
A Moonshot AI lançou o Kimi K2.6 em 20 de abril de 2026: 1 trilhão de parâmetros, 32B ativos, open-weight, multimodal nativo, quatro variantes — de chat rápido a enxames de 300 agentes paralelos. Se você roda agentes de código multi-etapa ou está avaliando alternativas open-weight ao Claude e ao GPT-5.4, vale entender esse modelo. Se não, não é urgente.
O que vem a seguir cobre a arquitetura, as quatro variantes, o que mudou de verdade em relação ao K2.5, os termos de licença e os limites reais.
O que é o Kimi K2.6 em um parágrafo

O Kimi K2.6 é um modelo Mixture-of-Experts de 1 trilhão de parâmetros da Moonshot AI, sediada em Pequim, lançado open-weight sob uma Modified MIT License. Ele ativa 32 bilhões de parâmetros por token durante a inferência, suporta uma janela de contexto de 262.144 tokens e é distribuído nativamente em quantização INT4. O modelo processa texto, imagens e vídeo na mesma arquitetura, sem módulos de visão separados. Quatro variantes cobrem diferentes casos de uso: Instant pra velocidade, Thinking pra raciocínio profundo, Agent pra pesquisa autônoma e tarefas com documentos, e Agent Swarm pra trabalho paralelo em larga escala. Os pesos estão no Hugging Face e a API fica em platform.moonshot.ai.
Arquitetura em resumo
1T MoE, 32B ativos, 384 experts
O K2.6 herda a mesma arquitetura central do K2 e do K2.5: um design sparse Mixture-of-Experts com 384 experts no total, dos quais 8 são roteados por token mais 1 expert compartilhado. Isso dá a ele a amplitude de parâmetros de um modelo de 1T ao custo de inferência aproximado de um modelo denso de 32B. A arquitetura usa o otimizador Muon (MuonClip), desenvolvido originalmente pela Moonshot para o K2 a fim de estabilizar o treinamento em escala de trilhão de parâmetros — modelos MoE são propensos a explosões de atenção e spikes de loss nessa escala, e o MuonClip foi criado pra preveni-los.
O SwiGLU (Swish-Gated Linear Unit) serve como função de ativação — mais eficiente em hardware do que alternativas mais antigas, e usado em outras famílias open-weight importantes, incluindo a série Llama da Meta.
256K de contexto, MLA, INT4
A janela de contexto prática é de 262.144 tokens. A melhoria declarada da Moonshot em relação ao K2.5 não é o tamanho — o K2.5 já tinha 256K — mas a estabilidade nesse comprimento. Tarefas de código de longo horizonte tendem a degradar conforme o contexto se preenche; o K2.6 ataca especificamente essa degradação.
| Capacidade | K2.5 | K2.6 |
|---|---|---|
| Máx. de sub-agentes paralelos | 100 | 300 |
| Máx. de passos de tool call | 1.5 | 4 |
| Duração máxima de execução autônoma | Não especificado | 12+ horas |
| Input de vídeo | Não | Sim |
| Arquitetura | Mesma base K2 MoE | Mesma base K2 MoE |
O Multi-head Latent Attention (MLA) reduz o footprint de memória do cache KV em comparação com a atenção multi-head padrão, o que importa em escala pra contextos longos e setups multi-agente.
A quantização INT4 é nativa: a Moonshot usou Quantization-Aware Training (QAT) durante a fase de pós-treinamento, ou seja, o modelo aprendeu representações compatíveis com pesos de 4 bits — não foi comprimido depois. O resultado prático é aproximadamente 2x de velocidade de inferência e 50% menos memória de GPU em relação ao FP16, com a Moonshot afirmando perda de qualidade negligenciável. Os pesos INT4 ficam em aproximadamente 594GB no Hugging Face.
As quatro variantes e quando cada uma se encaixa
A Moonshot distribui o K2.6 em quatro variantes acessíveis pelo kimi.com e pela API. Elas compartilham os mesmos pesos do modelo, mas diferem na configuração de decodificação, nas permissões de tools e em como o orçamento de thinking é alocado.
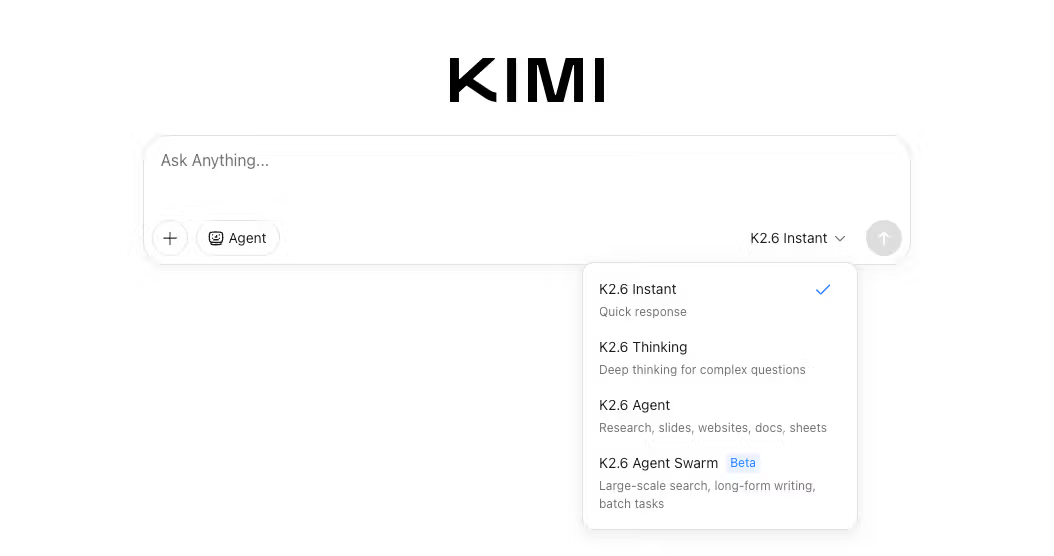
K2.6 Instant
Respostas rápidas sem trace de raciocínio. A temperatura roda mais baixa, o top-p é mais restrito, e o modelo pula a fase de chain-of-thought completamente. O caso de uso prático é buscas rápidas, completações de código curtas e qualquer coisa onde latência importa mais do que profundidade. Se você está construindo um autocomplete ou uma superfície simples de Q&A, esse é o ponto de entrada certo.
K2.6 Thinking
Modo de raciocínio completo. O modelo intercala chain-of-thought com tool calls, alocando um orçamento de compute ao trace de raciocínio antes de produzir output. Essa é a variante que produz os scores de benchmark do K2.6 — o model card do Hugging Face nota que todas as avaliações do K2.6 foram conduzidas com o modo thinking ativado. Use pra debug complexo, decisões de arquitetura, análise de código em múltiplos arquivos ou qualquer coisa onde você precisa que o modelo raciocine antes de agir.
K2.6 Agent
Execução autônoma de tarefas com acesso completo a tools: web search, interpretador de código, operações de arquivo e browser. Os casos de uso pretendidos são pesquisa, geração de documentos (slides, relatórios, planilhas), criação de sites a partir de um prompt e workflows multi-etapa onde você dá ao modelo um objetivo — não uma tarefa. Isso está mais perto de "roda esse projeto" do que "responde essa pergunta".
K2.6 Agent Swarm
A variante operacionalmente mais distinta. O Agent Swarm escala horizontalmente para 300 sub-agentes paralelos, cada um capaz de até 4.000 passos coordenados, com a execução completa podendo se estender por mais de 12 horas. Um prompt complexo é decomposto em subtarefas paralelas e especializadas — pesquisa, análise, codificação, design — cada uma tratada por um agente instanciado dinamicamente, com os resultados integrados pelo orquestrador principal.
Agent Swarm não é uma versão melhorada genérica do Agent. É um modelo operacional diferente: você dá a ele um objetivo grande e decomponível, e deixa rodar. O overhead de subir e coordenar 300 sub-agentes não vale a pena pra tarefas que um único agente resolve em minutos. É projetado pra tarefas em batch, output de longa extensão ou buscas em larga escala que levariam horas de forma sequencial.
O que é de fato novo em relação ao K2.5

300 sub-agentes, execução de 12 horas, multimodal nativo
O K2.5, lançado em janeiro de 2026, introduziu o Agent Swarm como conceito: agentes paralelos auto-dirigidos coordenando em direção a um objetivo comum. O K2.6 expande significativamente esse teto.
A arquitetura é inalterada — o guia de deployment do K2.6 no Hugging Face afirma explicitamente que "Kimi-K2.6 tem a mesma arquitetura do Kimi-K2.5, e o método de deployment pode ser reutilizado diretamente." A diferença está no pós-treinamento: mais compute de treinamento aplicado à estabilidade de longo horizonte, seguimento de instruções e coordenação de swarm. A Moonshot não divulgou exatamente quanto treinamento adicional foi feito pro K2.6.
O input nativo de vídeo é a outra adição notável. O K2.5 processava imagens; o K2.6 adiciona vídeo (mp4, mov, avi, webm e outros, recomendado até resolução 2K). O encoder de visão é nativo ao pré-treinamento do modelo, não um módulo adicionado depois.
Animação de frontend e geração de shaders WebGL também são destacadas nos materiais de lançamento da Moonshot — o modelo pode produzir seções hero com vídeo, animações de shader GLSL/WGSL e motion design baseado em GSAP a partir de prompts de texto. Essa é uma adição de capacidade específica em relação à habilidade geral de código frontend do K2.5.
Quem deve prestar atenção
Devs sênior, tech leads, times rodando agentes de longo horizonte
O K2.6 não está tentando ser um chatbot melhor. Sua diferenciação é estreita e deliberada: é um modelo pra desenvolvedores e times que já estão rodando ou planejam rodar agentes de IA em tarefas que levam tempo — migrações de código, refatorações grandes, pesquisa multi-etapa, automação de infraestrutura. Se o seu workflow envolve um agente chamando tools 50 vezes pra completar uma tarefa, o K2.6 é relevante. Se você está pedindo a um modelo pra explicar uma função, não é.
O lançamento open-weight importa pra dois públicos específicos. Times com requisitos de soberania de dados — setores regulados, codebases sensíveis a segurança — podem rodar o K2.6 na própria infraestrutura. Times fazendo inferência em alto volume podem hospedar o próprio modelo e evitar o preço por token da API em cargas de trabalho sustentadas. Pra todo mundo else, a API em platform.moonshot.ai cobre as mesmas capacidades sem a complexidade operacional.
O preço na API da Moonshot é significativamente menor do que o Claude Opus 4.6 e o GPT-5.4 pra tarefas comparáveis. Pra workflows de agente que queimam milhares de tool calls por execução, essa diferença se acumula. Se o trade-off de qualidade é aceitável pro seu caso de uso requer teste com suas cargas de trabalho reais — não benchmarks.
Limites conhecidos e questões em aberto
**Os requisitos de hardware são substanciais. **Rodar o K2.6 localmente com qualidade completa requer 8× GPUs H100 ou H200 pra produção. A variante INT4 pode rodar em 4× H100 com comprimento de contexto reduzido. Experimentos da comunidade mostram o modelo rodando em hardware consumer (dual Mac Studios com 512GB de RAM cada) em throughput muito baixo — aproximadamente 1–7 tokens por segundo dependendo da configuração, o que é impraticável pra maioria dos workflows reais. APIs de nuvem são o caminho de deployment realista pra maioria dos times.
Os números de benchmark são auto-reportados no lançamento. O model card do Hugging Face nota que benchmarks sem scores publicamente disponíveis foram re-avaliados pela Moonshot nas mesmas condições usadas pro K2.6 e estão marcados com asterisco. A validação independente por terceiros das afirmações de benchmark do K2.6 vai levar semanas. As afirmações sobre agentes de longo horizonte (execuções de 12 horas, 4.000 tool calls) são particularmente difíceis de replicar rapidamente em escala.
Contexto geopolítico. A Moonshot AI é uma empresa chinesa, e o lançamento do K2.6 chega durante um escrutínio contínuo de empresas chinesas de IA no mercado americano. A Câmara dos EUA está considerando legislação que pode afetar empresas chinesas de IA operando internacionalmente. Pra times com requisitos de conformidade, a jurisdição do fornecedor é um fator relevante junto com a capacidade técnica.
Claw Groups é uma feature em preview. A funcionalidade "Claw Groups" — que permite colaboração humano-máquina onde uma execução autônoma pode acionar trabalhadores humanos pra subtarefas específicas — está listada como research preview no lançamento, não como uma capacidade geralmente disponível.
FAQ
O Kimi K2.6 é gratuito?
Os pesos são gratuitos pra baixar e usar sob a Modified MIT License. A interface de chat em kimi.com é gratuita com limites de uso (a Moonshot oferece planos de assinatura chamados Moderato, Allegretto e Vivace). O acesso via API em platform.moonshot.ai é pago por token. Não há taxas por usuário pra o modelo open-weight em si.

O Kimi K2.6 é gratuito?
Onde posso rodar o Kimi K2.6 localmente?
Os pesos estão no Hugging Face (moonshotai/Kimi-K2.6). Três engines de inferência suportam oficialmente o K2.6: vLLM, SGLang e KTransformers (a própria engine da Moonshot construída pra arquitetura K2). O guia de deployment no model card recomenda vLLM 0.19.1 pra uso estável em produção. O hardware mínimo viável pra uso prático é 4× H100 com quantização INT4 em comprimento de contexto reduzido. A arquitetura é idêntica ao K2.5, então configurações de deployment existentes do K2.5 transferem diretamente — basta trocar os pesos do modelo.
Como funciona a Modified MIT License pra uso comercial?
A licença é MIT padrão com uma modificação: se você fizer deploy do K2.6 (ou de um derivado) em um produto ou serviço comercial que ultrapasse 100 milhões de usuários ativos mensais, ou que gere mais de US$20 milhões em receita mensal, você deve exibir em destaque "Kimi K2" na interface do usuário desse produto. Abaixo desses limites, a licença funciona como MIT padrão — use comercialmente, modifique, redistribua, sem royalties. Os limites afetam uma fração pequena de usuários potenciais. A maioria dos times, incluindo startups bem financiadas, fica bem abaixo de ambos os limites.
O Kimi K2.7 está chegando em breve?
Não há anúncio oficial do K2.7. A série K2 se moveu rapidamente — cinco lançamentos significativos entre julho de 2025 e abril de 2026 — mas a Moonshot não divulgou um roadmap. Houve discussões na comunidade no r/LocalLLaMA sobre a Moonshot trabalhando em um modelo provisoriamente chamado de Kimi K3, com especulações sobre uma contagem de parâmetros na faixa de 3–4 trilhões. São rumores não verificados da comunidade, não informações oficiais. Trate-os como especulação até a Moonshot confirmar algo.
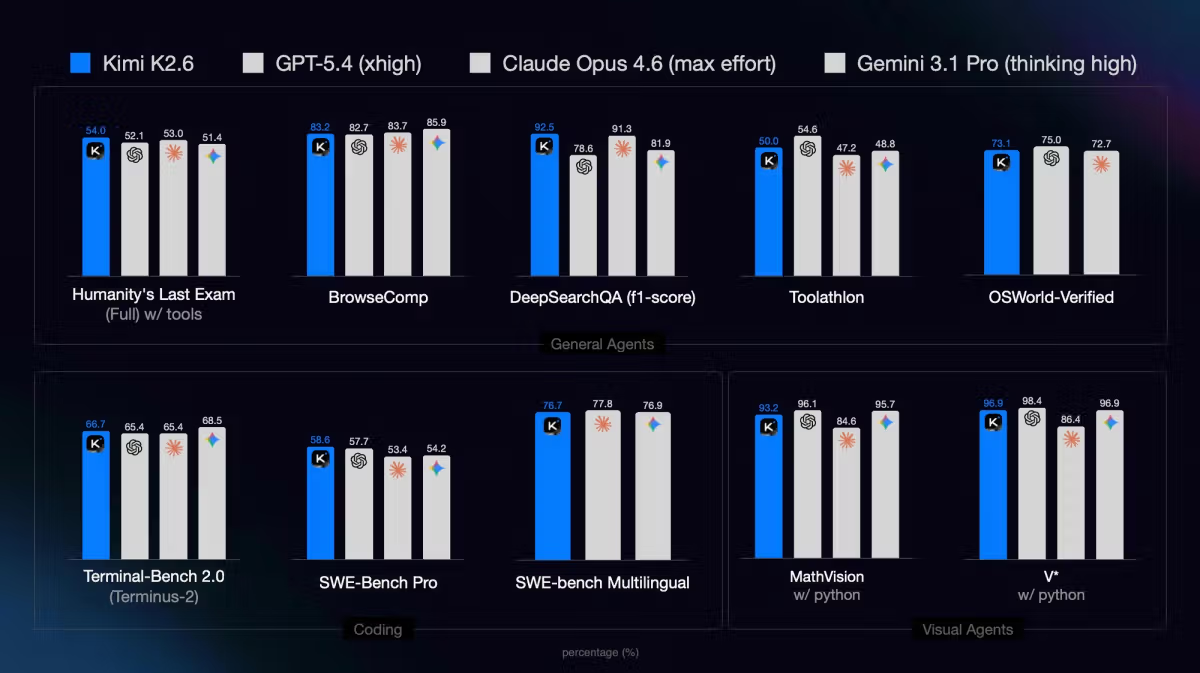
Como o K2.6 se compara ao Claude Opus 4.6 e ao GPT-5.4 em linhas gerais?
Em benchmarks focados em agentes e uso de tools (SWE-Bench Pro, BrowseComp, HLE com tools), o K2.6 é competitivo com ou está à frente de ambos no lançamento, segundo os números auto-reportados da Moonshot. Em tarefas puras de raciocínio single-turn (AIME, GPQA Diamond sem tools), o GPT-5.4 e o Gemini 3.1 Pro ainda lideram. O Claude Opus 4.7 foi lançado na mesma semana que o K2.6 e fica acima do Opus 4.6; comparações diretas K2.6 vs. Opus 4.7 não estão nos benchmarks de lançamento do K2.6. O enquadramento prático: o K2.6 é forte pra tarefas multi-etapa de agente e cargas de trabalho sensíveis a custo; pra raciocínio complexo one-shot, os modelos proprietários atuais ainda estão à frente. Benchmarks independentes vão clarificar o cenário nas próximas semanas.
Conclusão
O K2.6 é um modelo open-weight capaz pra times fazendo trabalho de agente de longo horizonte que precisam de controle de custos, soberania de dados, ou ambos. Sua diferenciação técnica — enxames de 300 agentes, execuções autônomas de 12 horas, multimodal nativo — é real mas especializada. Não vai substituir assistentes de código mais simples pra trabalho de desenvolvimento do dia a dia, e não vai rodar barato em hardware consumer. Se você está rodando ou avaliando pipelines de codificação agêntica em escala, vale testar. Se não está, é um modelo pra acompanhar sem urgência.
