioned as Meta's return to frontier competition. Releasing weights while a generation behind doesn't cost you much. Releasing weights when you're actually competitive is a different calculation.
For the developer community that built significant tooling and infrastructure on Llama, the shift lands differently. The r/LocalLLaMA community and others who rely on open weights for self-hosting and fine-tuning have no equivalent path with Muse Spark.
What This Means for Developers Evaluating AI Coding Tools
The honest answer: Muse Spark isn't the right model to evaluate for production coding workflows right now, and Meta says so directly in its own release documentation.
The coding and agentic gaps are real. Terminal-Bench 2.0 at 59.0 against competitors in the 68–75 range is a meaningful difference for tasks like autonomous code generation, multi-file refactoring, test-running loops, and long-horizon task execution. These are the capabilities that matter most for coding agent infrastructure — the kind of work where Claude Code, Verdent's multi-agent worktree architecture, and similar tools are purpose-built to operate.
Muse Spark is worth tracking because the trajectory matters. Meta went from Llama 4 Maverick at 18 on the Artificial Analysis Intelligence Index to Muse Spark at 52 in a single release cycle. That's not a slow iteration; it's a rebuild. If the coding and agentic gap narrows at the same rate in the next Muse generation — which Wang says is already in development — it changes the model selection conversation significantly.
For now, if you're evaluating models for coding workflows: look at the Terminal-Bench 2.0 and GDPval-AA numbers. Muse Spark's strong points are multimodal reasoning, health tasks, and scientific problems. It's not the model to route code generation and long-horizon agent tasks through in April 2026.
FAQ

Is Muse Spark free to use?
Yes, through meta.ai and the Meta AI app. A Meta account (Facebook or Instagram) is required for login.
Can I access Muse Spark via API?
Not publicly yet. Meta has a private API preview for select partners and has announced future paid API access. No timeline or pricing has been given. Check meta.ai for updates.
How does Muse Spark compare to Llama 4?
Llama 4 Maverick scored 18 on the Artificial Analysis Intelligence Index at launch. Muse Spark scores 52 — a significant leap. Muse Spark is also proprietary where Llama was open-weight, and is a reasoning model where Llama 4 Maverick was evaluated as a non-reasoning model.
What is Contemplating mode?
Contemplating mode runs multiple agents in parallel to tackle complex reasoning tasks. It's Meta's answer to Gemini Deep Think and GPT-5.4 Pro. On Humanity's Last Exam, Contemplating mode scores 50.2%, ahead of GPT-5.4 Pro (43.9%) and Gemini 3.1 Deep Think (48.4%) on that benchmark.
Is Muse Spark good for coding?
Not compared to the current leaders. Terminal-Bench 2.0: Muse Spark 59.0 vs GPT-5.4 75.1 and Gemini 3.1 Pro 68.5. Meta has explicitly flagged coding workflows and long-horizon agentic systems as areas of continued investment. For production coding workloads, current alternatives remain stronger.
Will Meta open-source Muse Spark?
Meta has said they "hope" to open-source future versions of the Muse series, not Muse Spark itself. There is no confirmed timeline.
Related Reading
- Claude Code vs Verdent: Multi-Agent Architecture Compared — For the coding and agentic use cases where Muse Spark has acknowledged gaps, this is the tool comparison that matters.
- LLM Knowledge Base for Coding Agents: Beyond RAG — How to give whichever model you choose persistent project context for coding workflows.
- GLM-5V-Turbo: Z.ai's Vision Coding Agent Explained — Another recent multimodal model release, oriented toward vision-to-code workflows.
- AutoResearch vs AI Coding Agents: Where Autonomous Research Ends — Frameworks for thinking about what "agentic" actually requires — relevant as Muse Spark's Contemplating mode uses parallel agents.
- What Is G0DM0D3? — If you want to run Muse Spark against other frontier models side-by-side once API access opens.
