
Every coding-model launch quotes a SWE-bench score, and most of them are quietly misleading — not because the numbers are fake, but because the same model can score 50% or 70% on "SWE-bench" depending on the harness around it, the variant being measured, and who ran the test. A single benchmark name now points to several genuinely different numbers. That's the thing worth understanding: SWE-bench is the closest the industry has to a realistic test of coding agents, and also one of the easiest scores to read wrong. This guide explains what it actually measures, how it works, and how to read a SWE-bench number without being fooled by it.
SWE-bench in One Paragraph
Real GitHub issues, patches, and test suites
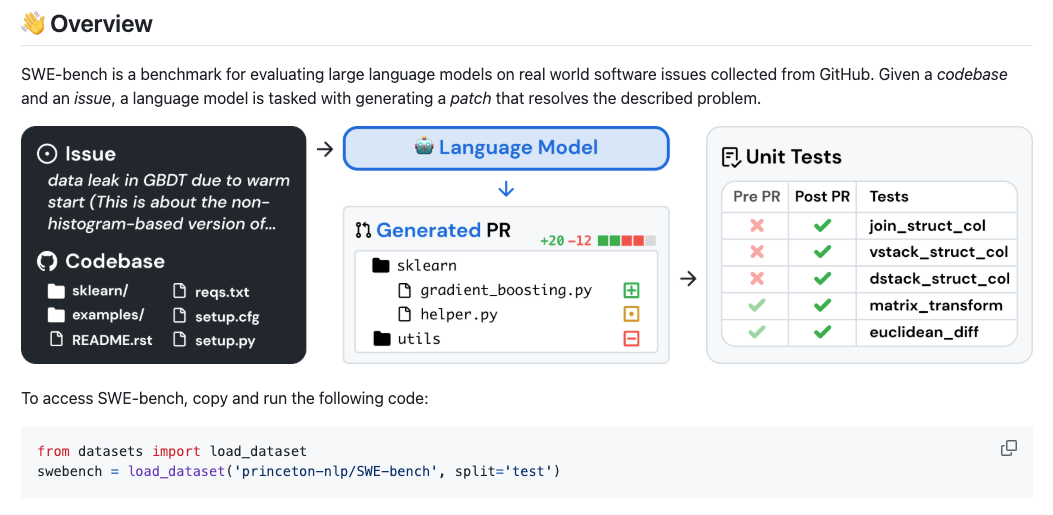
SWE-bench is a benchmark that tests AI systems on real software engineering tasks drawn from actual GitHub issues. Instead of asking a model to write a function from a prompt (the toy code-generation setup), SWE-bench gives an agent a real repository with a real reported issue and asks it to produce a patch that fixes the issue — verified by running the project's actual test suite. Each task is a genuine bug or feature request that a real developer resolved, with the real tests that validate a correct fix. That's what makes it meaningfully harder and more realistic than simple code-generation benchmarks: the agent has to understand an existing codebase, locate the problem, and produce a fix that passes tests written by the project's maintainers — the actual shape of software engineering work.
How SWE-bench Actually Works
The full evaluation loop
The evaluation loop is what makes SWE-bench realistic, and understanding it is key to reading scores correctly. For each task, the agent gets a Docker container with the target repository at the right commit, the text of the issue, and a test runner — but crucially not the failing test itself. The agent has to explore the codebase, understand the issue from its description, figure out what's broken, and produce a patch. That patch is then applied and the project's hidden test suite is run: if the tests that should pass now pass (and the ones that should fail still fail), the task is resolved. The score is the percentage of tasks resolved.
This loop tests things a code-generation prompt can't: navigating an unfamiliar repository, reasoning about the issue without being handed the failing test, making changes that don't break existing functionality, and producing a fix that satisfies tests the agent never saw. It's an agentic task — explore, reason, act, verify — not a single-shot generation, which is exactly why it correlates better with real coding ability than older benchmarks.
Verified, Pro, and adjacent variants
"SWE-bench" isn't one fixed thing — there are several variants with different difficulty and purpose, which is the first source of score confusion:
- SWE-bench Verified — a human-validated 500-task subset (curated by OpenAI) that removes ambiguous or infeasible problems from the original benchmark, so a failure reflects the agent, not a broken task. It's the most-quoted variant and the one most model launches cite.
- SWE-bench Pro — a harder benchmark of longer-horizon, multi-file tasks across more repositories and languages, with a public set and a private commercial set. Scores drop sharply versus Verified (top models that score 70%+ on Verified often land far lower on Pro), which reflects its greater difficulty and realism — and the private subset is harder still, testing generalization to unseen code.
- SWE-bench Multilingual — extends the tasks across multiple programming languages, testing beyond the Python-heavy original.
Adjacent agentic benchmarks you'll see quoted alongside SWE-bench — like Terminal-Bench (terminal/command-line task completion) and FrontierSWE-style evaluations — measure related but distinct capabilities; they're not interchangeable with SWE-bench scores.
Common Misunderstandings About the Benchmark
What the score does and doesn't measure
The biggest misunderstanding is treating a SWE-bench score as a single measure of "how good a model is at coding." It isn't. A SWE-bench score measures how often a particular system (model plus its agent scaffold) resolved a particular set of tasks under particular conditions. That's narrower than "coding ability" in several ways.
It does measure: the ability to resolve real, test-validated issues in real repositories — a genuinely useful signal, far better than toy code generation. It doesn't measure: how the model handles your codebase, your languages, your conventions, or your kinds of problems; code quality beyond "tests pass" (a patch can pass tests while being poorly designed); or anything about the many tasks that aren't in the benchmark's distribution. A high score means the system is capable on the benchmark's tasks; it does not guarantee performance on yours. The benchmark is a population-level signal, not a prediction about your specific work.
Why Leaderboard Position Isn't the Full Story
Scaffolding, harness, and vendor-reported differences
Here's the part that matters most for reading scores, and the answer to why the same model shows up with wildly different SWE-bench numbers: the agent scaffold around the model can move the score by 10 to 20 points without changing the model at all.
The scaffold (or harness) is everything wrapped around the raw model — how the prompt is constructed, which tools the agent gets, how its output is parsed into actions, how context and memory are managed, and how failures are retried. This isn't a minor implementation detail; it's a major determinant of the score. Analyses of SWE-bench Pro have attributed swings of 10-20 points to harness choices alone, and the same model run through different agent systems can produce multi-point spreads from scaffold differences. A mid-tier model in a well-designed harness can outscore a stronger model in a poor one. The model is the performance ceiling; the scaffold determines how close you get to it. (Even the model provider can matter: the same model served through different API providers can show measurable performance variance under an identical scaffold.)
This is why vendor-reported scores and standardized-harness scores diverge so much. A lab reporting its own SWE-bench number is running the model in its own optimized scaffold, which legitimately produces a higher number than the same model on a neutral, standardized harness — without either being "wrong." It just means the two numbers measure different system configurations. When you see a model's SWE-bench score, the score belongs to the whole system that produced it, not to the model in isolation — which is why leaderboard rank, especially across differently-sourced numbers, is the least reliable thing on the page.
FAQ
Why do the same models often get very different SWE-bench scores across reports?
Because the score belongs to the whole system — model plus agent scaffold — not the model alone, and the scaffold varies between reports. The scaffold (prompt construction, tool set, output parsing, context management, retry logic) can move a SWE-bench score by 10-20 points on identical model weights. So a vendor running a model in its own optimized harness reports a higher number than the same model on a neutral standardized harness — neither is necessarily wrong; they measure different configurations. Add variant differences (Verified vs Pro vs Multilingual) and even API-provider variance, and one model name legitimately maps to several scores.
How much does the choice of scaffolding affect how results should be read?
Enough that scaffolding should be your first question when reading any SWE-bench score. Documented analyses attribute 10-20 point swings to harness choices alone, and the same model in different agent systems produces meaningful spreads — a gap large enough to reorder a leaderboard. Practically, this means a SWE-bench number is uninterpretable without knowing the scaffold that produced it: a high vendor-reported score in a bespoke harness and a lower score on a standardized board can both be accurate for the same model. When comparing scores, only compare numbers produced under the same harness; comparing a vendor's optimized-scaffold number to another model's standardized-harness number is comparing different things, not different models.
What should builders keep in mind when comparing SWE-bench scores from different sources?
Three things. Check the variant — Verified, Pro (public/private), and Multilingual are different difficulties, comparable only to the same variant. Check the harness — scores are comparable only under the same scaffold, so vendor-reported numbers (optimized scaffold) aren't comparable to standardized-board numbers. And treat vendor-reported scores as a ceiling claim, not a neutral measure. The safest comparison is models on the same standardized harness and variant; anything else is apples-to-oranges. Ultimately the most reliable signal isn't any leaderboard — it's running the candidates on your own representative tasks.
When is a high SWE-bench score least predictive of actual coding performance?
When your work differs from the benchmark's distribution, and when the score came from a heavily optimized scaffold you won't replicate. SWE-bench tasks skew toward certain repositories, languages (heavily Python in the original), and a specific kind of test-validated bug-fix; if your work is in other languages, different problem types, or domains the benchmark doesn't cover, a high score predicts little about your results. It's also least predictive when the headline number came from a vendor's bespoke harness — your real-world setup (your IDE agent, your tools) is a different scaffold that will produce different results. The score is least predictive precisely when the gap between the benchmark's conditions and your conditions is largest, which is why your own testing matters more than any published number.
Conclusion
SWE-bench is the most realistic widely-used test of coding agents because it uses real GitHub issues, real repositories, and real test suites — a genuine step up from toy code generation, and worth understanding for exactly that reason. But a SWE-bench score is not a single fact about a model: it's a measurement of a whole system (model plus scaffold) on a specific variant under specific conditions, and the scaffold alone can swing it 10-20 points. So read these scores carefully — check the variant, check the harness, treat vendor-reported numbers as ceiling claims, and never compare numbers from different scaffolds as if they measured the same thing. The benchmark is a useful population-level signal, not a prediction about your codebase. When the decision actually matters, the score to trust is the one you generate by running the model on your own real tasks.
Related Reading
