
Meta Descrição: Nemotron 3 Super ou Qwen 3 para seus agentes de código? Comparamos arquitetura, benchmarks reais, custos de deployment e casos de uso — para você escolher com base no seu stack, não no leaderboard.
Uma pergunta que continua aparecendo nos canais de engenharia: "Devemos rodar Nemotron 3 Super ou algo da família Qwen nos nossos agentes de código?" Faz sentido — os dois são open-weight, os dois competem em benchmarks de coding, e os dois têm feito barulho nos últimos meses. A resposta não é óbvia. Vou desmembrar.
Nota de versão: Esta comparação cobre Nemotron 3 Super 120B-A12B (lançado em 11 de março de 2026) contra Qwen3-Coder-Next 80B-A3B (lançado em 3 de fevereiro de 2026) e Qwen3.5-122B-A10B (o Qwen MoE de tamanho comparável). Todos os dados de benchmark vêm de relatórios técnicos oficiais e avaliações independentes publicadas a partir de fevereiro de 2026.
Para o que cada modelo é otimizado
Nemotron para workflows agênticos

O Nemotron 3 Super foi construído pra um trabalho específico: ser o cérebro de planejamento e orquestração num stack de coding multi-agente. O posicionamento da NVIDIA é explícito — quando um pipeline precisa decompor tarefas complexas, manter contexto de codebase completo e rotear trabalho pra múltiplos agentes worker, é aí que o Super se encaixa. Não é um modelo conversacional de propósito geral, e a NVIDIA não finge que é.
O relatório técnico da NVIDIA (11 de março de 2026) descreve o pipeline de pós-treinamento em três fases sequenciais: pré-treinamento em 25 trilhões de tokens, SFT em tipos de tarefas agênticas, e reinforcement learning contra resultados verificáveis em 15 ambientes agênticos distintos — incluindo engenharia de software, cibersegurança e análise financeira. A fase de RL é o que produz o raciocínio multi-etapa sólido e o sequenciamento de tool calls do modelo.
Onde o Nemotron 3 Super não é otimizado: amplitude de conhecimento geral e qualidade conversacional. Seu score de 73,88% no Arena-Hard-V2 fica atrás dos 90,26% do GPT-OSS-120B, e seu GPQA de 79,23% fica abaixo dos 86,60% do Qwen3.5-122B. Se você precisa de um modelo pra Q&A científico amplo ou geração de chat de alta qualidade, essa não é a escolha certa.
Qwen para força geral em coding
A família Qwen adota uma abordagem mais ampla. O Qwen3-Coder-Next foi treinado em 800K tarefas verificáveis e executáveis em ambientes agênticos, com reinforcement learning pra raciocínio de longo horizonte, sequenciamento de ferramentas, execução de testes e recuperação de execuções com falha. Mas também performa de forma competitiva em benchmarks de conhecimento geral onde o Nemotron 3 Super cede terreno — MMLU-Pro em 86,70% vs. 83,73% do Nemotron, GPQA em 86,60% vs. 79,23%.
O Qwen3-30B-A3B marca 69,6% no SWE-Bench Verified e 91,0 no ArenaHard, se posicionando competitivamente tanto em coding quanto em tarefas conversacionais. O Qwen3.5-122B-A10B maior vai além: lidera o Nemotron 3 Super no SWE-Bench Verified (66,40% vs. 60,47%) e em raciocínio científico, mantendo um perfil de eficiência MoE comparável.
Onde o Qwen não é otimizado: retenção de contexto longo em comprimentos extremos. O Qwen3.5-122B tem teto de 128K de contexto nativo, e embora o Qwen3-Coder-Next suporte 256K, nenhum dos dois chega perto da janela de 1M tokens do Nemotron 3 Super. Para pipelines que precisam carregar codebases grandes inteiras num único contexto sem retrieval, essa diferença importa.
Diferenças arquiteturais que importam
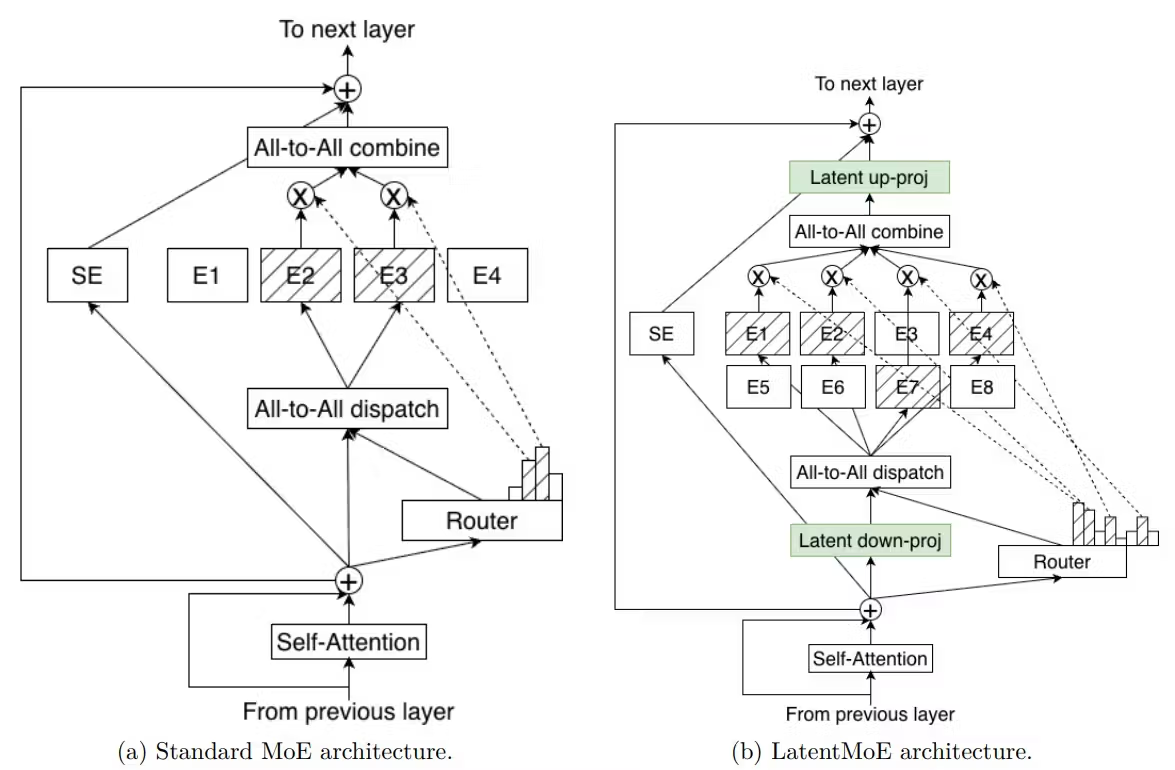
Parâmetros ativos e eficiência
Os dois modelos usam Mixture-of-Experts pra manter custos de inferência baixos, mas os ratios de eficiência são significativamente diferentes:
| Nemotron 3 Super | Qwen3-Coder-Next | Qwen3.5-122B | |
|---|---|---|---|
| Total de parâmetros | 120B | 80B | 122B |
| Parâmetros ativos | 12B (10%) | 3B (3,75%) | 10B (~8,2%) |
| Arquitetura | Hybrid Mamba-2 + Transformer + LatentMoE | Hybrid GatedDeltaNet + Gated Attention + MoE | Dense Transformer MoE |
| Janela de contexto | 1M tokens (nativo) | 256K tokens | 128K tokens |
| Licença | NVIDIA Open Model License | Apache 2.0 | Apache 2.0 |
O Nemotron 3 Super ativa 12B parâmetros por forward pass. O Qwen3-Coder-Next ativa apenas 3B — o que o torna dramaticamente mais barato pra servir por token, executável em hardware consumer (MacBook 64GB, RTX 5090), e mais adequado pra deployments concorrentes de alto volume em infraestrutura modesta.
O MoE ultra-esparso do Qwen3-Coder-Next ativa 10 de 512 experts por token, permitindo entregar capacidades de raciocínio que rivalizam com sistemas muito maiores mantendo os baixos custos de deployment e o alto throughput de um modelo local leve.
As três inovações arquiteturais do Nemotron 3 Super se empilham de forma diferente. O LatentMoE comprime tokens de um espaço oculto de dimensão 4096 pra 1024 antes do roteamento de experts — uma compressão de 4× que permite 512 experts totais com 22 ativos por token ao mesmo custo computacional de um MoE padrão com menos experts. As camadas Mamba-2 lidam com processamento de sequência em complexidade linear. O Multi-Token Prediction oferece speculative decoding integrado.
O resultado prático: o Nemotron 3 Super é otimizado pra eficiência de serving em alto volume de tokens de saída com cargas de contexto pesadas. O Qwen3-Coder-Next é otimizado pra custo-por-tarefa em workloads concorrentes de alta frequência e contexto mais curto.
Implicações de contexto e throughput
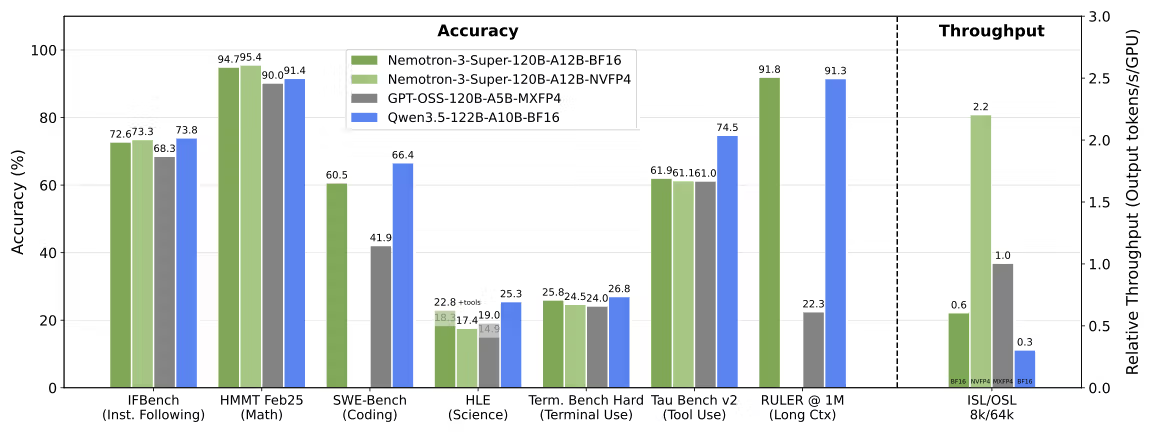
O Nemotron 3 Super alcança até 2,2× e 7,5× maior throughput de inferência que GPT-OSS-120B e Qwen3.5-122B respectivamente, em configurações de 8K input / 16K output. Essa vantagem de throughput é significativa pra sistemas de orquestração multi-agente onde muitos agentes rodam em paralelo.
Em 1 milhão de tokens, o Nemotron 3 Super marca 91,75% no RULER, enquanto o GPT-OSS-120B cai pra 22,30%. O limite rígido de 128K do Qwen3.5-122B simplesmente o impede de competir em tarefas de retrieval com um milhão de tokens. O Qwen3-Coder-Next chega a 256K nativamente com retenção razoável, mas o 1M só está disponível via extrapolação por interpolação posicional — não é o mesmo que treinamento nativo.
Uma ressalva prática: a configuração de contexto padrão do Nemotron 3 Super é 256K tokens por limitações de VRAM, com 1M acessível via flag explícita. Então os dois modelos operam a 256K por padrão na maioria dos ambientes de API gerenciados; a vantagem de 1M requer planejamento deliberado de infraestrutura.
Comparação de coding e uso de ferramentas
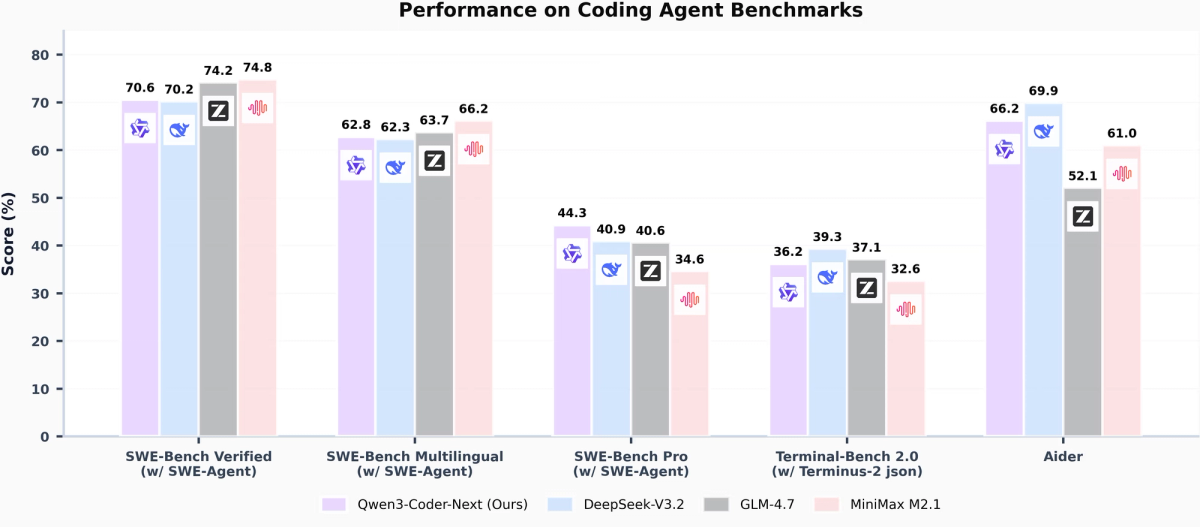
Todos os scores abaixo usam os scaffolds e datas especificados. Não compare números executados em harnesses diferentes — scores do SWE-Bench Verified variam significativamente com base no scaffold do agente utilizado.
SWE-Bench Verified — scaffold SWE-Agent (dados de março de 2026)
| Modelo | SWE-Bench Verified | SWE-Bench Multilingual | SWE-Bench Pro |
|---|---|---|---|
| Qwen3-Coder-Next 80B-A3B | 70,60% | 62,80% | 44,30% |
| Qwen3.5-122B-A10B | 66,40% | — | — |
| Nemotron 3 Super 120B-A12B | 60,47% (OpenHands) | 45,78% | — |
| DeepSeek-V3.2 | 70,20% | 62,30% | 40,90% |
| GLM-4.7 | 74,20% | 63,70% | 40,60% |
Fontes: relatório técnico do Qwen3-Coder-Next (fev 2026); relatório técnico da NVIDIA (mar 2026); VentureBeat (4 fev 2026). Nota: os números do Nemotron usam o harness OpenHands; os números do Qwen usam o scaffold SWE-Agent. A comparação numérica direta é ilustrativa, não definitiva.
Ressalva importante sobre harnesses de benchmark: o 60,47% do Nemotron 3 Super usa o scaffold de agente OpenHands. Os 70,6% do Qwen3-Coder-Next usam SWE-Agent. Esses dois scaffolds produzem scores sistematicamente diferentes no mesmo modelo — tooling diferente, prompting diferente, estratégias pass@k diferentes. Os números acima não são diretamente comparáveis em sentido estrito. Ambos os relatórios técnicos oficiais usam harnesses diferentes, então trate o delta entre modelos com ceticismo apropriado.
O que os dados de fato sustentam com clareza: com 60,47% no SWE-Bench Verified, o Nemotron 3 Super fica cerca de 6 pontos atrás do Qwen3.5, mas entrega 2,2× o throughput — pra sistemas multi-agente rodando muitos agentes de forma concorrente, esse trade-off de throughput por acurácia importa.
LiveCodeBench (independente, março de 2026)
No LiveCodeBench — um benchmark independente que testa problemas de coding atuais e não contaminados — o Nemotron 3 Super marca 81,19% contra 78,93% do Qwen3.5-122B. Essa é uma categoria onde o Nemotron lidera o Qwen no tier de tamanho comparável, usando um benchmark menos suscetível à contaminação de dados de treinamento do que avaliações de coding mais antigas.
Tool calling
O Qwen3-Coder-Next é explicitamente ajustado pra tool calling e se integra com ambientes de IDE e CLI como Qwen-Code, Claude Code, Cline e outros frontends de agente. Não suporta modo de thinking (blocos <think>) — as respostas são geradas diretamente sem etapas de raciocínio visíveis.
O Nemotron 3 Super suporta modos com e sem raciocínio. O score de GPQA "com ferramentas" (82,70%) sobe 3,5 pontos em relação à variante "sem ferramentas" — evidência de que o treinamento de tool calling melhora diretamente o raciocínio fundamentado, não apenas a execução de tarefas.
Os dois modelos lidam com as 43 linguagens de programação necessárias pra workflows agênticos multilíngues. O score de 61,2% do Qwen3-Coder-Next no SecCodeBench (reparação de vulnerabilidades de código) supera o Claude Opus 4.5 em 52,5% — um diferencial relevante se geração de código com consciência de segurança faz parte do seu stack.
Diferenças de deployment
NIM vs. rotas comuns de modelo open
Esses dois modelos têm ecossistemas de deployment significativamente diferentes. O caminho até a produção importa tanto quanto os scores de benchmark.
Opções de deployment do Nemotron 3 Super (até 13 de março de 2026):
| NVIDIA NIM microservice | Container de inferência empacotado; suporte a vLLM, TensorRT-LLM, SGLang |
|---|---|
| build.nvidia.com | Acesso à API com trial gratuito |
| Google Cloud Vertex AI, OCI, CoreWeave, Together AI | APIs de cloud gerenciadas |
| Hugging Face | Checkpoints BF16, FP8, NVFP4 |
| Self-host | Mínimo 8× H100-80GB (BF16); 4× H100 viável em FP8 |
O empacotamento NVIDIA NIM é uma vantagem real pra times enterprise: containers de inferência padronizados, deployments em cloud com SLA, e um caminho claro pra on-prem via NIM em infraestrutura privada. O trade-off é que a licença é a NVIDIA Open Model License, não Apache 2.0 — é permissiva para uso comercial, mas inclui uma cláusula de rescisão de patente se você litigar contra a NVIDIA.
Opções de deployment do Qwen3-Coder-Next (até 13 de março de 2026):
| Rota | Detalhes |
|---|---|
| Hugging Face | 4 variantes de peso: BF16, GGUF Q4/Q8, FP8 |
| Together AI | API de produção, variante FP8 |
| Kaggle | Hospedagem de modelo com inferência gratuita |
| Local (Ollama, LMStudio, llama.cpp) | Roda em MacBook 64GB, RTX 5090, RX 7900 XTX |
| Licença | Apache 2.0 — uso comercial totalmente permissivo |
O Qwen3-Coder-Next alcança performance comparável ao Claude Sonnet 4.5 em benchmarks de coding usando apenas 3B parâmetros ativos, tornando viável rodar em hardware consumer de alta performance. Pra um dev que quer rodar um agente de coding poderoso completamente local — sem custos de API, controle total dos dados — o Qwen3-Coder-Next é a opção mais viável nesse tier em março de 2026. O Nemotron 3 Super exige no mínimo 8× H100-80GB pra self-host; essa é uma barreira real pra devs individuais ou times pequenos.
Comparativo de preços de API (março de 2026, preços spot DeepInfra / Together AI):
| Modelo | Input (por 1M tokens) | Output (por 1M tokens) |
|---|---|---|
| Nemotron 3 Super | ~$0,10–$0,30 | ~$0,50–$0,80 |
| Qwen3-Coder-Next | ~$0,06–$0,18 | ~$0,20–$0,50 |
Preços variam por provedor e vão mudar. Verifique as páginas dos provedores diretamente antes de orçar.
Qual escolher
Escolha o Nemotron 3 Super se…
- Você está construindo um sistema de orquestração multi-agente onde um modelo precisa planejar, decompor e rotear tarefas complexas para agentes worker — esse é o target de design explícito.
- Você precisa de contexto de 1M tokens que de fato aguenta sob benchmarks de retrieval (91,75% no RULER@1M), não apenas contexto que tecnicamente aceita 1M tokens.
- Você está rodando workloads de agente concorrentes de alto volume em infraestrutura NVIDIA Blackwell e a vantagem de throughput de 2,2×+ reduz materialmente o custo de serving.
- Seu time precisa de suporte enterprise de deployment — empacotamento NIM, SLAs de cloud, e um caminho claro pra deployment on-prem privado via infraestrutura NVIDIA.
- Código multilíngue é prioridade: 45,78% no SWE-Bench Multilingual contra 30,80% do GPT-OSS-120B é um diferencial real pra codebases não inglesas.
- Você quer transparência total de treinamento: a NVIDIA disponibilizou pesos, 10 trilhões de tokens de pré-treinamento, 40 milhões de amostras de pós-treinamento e 21 configurações de ambiente de RL.
Não escolha se você precisa de liberdade de licença Apache 2.0, profundidade de raciocínio científico amplo, deployabilidade em hardware consumer, ou qualidade conversacional sólida ao lado de capacidade de coding.
Escolha o Qwen 3 se…
- Você quer o score bruto mais alto no SWE-Bench Verified na classe open-weight no orçamento de parâmetros comparável — o Qwen3-Coder-Next em 70,6% (SWE-Agent) lidera esse tier atualmente.
- Você precisa rodar completamente local em hardware consumer — o Qwen3-Coder-Next num MacBook 64GB ou RTX 5090 é um caminho de deployment real, não teórico.
- Licença Apache 2.0 é um requisito fixo — sem cláusulas de patente, sem requisitos de atribuição além dos termos da licença, máxima flexibilidade comercial.
- Você está rodando tarefas de contexto curto de alta frequência onde 3B parâmetros ativos significa custo dramaticamente menor por tarefa em escala.
- Geração de código com consciência de segurança importa: 61,2% no SecCodeBench supera modelos fechados maiores nessa categoria.
- Você precisa de inteligência geral mais ampla ao lado de coding — o Qwen3.5-122B lidera em MMLU-Pro, GPQA e ArenaHard pra times que precisam de um modelo pra múltiplos casos de uso além de orquestração pura de agentes.
Não escolha se seu pipeline depende de contexto nativo de 1M tokens com retenção validada, você precisa de empacotamento enterprise NVIDIA NIM, ou está rodando workloads de orquestração concorrentes de alto output em hardware Blackwell onde a eficiência NVFP4 se torna decisiva.
Conclusão: esses dois não estão competindo pelo mesmo trabalho. O Nemotron 3 Super foi construído pra ser o cérebro de um sistema multi-agente rodando em infraestrutura NVIDIA enterprise. O Qwen3-Coder-Next foi construído pra ser um agente de coding com custo-efetivo, deployável localmente, com licença Apache e números brutos de benchmark sólidos. A escolha certa depende quase inteiramente das suas restrições de deployment e arquitetura de stack — não apenas de qual número é maior num leaderboard.
Se você ainda está decidindo, o caminho mais rápido é rodar os dois contra seus workloads reais. Os dois oferecem acesso à API em tier gratuito. Use.
