
Acompanhei essa briga se montar por semanas. Em 12 de fevereiro de 2026 — pouco mais de um mês depois do IPO da MiniMax em Hong Kong — eles soltaram o M2.5, e meu Slack acendeu na hora com a mesma mensagem de cinco engenheiros diferentes: "Você viu esses números?"
A coisa que realmente me pegou: o MiniMax M2.5 marca 80,2% no SWE-Bench Verified. O Claude Opus 4.6, lançado uma semana antes, em 5 de fevereiro, tá em 80,8%. Isso é uma diferença de 0,6 ponto percentual entre um modelo que custa em torno de $0,15/M token de input e outro que custa $5/M token de input. Rodei os dois em cenário de produção real na última semana, e esse artigo é o que eu encontrei na prática — não só o que o benchmark diz.
Se você é dev, tech lead ou engineering manager tentando descobrir como rotear tarefa de codificação em 2026, essa é a comparação que você precisa ler.
Pra Que Essa Comparação Serve, na Real — Para de Discutir, Começa a Entregar
Olha, atuo em engenharia de software faz mais de uma década, e nunca vi debate de benchmark torrar mais hora de dev que a discussão "qual modelo é melhor". A pergunta certa não é qual modelo ganha — é qual modelo deve cuidar de qual tarefa no seu stack, e por qual custo.
Essa comparação não é pra fim acadêmico. É montada em torno de um problema de decisão específico: você tá construindo ou rodando um workflow de desenvolvimento assistido por IA, tem acesso aos dois modelos, e precisa de uma estratégia de roteamento.
Os modelos que tô comparando:
- MiniMax M2.5 — Lançado em 12 de fevereiro de 2026. Um modelo Mixture-of-Experts de 230B parâmetros que ativa só 10B parâmetros por forward pass. Treinado em mais de 200.000 ambientes reais de RL, open source no Hugging Face.
- Claude Opus 4.6 — Lançado em 5 de fevereiro de 2026. O modelo mais capaz da Anthropic, com Adaptive Thinking, janela de contexto de 1M token (em beta) e performance líder de mercado no Terminal-Bench 2.0.
Os dois estão prontos pra produção. Os dois são realmente bons. Mas não são intercambiáveis.
Snapshot dos Benchmarks (verificado em fev/2026)
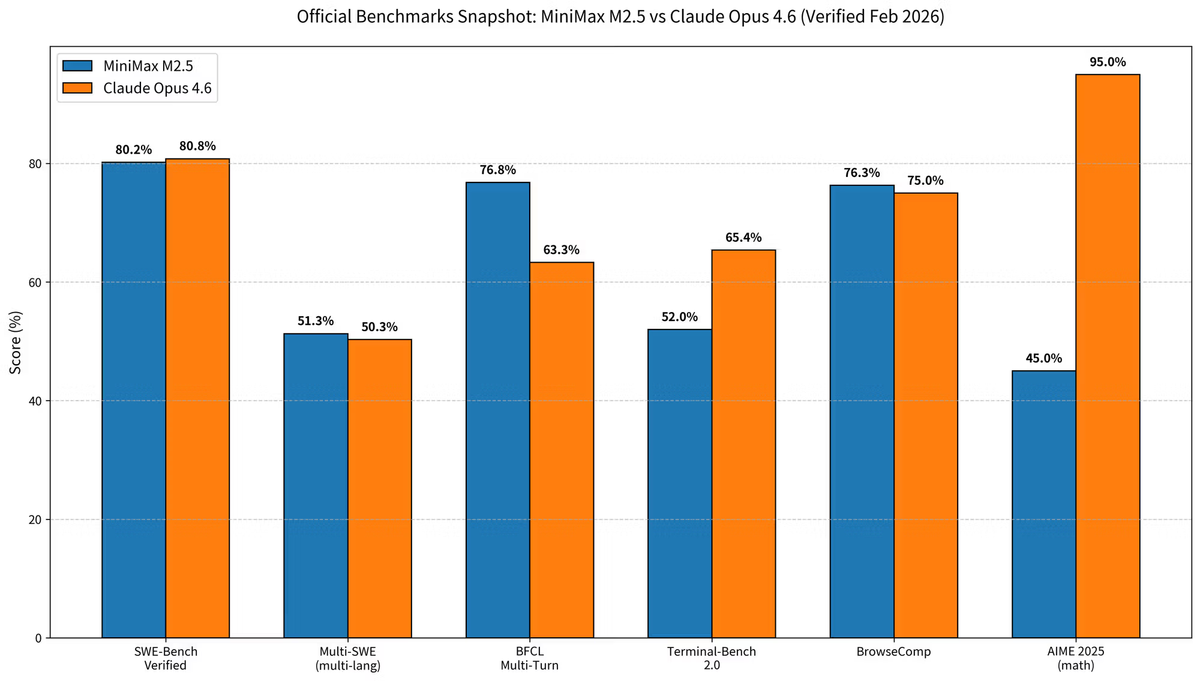
Deixa eu juntar os números de forma limpa. Todos os valores abaixo vêm de release oficial dos modelos e avaliação de terceiro verificada em fevereiro de 2026.
| Benchmark | MiniMax M2.5 | Claude Opus 4.6 | Vantagem |
|---|---|---|---|
| SWE-Bench Verified | 80,20% | 80,80% | Opus 4.6 (+0,6%) |
| Multi-SWE-Bench (multilíngue) | 51,30% | 50,30% | M2.5 (+1%) |
| BFCL Multi-Turn (tool calling) | 76,80% | 63,30% | M2.5 (+13,5%) |
| Terminal-Bench 2.0 | 52% | 65,40% | Opus 4.6 (+13,4%) |
| BrowseComp | 76,30% | ~75% | Praticamente empate |
| AIME 2025 (raciocínio matemático) | 45% | ~95%+ | Opus 4.6 (significativo) |
| HumanEval (Python) | — | 95% | Opus 4.6 |
Fontes: anúncio oficial da MiniMax, página oficial da Anthropic, SWE-bench Results Viewer, Artificial Analysis.
SWE-Bench + O Que o Gap de 0,6% Significa de Verdade em Produção
Aqui eu preciso pisar no freio na manchete. O SWE-Bench Verified testa resolução autônoma de issue real do GitHub em repositório Python — é o melhor benchmark único que a gente tem pra agente de codificação. E sim, 80,2% vs 80,8% é estatisticamente próximo.
Mas o tipo de tarefa que cada modelo cuida melhor importa muito. Os gaps que observei na prática foram maiores do que 0,6% sugere:
- Multi-SWE-Bench testa projeto multilíngue com vários arquivos — o M2.5 na real lidera aqui, com 51,3% vs 50,3%. Pra trabalho em Go, Rust, TypeScript e Java, esse é o benchmark mais relevante.
- BFCL Multi-Turn é o que pulou pra mim. Uma vantagem de 13,5 ponto percentual pro M2.5 em tool calling multi-turn sustentado significa que ele perde contexto bem menos em loop agêntico longo. Num workflow multi-agente da Verdent onde você roda um agent de refactor por mais de 40 tool calls, essa diferença é enorme.
- Terminal-Bench 2.0 conta a história oposta. O 65,4% do Opus 4.6 vs 52% do M2.5 reflete um gap real em operação autônoma de terminal, debug em vários passos e tarefa em nível de SO. Se seu agente precisa navegar filesystem, rodar suíte de teste de forma iterativa ou debugar no shell, o Opus 4.6 justifica o preço premium.
Resumindo: os 0,6% no SWE-Bench escondem um perfil de performance bifurcado. M2.5 domina loop de tool calling; Opus 4.6 domina terminal e tarefa pesada de raciocínio.
Resultados do Nosso Teste por Tarefa
Rodei os dois modelos por um conjunto de tarefa real ao longo de 7 dias — não problema de brinquedo, mas trabalho representativo de tipo de projeto real: refactor de uma API multi-serviço, suíte de validação de business logic, trabalho de nicho em Rust e migração de uma component library de TypeScript.
M2.5 Vence — Refactor Multi-Arquivo, Loop de Tool Calling Sustentado
Tarefa: migrar uma API Express.js de 14 arquivos de callbacks pra async/await, com atualização completa da suíte de teste
O comportamento nativo de "spec-writing" do M2.5 — onde ele planeja a arquitetura antes de tocar no código — fez diferença real aqui. Antes de escrever uma linha, ele produziu um plano de migração estruturado cobrindo dependência entre arquivo, padrão de callback compartilhado e área de impacto nos testes. O output final precisou de cerca de 20% menos revisão manual que a tentativa equivalente do Opus 4.6.
A vantagem do BFCL multi-turn apareceu clara no loop de tool calling. O M2.5 manteve contexto preciso ao longo de 47 tool calls consecutivas. O Opus 4.6 mostrou drift de contexto na chamada 28, exigindo uma injeção manual pra voltar pro trilho.
# Exemplo: padrão de tool calling paralelo do M2.5 no Verdent Agent Mode
# O M2.5 rodou essas três tool calls em paralelo sem perder contexto:
# 1. Lê src/routes/users.js → analisa cadeia de callback
# 2. Lê src/middleware/auth.js → identifica dependência de callback
# 3. Lê tests/users.test.js → mapeia cobertura de teste pros callbacks
# Total de rodadas necessárias: 6
# Equivalente Opus 4.6: 9 rodadas (drift de contexto na rodada 5)Outras vitórias do M2.5 no nosso teste:
- Refactor multilíngue (TypeScript + Go na mesma sessão)
- Sessão longa do Verdent Agent (mais de 30 tool calls)
- Implementação de trait em Rust com lifetime complexo (vantagem do treinamento multilíngue)
- Processamento em batch otimizado em custo pra tarefa de code review
Opus 4.6 Vence — Business Logic Capciosa, Edge Case de Linguagem de Nicho
Tarefa: implementar um motor de arredondamento multi-moeda com regra de compliance regulatório pra 6 jurisdições
Esse é exatamente o tipo de tarefa onde o gap do Opus 4.6 em raciocínio e precisão de planejamento aparece. A business logic era ambígua em três pontos onde jurisdições diferentes se contradizem. O Opus 4.6 sinalizou as três contradições de forma proativa e pediu esclarecimento antes de seguir. O M2.5 fez assumption em duas — uma estava certa, a outra não.
Pra tarefa que toca lógica regulatória, cálculo financeiro ou exige raciocínio profundo de domínio, o Adaptive Thinking e o score mais alto no AIME do Opus 4.6 representam valor real em produção.
Outras vitórias do Opus 4.6 no nosso teste:
- Sessão de debug autônomo que exigia operação no shell (o gap do Terminal-Bench é real)
- Edge case obscuro de linguagem no módulo typing do Python, metaprogramação de template em C++
- Tarefa que exige mais de 200K token de contexto com coerência total
- Design de arquitetura nova onde o raciocínio por primeiros princípios importa
Realidade do Custo — Como Sua Fatura Mensal Fica de Verdade
Vou ser direto sobre os números, porque é aqui que a decisão geralmente termina.
| MiniMax M2.5 Standard | MiniMax M2.5 Lightning | Claude Opus 4.6 Standard | |
|---|---|---|---|
| Input (por 1M token) | $0,15 | $0,30 | $5,00 |
| Output (por 1M token) | $1,20 | $2,40 | $25,00 |
| Velocidade | 50 TPS | 100 TPS | ~40 TPS (est.) |
| Custo médio por tarefa SWE-Bench | ~$0,15 | ~$0,30 | ~$3,00 |
Pricing do anúncio oficial da MiniMax e da página de pricing da API da Anthropic, fevereiro de 2026.
A conta que importa pra time rodando agente de codificação em escala:
Cenário: 100 tarefas de code review/dia, ~1M token de output no total
- M2.5 Standard: ~$1,20/dia → $36/mês
- Opus 4.6 Standard: ~$25,00/dia → $750/mês
Isso é 20× de diferença de custo em token de output. Pra um time de engenharia de porte médio rodando agente diariamente, rotear até 70% das tarefas pro M2.5 gera economia relevante com qualidade de output praticamente equivalente na maioria dos tipos de tarefa.
Duas alavancas de custo do Opus 4.6 que vale conhecer: a Batch API dá 50% de desconto, e o prompt caching derruba o input pra $0,50/M token (90% de economia). Se você tem system prompt repetido ou workflow pesado em documento, empilha as duas. Mas mesmo com cache, o M2.5 continua significativamente mais barato pra workload agêntico pesado em output.
Matriz de Decisão + Como a Verdent Roteia em Produção
Depois de uma semana de teste em mundo real, esse é o framework de roteamento que eu implementaria de verdade. Na Verdent, a gente roteia entre modelos com base em tipo de tarefa, nível de risco e tolerância a custo — não em assumption de "modelo único melhor".
| Tipo de tarefa | Modelo recomendado | Motivo |
|---|---|---|
| Refactor multi-arquivo (3+ arquivos) | M2.5 | Comportamento de spec-writing, vantagem no Multi-SWE-Bench, custo menor |
| Loop agêntico longo (25+ tool calls) | M2.5 | Liderança no BFCL multi-turn (76,8% vs 63,3%) |
| Projeto multilíngue (Go/Rust/Java) | M2.5 | Treinado em 10+ linguagens, #1 no Multi-SWE-Bench |
| Code review em batch de alto volume | M2.5 | Eficiência de custo; output 20× mais barato |
| Tarefa autônoma de terminal/shell | Opus 4.6 | Terminal-Bench 2.0: 65,4% vs 52% |
| Business logic complexa / compliance | Opus 4.6 | Profundidade de raciocínio, Adaptive Thinking |
| Codebase grande com 200K+ token de contexto | Opus 4.6 | Janela de 1M token + coerência |
| Design de arquitetura nova | Opus 4.6 | Vantagem em raciocínio por primeiros princípios |
| Script Python rápido / protótipo | Qualquer um | Paridade de performance no HumanEval |
| Código de produção de alto risco e baixo volume | Opus 4.6 | Vale o premium pelo gap de raciocínio |
A lógica de roteamento em português claro:
Usa o M2.5 como modelo padrão de agent pra trabalho de codificação iterativo, pesado em tool e multi-arquivo. Roteia pro Opus 4.6 quando a tarefa exige raciocínio profundo, navegação autônoma de terminal, ou quando um erro tem consequência significativa lá na frente.
Isso não é uma hierarquia permanente — é um trade-off custo-risco. Os 0,6% de gap no SWE-Bench não definem qual modelo é "melhor". Eles te dizem que os dois estão próximos o suficiente pra que tipo de tarefa e custo dirijam o roteamento, não prestígio do modelo.
Uma nota rápida sobre a implementação da Verdent: na arquitetura multi-agente da Verdent, o agent do Plan Mode decide o roteamento com base na classificação da tarefa. O isolamento via Git Worktree faz cada agente — seja rodando M2.5 ou Opus 4.6 — trabalhar em ambiente sandboxed, então decisão de roteamento não cria conflito de código. Se você tá implementando algo parecido, essa camada de isolamento importa mais que a escolha de modelo pra manter a segurança do código.
FAQ
P: O MiniMax M2.5 é open source de verdade? R: Sim — a MiniMax liberou os weights publicamente. O model card do MiniMax M2.5 e os weights estão disponíveis no Hugging Face, com suporte a vLLM e SGLang pra self-hosting. Vale notar que com 230B de parâmetro total, o self-hosting exige hardware sério mesmo com a pegada de 10B parâmetro ativo do MoE.
P: Qual modelo eu uso pra projeto greenfield, do zero? R: Pra design de sistema 0-pra-1, eu iria de Opus 4.6. A profundidade de raciocínio e o Adaptive Thinking dão vantagem quando a arquitetura ainda não tá definida. Quando você tá em desenvolvimento de feature 1-pra-N com codebase já estabelecido, o M2.5 fica competitivo ou melhor.
P: O gap do BFCL multi-turn importa pra mim? R: Importa se seu agente roda mais de ~20 tool calls consecutivas numa sessão. Abaixo desse limiar, os dois modelos mantêm contexto bem. Acima dele — principalmente em refactor que atravessa muitos arquivos — os 76,8% vs 63,3% do M2.5 no Berkeley Function Calling Leaderboard multi-turn benchmark se traduzem em menos falha por drift de contexto.
P: E o Claude Sonnet 4.6 como alternativa? R: Vale a menção. O Sonnet 4.6 marca 79,6% no SWE-Bench Verified a $3/$15 por milhão de token — mais perto do preço do M2.5 e quase no score do Opus 4.6. Pra stack nativo Anthropic, o Sonnet 4.6 é o meio-termo pragmático.
P: Como os 37% de conclusão de tarefa mais rápida do M2.5 afetam o custo na real? R: Boa pergunta. Como o M2.5 também consome um pouco menos de token por tarefa (3,52M vs média de 3,72M do M2.1 no SWE-Bench), a vantagem de custo se acumula — você paga menos por token e usa menos token por tarefa. Em operação contínua, a MiniMax precifica o M2.5 Lightning a $1/hora a 100 TPS. É um jeito incomum de pensar pricing de modelo, mas útil pra sessão de agent longa.
Qual é a Linha de Fundo?
Para de debater modelo. Começa a rotear tarefa.
A decisão MiniMax M2.5 vs Claude Opus 4.6 não é binária. É um problema de roteamento: M2.5 pra trabalho iterativo, multi-arquivo, pesado em tool, em escala; Opus 4.6 pra tarefa que exige raciocínio intenso, pesada em terminal ou de alto risco, onde o premium de custo te compra precisão real.
Usa a matriz de decisão acima pra rotear suas tarefas de codificação por tipo de tarefa, nível de risco e custo. Se você tá rodando um stack multi-agente estilo Verdent, implementa o roteamento de modelo na camada de plan, pra que agente individual não herde uma assumption de "modelo único pra tudo". Essa decisão arquitetural sozinha faz mais pela qualidade de output do seu time e pelo custo de infra do que qualquer escolha de modelo único.
Fontes de dado: release oficial da MiniMax (12 fev 2026), página oficial do modelo da Anthropic (5 fev 2026), docs de pricing da API Anthropic (fev 2026), SWE-bench Results Viewer (17 fev 2026), dado de benchmark da Artificial Analysis, análise do M2.5 no HuggingFace (fev 2026).
Artigos relacionados
Claude AI: Acesso Gratuito 2026
Windsurf: Preços e Planos 2026
