
Achei o DeepSeek-TUI no GitHub Trending na semana passada e quase passei direto. Mais um wrapper de DeepSeek, pensei. Aí li o README com mais atenção — arquitetura dual-binary em Rust, streaming nativo do thinking-mode, contexto de 1M tokens no design desde o início, e um primitivo de sub-agentes paralelos chamado RLM que dispara até 16 instâncias baratas do V4-Flash numa chamada só. Isso não é wrapper. É um harness construído por alguém que passou tempo de verdade com a economia da API do DeepSeek V4. É isso que ele é, como funciona, e pra quem vale a pena.
DeepSeek-TUI em um parágrafo

O DeepSeek-TUI é um terminal coding agent open-source construído em torno do DeepSeek V4, criado pelo desenvolvedor independente norte-americano Hunter Bown (GitHub: Hmbown). Não é produto oficial da DeepSeek. O projeto lançou em 19 de janeiro de 2026, chegou à v0.8.8 com 37 releases, e atingiu aproximadamente 2,3K stars no GitHub em início de maio de 2026 depois de aparecer no GitHub Trending. Roda como TUI com navegação por teclado no terminal, dá aos modelos frontier da DeepSeek acesso direto ao seu workspace — lendo e escrevendo arquivos, rodando comandos shell, fazendo buscas na web, gerenciando git, orquestrando sub-agentes — e tem licença MIT. A instalação é um comando: npm install -g deepseek-tui (o pacote npm é só um downloader; nenhum runtime Node é necessário em produção).
A arquitetura dual-binary
O DeepSeek-TUI vem com dois binários obrigatórios. O binário deepseek é o dispatcher CLI — cuida de autenticação, configuração, seleção de modelo e gerenciamento de sessão, depois delega a execução real do agente pro deepseek-tui. Rodar qualquer um dos dois binários sozinho gera um erro MISSING_COMPANION_BINARY; os dois precisam estar no seu PATH.
A separação é intencional. O dispatcher oferece a interface estável voltada pro usuário (comandos, config, auth) enquanto o runtime cuida do loop do agente e da renderização do TUI. Atualizações em um não quebram necessariamente a interface do outro.
# Ambos os binários são necessários — instale via npm (baixa binários pré-compilados):
npm install -g deepseek-tui
# Ou via Cargo (compila da fonte, requer Rust 1.85+):
cargo install deepseek-tui-cli --locked # fornece `deepseek`
cargo install deepseek-tui --locked # fornece `deepseek-tui`
# Ou Homebrew (macOS):
brew tap Hmbown/deepseek-tui && brew install deepseek-tuiRust + ratatui, par de binários único, sem Node/Python. Os dois binários compilam para Rust nativo. O footprint em runtime é mínimo — a ferramenta reporta cerca de 12MB de RAM em idle. A biblioteca ratatui fornece a camada de UI do terminal: painéis divididos pra chat, previews de código e histórico de comandos, navegação por teclado em tudo. Sem Electron, sem runtime Python, sem daemon Node rodando em background. O caminho do npm install é só um downloader de conveniência; os binários de verdade são Rust pré-compilado.
Binários pré-compilados cobrem Linux x64/ARM64, macOS x64/ARM64 (Apple Silicon) e Windows x64. O suporte a plataformas é real: a v0.8.8 corrigiu especificamente um bug com separador de path no Windows e a disponibilidade de binários ARM64 no Linux que estava faltando em versões anteriores.
Loop do engine e registry de ferramentas. A arquitetura interna: deepseek (dispatcher) → deepseek-tui (binário companion) → interface ratatui ↔ async engine ↔ cliente de streaming compatível com OpenAI.
As tool calls roteiam por um registry tipado com sete categorias:
| Categoria | O que cobre |
|---|---|
| shell | Execução de comandos shell, sandboxed por nível de confiança do workspace |
| file ops | Leitura, escrita, patch, busca em arquivos do workspace |
| git | Stage, commit, branch, diff |
| web | Busca na web (DuckDuckGo com fallback no Bing), fetch de URL |
| sub-agents | Spawn de sessões de agente filho pra subtarefas paralelas |
| MCP | Conexão a servidores Model Context Protocol via stdio |
| RLM | Fan out de 1–16 instâncias do V4-Flash pra raciocínio paralelo |
Resultados chegam em streaming de volta no transcript em tempo real.
Por que é um harness model-specific, não um wrapper
Construído em torno do contexto de 1M e prefix cache do DeepSeek V4. Wrappers genéricos compatíveis com OpenAI tratam contexto como algo a gerenciar em torno dos limites do modelo. O DeepSeek-TUI trata a janela de 1M tokens do V4 como primitivo de design. O estimador de custo rastreia cache hits separado de cache misses — os tokens de entrada em cache do V4 custam 1/10 dos não-cacheados — e o CHANGELOG mostra respostas diretas às atualizações de preço da DeepSeek (a atualização de preço de cache-hit na v0.8.8 para 0.003625/0.0028/0.0145 por 1M tokens reflete as mudanças de precificação live da DeepSeek aplicadas diretamente ao estimador de custo do TUI).
O recurso auto-compact cuida do crescimento do contexto com sumarização por substituição perto do limite ativo do modelo. Opt-in (auto_compact = false por padrão); a alternativa manual é o /compact explícito quando você quer controlar quando a sumarização acontece.
Streaming nativo do thinking-mode. O DeepSeek V4-Pro expõe os traces de raciocínio como reasoning_content nas respostas da API. O DeepSeek-TUI renderiza esses traces diretamente no terminal — você assiste o chain-of-thought do modelo se desenrolando linha por linha enquanto trabalha. Não é reconstruído a partir do output; é o stream de pensamento bruto exibido num painel dedicado.
A entrada do CHANGELOG sobre thinking-mode é específica sobre o que está sendo tratado: "thinking-mode tool turns now checkpoint the engine's authoritative API transcript, including assistant reasoning_content on reasoning-to-tool-call turns with no visible assistant text." A implementação lida com um edge case real da API — turns onde o modelo pensa mas não produz texto visível antes de chamar uma ferramenta — que wrappers genéricos costumam tratar de forma incorreta ou nem tratam.
Como difere dos wrappers com "suporte ao DeepSeek". A maioria das ferramentas que anuncia suporte ao DeepSeek adicionou isso aceitando um parâmetro base_url apontando pro endpoint compatível com OpenAI da DeepSeek. Funciona, mas foram projetadas em torno do comportamento de outro modelo. Os system prompts do DeepSeek-TUI, o rastreamento de custo, a estratégia de compactação de contexto e a arquitetura RLM são todos projetados especificamente em torno da economia e capacidades da API do V4.
Três modos: Plan, Agent, YOLO

Plan: exploração read-only. O modo Plan restringe o agente a operações de leitura. Pode ler arquivos, fazer busca no codebase, analisar estrutura e produzir um plano — mas não pode executar comandos shell, escrever arquivos ou fazer commits no git. Use quando quiser entender o que o agente faria antes de fazer qualquer coisa, ou quando estiver explorando um codebase desconhecido e quiser análise sem side effects.
Agent: padrão, com aprovação de tool calls. O modo Agent é o padrão. Cada tool call que modifica estado — escrever um arquivo, rodar um comando shell, commitar no git — requer aprovação explícita sua antes de executar. Você vê a ação proposta, aprova ou rejeita, e o agente segue. Esse é o modo certo pra maior parte do trabalho de código real: você fica no controle do que realmente acontece no seu repositório.
YOLO: aprovação automática dentro de workspaces confiáveis. O modo YOLO desativa os prompts de aprovação. O agente executa tool calls automaticamente conforme aparecem. O CHANGELOG nota especificamente que a v0.8.8 corrigiu um bug onde git -C ... era auto-aprovado no modo YOLO sem a verificação de confiança do workspace — o tipo de bug que importa em produção. O modo YOLO é adequado pra workspaces confiáveis onde você revisou a tarefa e quer que o agente rode até o fim sem interrupção.
RLM (rlm_query) — Sub-agentes paralelos
1–16 instâncias do deepseek-v4-flash em fan out. O rlm_query é o primitivo de raciocínio paralelo do DeepSeek-TUI. Quando o agente principal chama rlm_query, ele dispara entre 1 e 16 chamadas concorrentes de sub-agente, cada uma rodando no deepseek-v4-flash por padrão. Os filhos podem ser promovidos ao V4-Pro por chamada quando a subtarefa precisa de mais profundidade de raciocínio.
O CHANGELOG documenta a intenção de design: "Inspired by Alex Zhang's RLM work and Sakana AI's published novelty-search research, but trimmed to what an agent loop actually needs." Não é um artefato de pesquisa — é uma ferramenta prática pra tarefas de análise em lote.
Casos de uso: análise em lote, decomposição, raciocínio paralelo. O RLM serve pra tarefas que se decompõem em subtarefas independentes que você quer rodar simultaneamente: analisar múltiplos arquivos em busca de um padrão comum, rodar queries de pesquisa em paralelo, avaliar múltiplas abordagens de implementação de uma vez. Com a precificação do V4-Flash ($0.14/$0.28 por milhão de tokens mesmo na taxa revertida de desconto), disparar 16 chamadas em paralelo custa uma fração do que custa uma única chamada do V4-Pro.
Skills e suporte a MCP
Descoberta de skills percorre .agents/skills, .claude/skills e ~/.deepseek/skills.
O sistema de skills é a sobreposição mais direta com Superpowers e frameworks similares de agentes estruturados. Skills são diretórios contendo um arquivo SKILL.md com nome, descrição e instruções. O agente pode auto-selecionar skills relevantes via load_skill quando as descrições das tarefas correspondem às descrições das skills.
Ordem de descoberta conforme o README: .agents/skills → skills → .opencode/skills → .claude/skills → ~/.deepseek/skills. A inclusão do .claude/skills no caminho de descoberta é intencional — times que já usam o sistema de skills do Claude Code podem reusar esses diretórios sem reestruturar nada.
Skills da comunidade se instalam diretamente do GitHub com /skill install github:<owner>/<repo> — sem serviço de backend necessário.
Servidores MCP via stdio.
A integração com MCP segue o transporte stdio padrão: defina as entradas do servidor na config, deepseek-tui mcp init cria a estrutura de diretórios, e deepseek-tui setup inicializa tanto MCP quanto diretórios de skills em um passo. A implementação é protocolo cliente MCP padrão; qualquer servidor MCP que funcione com Claude Code ou outros agentes com capacidade MCP deve funcionar aqui.
Onde fica entre os terminal coding agents
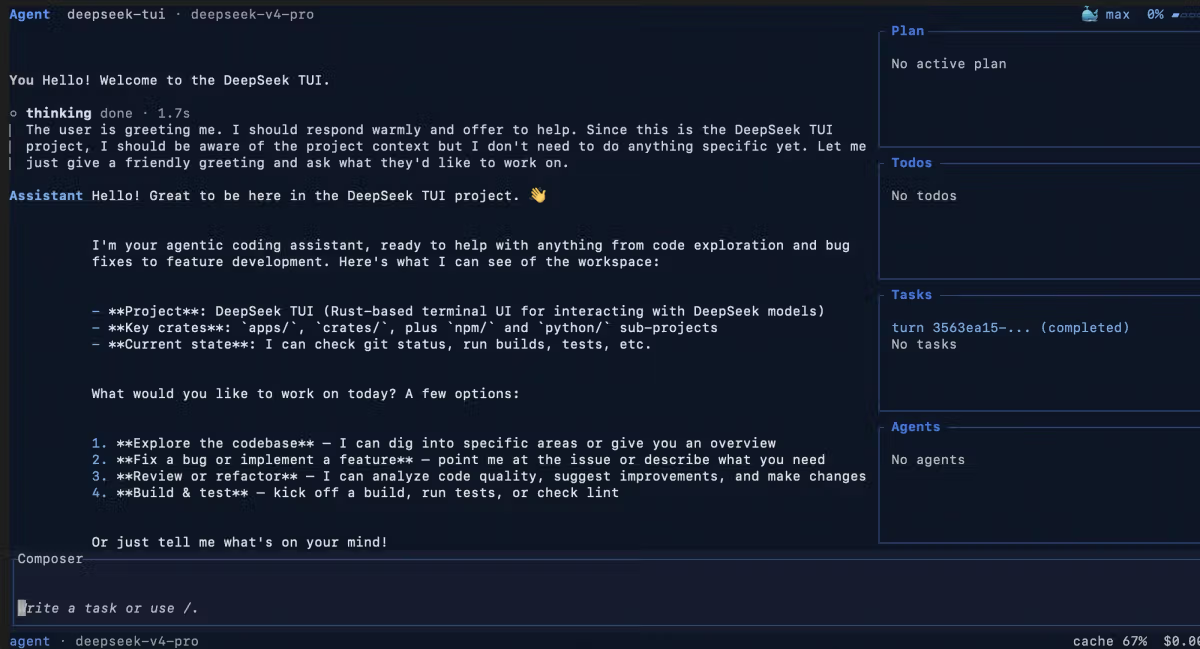
Mesma categoria que Claude Code, Aider, Cline, OpenCode
O DeepSeek-TUI está na mesma categoria que Claude Code (Anthropic, fechado), Aider (open-source, multi-modelo), Cline (extensão VS Code) e OpenCode (open-source, TUI multi-modelo). Todos esses dão a um LLM acesso direto a um workspace local via terminal ou painel de IDE, executam tool calls contra arquivos reais e gerenciam loops de agente multi-turn.
| DeepSeek-TUI | Claude Code | Aider | OpenCode | |
|---|---|---|---|---|
| Modelo principal | DeepSeek V4 | Claude | Qualquer | Qualquer |
| Lock-in de modelo | Soft (foco DeepSeek) | Hard (Claude only) | Nenhum | Nenhum |
| UI | ratatui TUI | Terminal CLI | Terminal CLI | TUI |
| Runtime | Rust binary | Node | Python | Go |
| Open source | ✅ MIT | ❌ | ✅ | ✅ |
| RLM / sub-agentes paralelos | ✅ | ❌ | ❌ | ❌ |
| Thinking-mode streaming | ✅ (V4 nativo) | ✅ (Claude nativo) | Varia | Varia |
O trade-off: lock-in de modelo vs eficiência nativa do DeepSeek.
As decisões de arquitetura do DeepSeek-TUI — estimador de custo calibrado pra precificação do V4, compactação de contexto calibrada pro limite do V4, RLM usando V4-Flash como worker paralelo barato — são fortemente acopladas aos modelos e à economia da API da DeepSeek. Usar com um provider diferente (NVIDIA NIM, Fireworks, SGLang) é suportado na camada de configuração, mas esses providers todos servem modelos DeepSeek; não é um caminho pra rodar GPT-5 ou Claude pelo mesmo TUI.
Esse lock-in é o trade-off correto se V4 é seu modelo preferido. Se você quer um terminal agent model-agnostic, Aider e OpenCode são as alternativas certas.
Quem deve testar (e quem deve pular)
Testa o DeepSeek-TUI se:
- Você já usa DeepSeek V4 via API e quer um workflow de terminal equivalente ao Claude Code sem construir seu próprio agent loop
- A economia de custos da DeepSeek é um fator primário nas suas decisões de tooling — o estimador de custo embutido e o rastreamento de cache hit/miss tornam as vantagens de preço do V4 visíveis por turn
- Você quer capacidade de sub-agentes paralelos (RLM) sem adicionar infraestrutura de orquestração
- Você está self-hosting DeepSeek V4 via SGLang e quer um frontend polido pra isso
Pula o DeepSeek-TUI se:
- Seus modelos principais são Claude, GPT-5.5 ou Gemini — a ferramenta tecnicamente aceita outros endpoints compatíveis com a API mas não foi projetada nem calibrada pra eles
- Você precisa de uma ferramenta estável e em GA pra workflows de produção — a v0.8.8 está em desenvolvimento ativo com releases frequentes; o comportamento na v0.9.x ou v1.0 pode ser diferente
- Você está em ambiente enterprise com procurement controlado de software — a licença MIT é permissiva, mas o ritmo acelerado de releases e o status de projeto comunitário importam pra revisão de segurança
FAQ
O DeepSeek-TUI é um produto oficial da DeepSeek?
Não. Foi criado por Hunter Bown (GitHub: Hmbown), desenvolvedor independente norte-americano. A DeepSeek (a empresa) não está envolvida. O nome é descritivo, não branding oficial.
Posso usá-lo com modelos além do DeepSeek V4?
A configuração suporta NVIDIA NIM, Fireworks AI e SGLang self-hosted — mas todos esses são caminhos pra rodar modelos DeepSeek em infraestrutura diferente, não caminhos pra usar GPT ou Claude. A ferramenta foi projetada especificamente pro comportamento da API V4 da DeepSeek.
Como difere do repo azevedoguigo/deepseek-tui-client?
Escopo completamente diferente. O azevedoguigo/deepseek-tui-client é um cliente de chat terminal mínimo pra DeepSeek — é uma UI de conversa, não um coding agent. Não tem registry de ferramentas, nem operações de arquivo, nem integração com git, nem sistema de sub-agentes. A sobreposição de nome é coincidência; não são projetos relacionados.
O que o "thinking-mode streaming" mostra na tela?
O DeepSeek V4-Pro expõe seu raciocínio de chain-of-thought como reasoning_content nas respostas da API — um campo separado da resposta final. O DeepSeek-TUI renderiza isso num painel dedicado em tempo real enquanto o modelo trabalha. Você vê os passos de raciocínio do modelo conforme chegam, depois a resposta final. Em turns sem raciocínio ou com V4-Flash (que tem thinking mais leve), o painel de raciocínio é mínimo ou ausente.
Funciona no Windows / WSL?
Sim pra ambos. Binários pré-compilados nativos para Windows x64 estão disponíveis; Scoop é o caminho documentado de gerenciador de pacotes Windows conforme o guia oficial de instalação. WSL funciona pelo binário Linux padrão. O CHANGELOG da v0.8.8 inclui especificamente uma correção de separador de path no Windows, o que sinaliza manutenção ativa do Windows em vez de suporte teórico.
