
Both models are Z.ai's commercial agent-optimized variants. Both run through the same API at the same price. The difference is the input modality and the speed implications that follow. If your workflow is entirely text-in, text-out, pick GLM-5-Turbo. If it involves visual input — design mockups, screenshots, UI recordings — pick GLM-5V-Turbo. Everything else is elaboration on that decision.
Quick Summary: Two Turbo Models, Different Jobs
GLM-5-Turbo and GLM-5V-Turbo are not competing alternatives to the same problem. They sit at different layers of the agent stack:
GLM-5-Turbo (March 15, 2026) is a text-only execution engine optimized for speed and long-chain agent stability. Z.ai tuned it specifically for OpenClaw-style task patterns: tool calling, instruction decomposition, persistent execution, and high-throughput multi-step workflows. The word "Turbo" here means high throughput — the model runs at over 200 tokens per second, as noted by VentureBeat in its GLM-5 family coverage.
GLM-5V-Turbo (April 1, 2026) adds native vision. It processes images, video clips, and text together using a dedicated CogViT visual encoder — not a vision bolt-on. The target use case is visual coding workflows: design-to-code generation, GUI agent tasks, screenshot-to-action pipelines. The tradeoff is speed: it ranks in the 34th percentile for output speed across benchmarked models (source: benchable.ai, third-party).
The naming implies GLM-5V-Turbo is a superset. It's not. It's a specialized model for a different workload.
Architecture Differences
Both models are closed-source. Z.ai has not publicly disclosed parameter counts for either (confirmed by Artificial Analysis). The meaningful architectural difference is the vision pipeline.
GLM-5-Turbo processes text only. It's a pure language model with reasoning capabilities inherited from the GLM-5 base. Its training was specifically adapted from the GLM-5 base around OpenClaw task patterns, which is why it shows better tool-calling reliability and long-chain stability than the base model — not because it's larger, but because the fine-tuning target was execution fidelity rather than general reasoning breadth.
GLM-5V-Turbo adds the CogViT encoder, which processes visual inputs as native data rather than text descriptions. In most vision-language model architectures, a vision encoder generates a text description of the image, which is then fed to the language model as a text prompt. CogViT feeds visual features directly into the transformer backbone. The practical consequence: the model can interpret spatial layout, component hierarchy, color palette, and visual context without losing information through a text intermediary.
The vision pipeline adds latency. Processing and fusing visual and text token streams requires more compute per call than text-only inference — which is the main reason GLM-5V-Turbo runs slower. INT8 quantization reduces this overhead, but doesn't close the gap with GLM-5-Turbo's throughput.
Both models share the same context window: approximately 200K tokens per Z.ai's official documentation (OpenRouter lists 202,752 — use Z.ai's docs as the authoritative source for production planning). Maximum output is 131,072 tokens for both.
Performance Comparison Table
| Dimension | GLM-5-Turbo | GLM-5V-Turbo |
|---|---|---|
| Release date | March 15, 2026 | April 1, 2026 |
| Input modalities | Text only | Text, images, video |
| Context window | ~200K tokens | ~200K tokens |
| Max output | 131,072 tokens | 131,072 tokens |
| OpenRouter price | $1.20/$4.00 per M tokens | $1.20/$4.00 per M tokens |
| Output speed | 200+ TPS (reported by Z.ai) | 34th percentile (benchable.ai) |
| Intelligence Index (AA) | 47 | 43 |
| Parameter count | Undisclosed | Undisclosed |
| License | Proprietary, API-only | Proprietary, API-only |
| File upload/download | Supported via Z.ai API | Not currently supported in MCP mode |
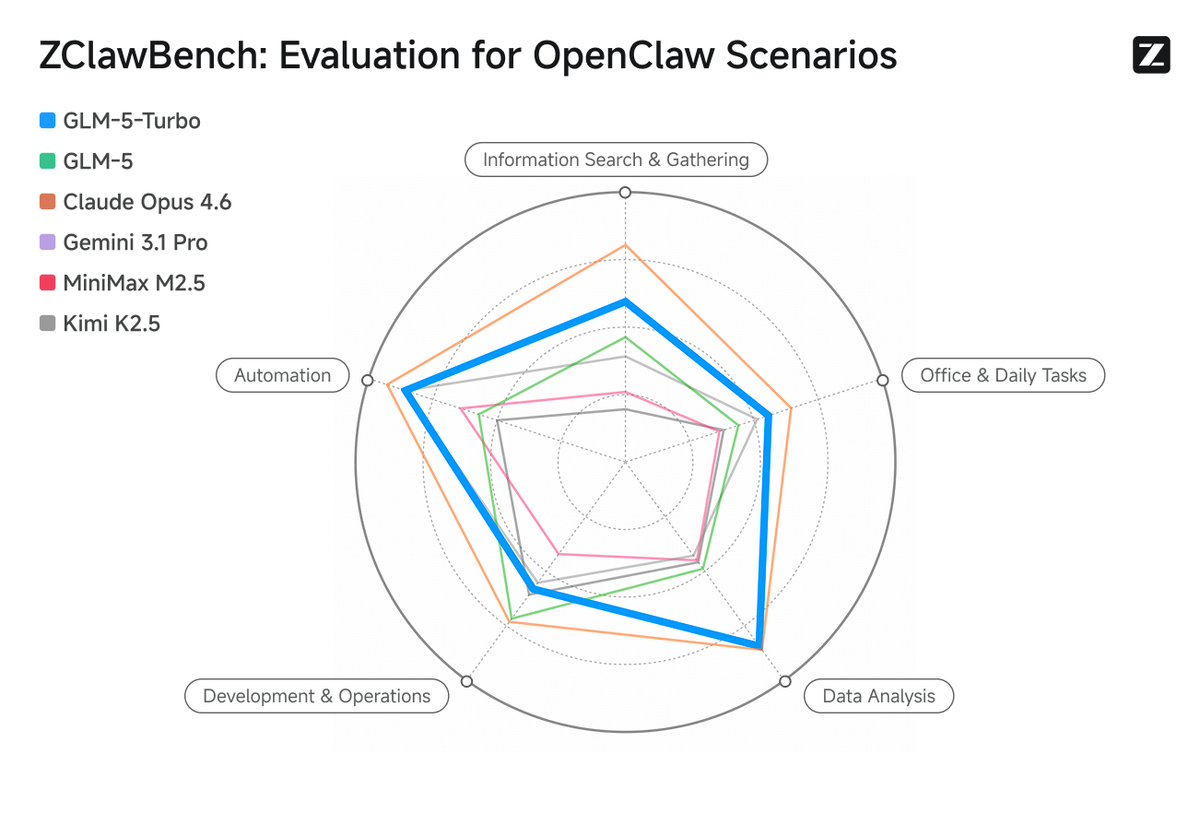
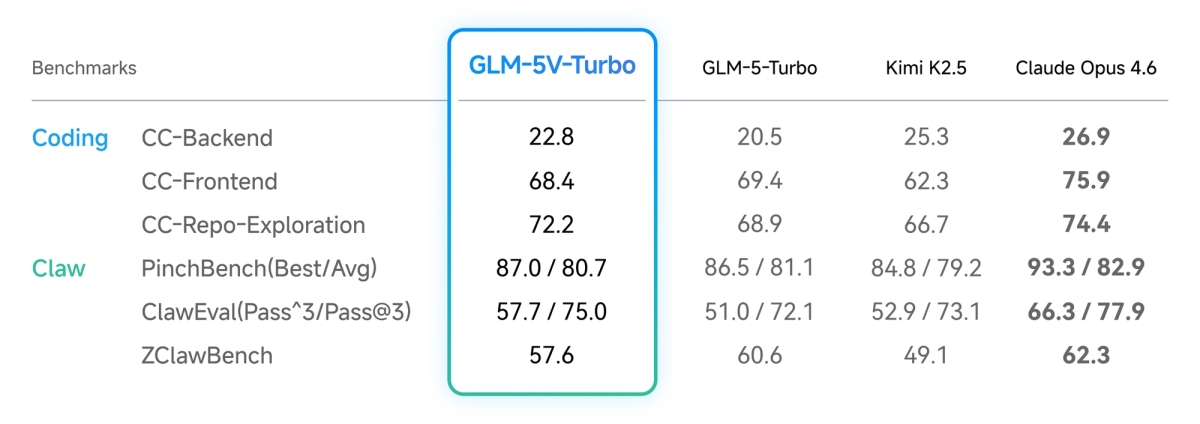
| ZClawBench | Strong (proprietary benchmark) | Strong (proprietary benchmark) |
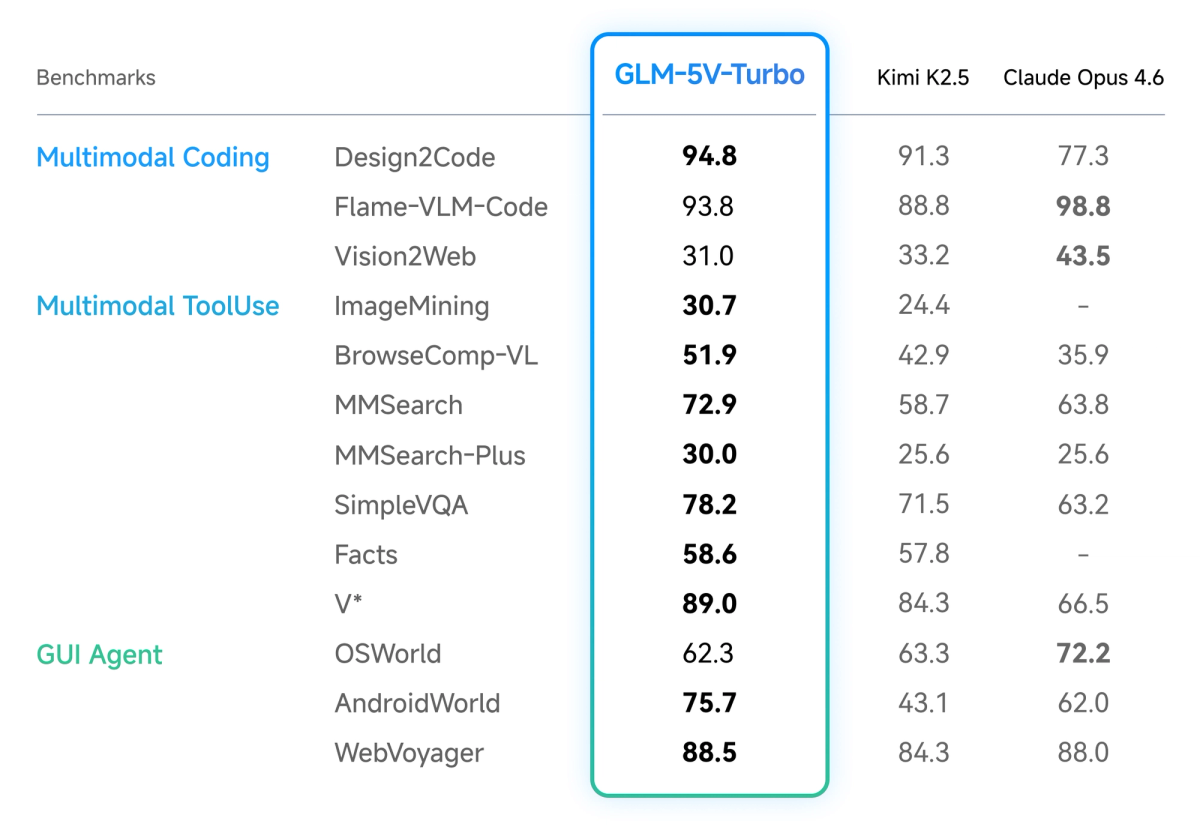
| Design2Code (official) | Not applicable | 94.8 vs Claude Opus 4.6's 77.3 |
Benchmark sourcing note: ZClawBench is Z.ai's own benchmark; independent validation is limited. Design2Code is an existing benchmark but Z.ai's specific test methodology hasn't been independently audited. The Intelligence Index scores are from Artificial Analysis (third-party). Speed data for GLM-5-Turbo is from Z.ai's release reporting; GLM-5V-Turbo speed ranking is from benchable.ai (third-party). Treat all figures as directional until independent benchmarks catch up.
Use Case Decision Framework
Choose GLM-5-Turbo when:
- Your agent loop is entirely text-based: code generation, refactoring, debugging, API integration, tool calling
- Throughput matters — you're running high-volume tasks, long chains, or latency-sensitive pipelines
- You need maximum reliability in multi-step tool calling (GLM-5-Turbo's primary training target)
- You're integrating with OpenClaw as the primary runtime — Z.ai's docs explicitly recommend GLM-5-Turbo as the default for OpenClaw agent configs
- You want the fastest possible text generation at this price tier
Choose GLM-5V-Turbo when:
- Your agent needs to act on visual input: design mockups → frontend code, screenshots → debugging, UI recordings → test scripts
- You're building GUI automation agents that need to interpret screen state (AndroidWorld, WebVoyager-style tasks)
- You're willing to accept slower inference in exchange for native visual reasoning
- Your workflow includes screen recordings, wireframes, or Figma-style exports as inputs
Don't choose GLM-5V-Turbo when:
- Your task is text-only — the vision encoder adds cost and latency for zero benefit
- Your pipeline requires file upload/download in MCP mode (currently unsupported)
- You're running latency-sensitive real-time agent interactions where 34th-percentile speed creates visible friction
- You're routing large volumes of simple tasks where throughput cost matters more than visual capability
The hybrid case: some teams use both in the same pipeline. GLM-5V-Turbo handles the visual perception subtask — interpreting a UI layout, generating a component map from a screenshot — and passes structured text output to GLM-5-Turbo for the execution subtask. This adds orchestration overhead but avoids paying the vision penalty on non-visual work.
Pricing and Availability
Both models are priced identically on OpenRouter as of April 2026: $1.20 per million input tokens, $4.00 per million output tokens — confirmed on GLM-5-Turbo's OpenRouter page and GLM-5V-Turbo's OpenRouter page. The same pricing applies to Z.ai's direct API.
This equal pricing is not intuitive — most assumptions about model pricing expect vision capability to cost more. Z.ai has positioned them as parallel options at the same tier rather than vision being a premium add-on. That said, vision inference uses more compute per call even at the same token price: image tokens are counted separately, and visual inputs can inflate effective token usage significantly depending on image resolution and count.
Z.ai also offers a GLM Coding Plan subscription (approximately $9/month entry tier) that includes model access without per-token billing. For Coding Plan users, GLM-5V-Turbo access at launch required a trial application via Google Form — check current availability at Z.ai's documentation before planning around it.
For pure API access via OpenRouter, both models are available immediately with an OpenRouter key. Neither requires special access.
Limitations of Both Models
Shared limitations:
- Both are closed-source and API-only. No self-hosting, no weight inspection, no fine-tuning
- Parameter counts are undisclosed by Z.ai — any figures cited elsewhere are unconfirmed speculation
- Both are produced by a Chinese company (Zhipu AI / Z.ai) subject to Chinese data law — review their privacy policy against your compliance posture before routing sensitive code through the API
- Key benchmarks (ZClawBench, ClawEval) are Z.ai's own proprietary evaluations; independent reproduction is limited as of this writing
- Rate limits are not publicly documented; Z.ai has had capacity constraints at previous model launches — test throughput under real load before committing to production
GLM-5-Turbo specific:
- No visual input whatsoever — if your requirements change to include visual tasks, you need to switch models or add a separate vision layer
- Being closed-source and proprietary means the "Turbo" training specifics are opaque; the tool-calling reliability gains Z.ai claims are reported but not independently verified at the architecture level
GLM-5V-Turbo specific:
- 34th percentile speed is a real operational constraint for latency-sensitive workflows, not just a benchmark footnote
- File upload/download not currently supported in MCP integration mode — limits its utility in document-heavy agent workflows
- The vision architecture adds a fixed overhead per call regardless of whether the specific request uses visual input — if you're routing text-only queries through GLM-5V-Turbo, you're paying a latency penalty for unused capability
- As a newer model (April 2026), it has less community production exposure than GLM-5-Turbo
FAQ
Can I switch between GLM-5-Turbo and GLM-5V-Turbo mid-pipeline?
Yes, via OpenRouter's model routing. Because both expose an OpenAI-compatible API surface, the switch is a config change — update the model ID string. The practical challenge is managing context: if you switch mid-session, the new model doesn't inherit visual understanding from a previous GLM-5V-Turbo call. For hybrid architectures, it's cleaner to route specific subtasks to each model rather than switching mid-session.
Is GLM-5V-Turbo worth the speed penalty for coding-only tasks?
No. For text-in, text-out coding work — debugging, code generation, refactoring, API integration — GLM-5-Turbo runs faster at the same price with more focused training for the task. The vision encoder doesn't help with problems that don't involve visual input. Use GLM-5V-Turbo only when visual understanding is part of the actual task.
How do these compare to GLM-5 (the open-source base)?
GLM-5 (released February 2026) is open-source under MIT, self-hostable, and text-only. Its baseline Artificial Analysis Intelligence Index score is 50 — slightly higher than GLM-5-Turbo's 47 — but it's slower and priced lower on OpenRouter ($0.72/$2.30 per M tokens via OpenRouter, though this varies by provider). The Turbo variants are commercially tuned derivatives optimized for specific execution patterns, not upgrades in raw capability. If you're open to self-hosting and don't need OpenClaw-specific optimization, GLM-5 is worth evaluating as a cost-efficient text agent base.
Do either of these work with Verdent's parallel worktree architecture?
Both can serve as subagent models in a multi-agent workflow. Verdent's parallel execution routes tasks to separate isolated environments — GLM-5-Turbo fits as a fast text executor for parallel coding subtasks; GLM-5V-Turbo fits for subtasks that require visual input processing. The model choice is per-agent, not per-workflow, so you can mix them in the same Verdent session if your subtasks have different input requirements.
What happens with image token pricing when using GLM-5V-Turbo?
Image tokens are counted toward your input token total at the rates above ($1.20/M). Higher resolution images generate more tokens. Z.ai doesn't publish a specific image token conversion table in English-language documentation — test with representative images before committing production budgets. At high image volume (e.g., batches of full-screen UI screenshots), effective per-call costs can be significantly higher than text-only equivalents even at the same nominal rate.
Related Reading
- GLM-5V-Turbo: Z.ai's Vision Coding Agent Explained — Full technical breakdown of GLM-5V-Turbo's architecture, benchmarks, and limitations.
- Claw Code: Claude Code, OpenClaw, and What Each Actually Does — The OpenClaw ecosystem that GLM-5-Turbo was specifically optimized for.
- Claude Code vs Verdent: Multi-Agent Architecture Compared — How to wire GLM models into a parallel multi-agent coding workflow.
- LLM Knowledge Base for Coding Agents: Beyond RAG — Persistent context architecture that applies to whichever model you choose.
- What Is G0DM0D3? — Multi-model parallel evaluation tool for testing GLM-5-Turbo and GLM-5V-Turbo against alternatives before committing.
