
Claude Opus 4.7 chegou em 16 de abril de 2026 pelo mesmo preço do 4.6. Os benchmarks de codificação melhoraram bastante. O tokenizer também mudou — e essa diferença entre "mesmo preço" e "mesmo custo" é a decisão que a maioria dos times precisa quantificar antes de migrar. Essa comparação cobre os números que você precisa, de onde eles vieram, e quando o upgrade não faz sentido.
Veredito Rápido — Quem Deve Atualizar e Quem Deve Esperar

Atualiza se:
- Você roda agentes de codificação autônomos em tarefa multi-arquivo complexa — o SWE-bench Verified subiu 6,8 pontos e o CursorBench subiu 12 pontos
- Seu workflow envolve screenshot, diagrama ou parsing de UI — a resolução de visão triplicou, o XBOW Visual Acuity foi de 54,5% pra 98,5%
- Você orquestra loop agêntico de vários passos — os erros de tool caíram pra um terço dos níveis do Opus 4.6 (dado da Notion AI, fonte abaixo), e o novo nível de esforço
xhighte dá controle mais fino - Você tá no Opus 4.6 pra trabalho agêntico de terminal/linha de comando — o Terminal-Bench 2.0 melhorou de 65,4% pra 69,4% (mas o GPT-5.4 ainda lidera com 75,1%)
Fica no 4.6 se:
- Seus prompts foram afinados pra interpretação solta do 4.6 — o 4.7 segue instrução de forma mais literal, o que quebra alguns prompts que dependiam do modelo inferir intenção não declarada
- Você ainda não mediu o impacto do tokenizer no seu tráfego real — o tokenizer novo gera até 35% mais token pro mesmo input; pra produto multilíngue ou com conteúdo estruturado, isso é aumento real de custo
- Seu uso principal é busca agêntica na web — o BrowseComp caiu de 83,7% pra 79,3% no 4.7; o GPT-5.4 Pro lidera com 89,3%
- Você tem um deploy do 4.6 já aprovado em compliance — as novas salvaguardas de cibersegurança no 4.7 podem gerar refusal inesperada; valida antes de trocar
Tabela de Comparação dos Benchmarks
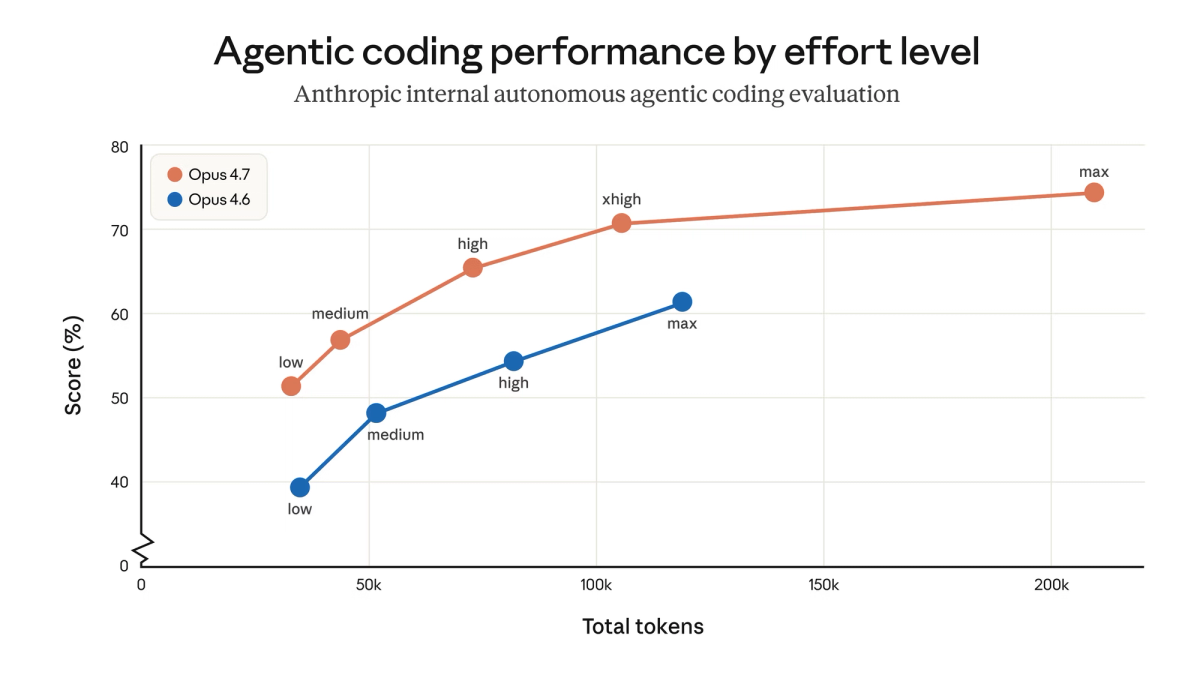
Todos os números reportados pela Anthropic, salvo quando indicado. Scores do Opus 4.6 vêm do release da Anthropic em 5 de fevereiro de 2026; scores do Opus 4.7, do release em 16 de abril de 2026.
| Benchmark | Opus 4.6 | Opus 4.7 | Δ | GPT-5.4 | Notas |
|---|---|---|---|---|---|
| SWE-bench Verified | 80,80% | 87,60% | +6,8pp | — | Conduzido pela Anthropic; com filtros antimemorização |
| SWE-bench Pro | 53,40% | 64,30% | +10,9pp | 57,70% | Tarefas reais multilinguagem; benchmark da Scale AI |
| CursorBench | 58% | 70% | +12pp | — | Avaliação de partner; fonte: CEO da Cursor (ver abaixo) |
| GPQA Diamond | 91,30% | 94,20% | +2,9pp | 94,40% | Praticamente saturado; diferença dentro do ruído |
| Terminal-Bench 2.0 | 65,40% | 69,40% | +4,0pp | 75,10% | 4.7 melhora vs 4.6; GPT-5.4 lidera no geral |
| BrowseComp | 83,70% | 79,30% | −4,4pp | 89,30% | Regressão vs 4.6; GPT-5.4 e Gemini 3.1 Pro lideram |
| XBOW Visual Acuity | 54,50% | 98,50% | +44pp | — | Benchmark de screenshot pra computer-use; eval do partner XBOW |
| MCP-Atlas | 73,90% | 77,30% | +3,4pp | 68,10% | Uso de tool em escala; conduzido pela Anthropic |
| Finance Agent v1.1 | 59,70% | 64,40% | +4,7pp | — | Conduzido pela Anthropic |
Sobre dados de partner: os números do CursorBench, Rakuten-SWE-Bench e XBOW Visual Acuity são avaliações de partner citadas na página oficial de release da Anthropic em anthropic.com/news/claude-opus-4-7 e anthropic.com/claude/opus. Não são avaliações replicadas independentemente pela Anthropic — são benchmarks rodados pelos partners em test set proprietário. Trata como sinal direcional forte vindo de uso em produção, não comparação controlada.
Sobre o Terminal-Bench: o 4.7 melhorou 4,0 pontos vs 4.6. O benchmark não é regressão pro Opus — o gap competitivo é contra o GPT-5.4, não contra a versão anterior.
As Diferenças de Comportamento que Aparecem em Produção
Loop de auto-verificação — verifica o próprio trabalho antes de reportar pronto
O Opus 4.7 escreve passos de verificação proativamente antes de declarar tarefa concluída. Em codificação agêntica, isso significa que o modelo escreve teste, roda, e corrige falha internamente antes de subir o resultado. O time da Vercel observou que ele "faz prova em código de sistema antes de começar o trabalho, comportamento novo que não víamos em modelo Claude anterior." Isso reduz a frequência de saída confiantemente errada chegando até a camada do orquestrador.
Instrução é seguida com mais rigor — bullet list é tratada como requisito hard
O Opus 4.6 interpretava instrução de forma solta e às vezes inferia intenção não declarada. O Opus 4.7 segue a instrução com precisão. O guia de migração da Anthropic deixa explícito: "Opus 4.7 respeita os níveis de esforço de forma estrita, especialmente no extremo baixo. Em low e medium, o modelo limita o trabalho ao que foi pedido em vez de ir além."
Na prática: prompt com bullet list que antes funcionava porque o modelo generalizava a partir de instrução parcial agora pode produzir saída mais limitada. Testa qualquer prompt que dependia da interpretação generosa do 4.6 antes de migrar.
Erros de tool reduzidos pra um terço
Sarah Sachs, AI Lead da Notion AI, citada no release oficial da Anthropic: "mais 14% sobre o Opus 4.6 com menos token e um terço dos erros de tool." Isso é benchmark interno de um partner único nos padrões específicos de orquestração deles, não eval cruzado controlado entre modelos. Dito isso, vários outros partners reportaram melhoria parecida em confiabilidade — a Factory Droids notou "menos erros de tool e follow-through mais confiável nos passos de validação," e a Genspark reportou melhoria relevante em "loop resistance" (taxa do modelo rodar indefinidamente em uma query).
3× mais tarefas de produção resolvidas
Rakuten, citada no release oficial da Anthropic: "No Rakuten-SWE-Bench, o Claude Opus 4.7 resolve 3x mais tarefas de produção que o Opus 4.6, com ganho de dois dígitos em Code Quality e Test Quality." Isso é o benchmark proprietário da Rakuten no codebase interno deles — não SWE-bench padrão. A magnitude é grande o suficiente pra valer a menção, mas a comparação certa é o seu codebase, não o da Rakuten.
Capacidades Novas Ausentes no 4.6
Nível de esforço xhigh — trade-off mais fino entre raciocínio e latência
Níveis de esforço no 4.6: low, medium, high, max. O Opus 4.7 adiciona xhigh entre high e max. O Claude Code usa xhigh como padrão em todos os planos. O CTO da Hex observou que "Opus 4.7 em low-effort é praticamente equivalente ao Opus 4.6 em medium-effort" — o que significa que se você usava high no 4.6 pra uma tarefa, xhigh no 4.7 é o setting comparável apropriado.
# Claude Code
/effort xhigh
# API
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=64000,
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "..."}]
)Task budgets (beta público) — limita gasto de token em job agêntico longo
Um task budget dá ao modelo um alvo de token pra um loop agêntico inteiro — pensamento, tool call, resultado de tool e saída final, tudo somado. O modelo vê uma contagem corrente e fecha de forma elegante quando o budget se aproxima. Não disponível no 4.6. Usa o header beta task-budgets-2026-03-13:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
betas=["task-budgets-2026-03-13"],
output_config={
"effort": "high",
"task_budget": {"type": "token_target", "token_target": 50000}
},
messages=[{"role": "user", "content": "..."}]
)Task budgets são consultivos, não limites duros — o modelo sabe do alvo, mas pode passar do token_target. O mínimo é 20K tokens. Pra tarefa aberta, com qualidade em primeiro lugar, a Anthropic recomenda omitir o task budget.
/ultrareview no Claude Code — sessão de code review multi-pass
Comando novo no Claude Code, indisponível no 4.6. Sessão dedicada pra revisão de arquitetura, segurança, performance e manutenibilidade num único pass estruturado. A Anthropic tá oferecendo três ultrareviews grátis no lançamento pra usuários Pro e Max.
Auto Mode pra usuários Max
Antes restrito a planos Enterprise nas configurações do 4.6. Agora disponível pra usuários Max: o agente ajusta o comportamento automaticamente pra evitar interromper tarefa longa, lidando com ambiguidade pequena de forma independente em vez de pausar pra confirmar.
A Realidade do Custo
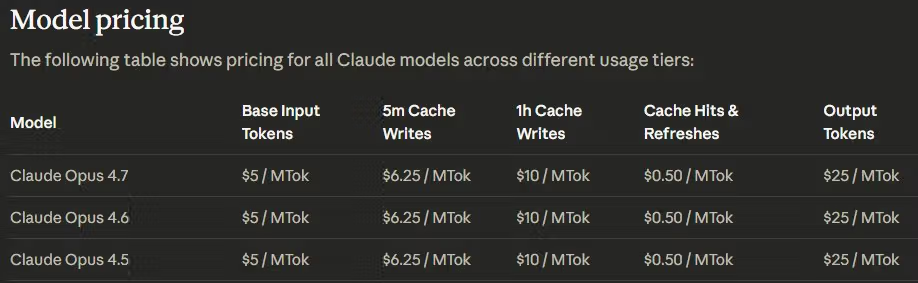
Preço de tabela inalterado: $5/$25 por milhão de token
O pricing é idêntico no Opus 4.7 e no 4.6 na Claude API, no Amazon Bedrock, no Google Cloud Vertex AI e no Microsoft Foundry. Desconto da Batch API (50%) e prompt caching (até 90%) também não mudaram.
Mudança no tokenizer: mesmo input → até 1,35× mais token
O guia de migração da Anthropic: "Esse novo tokenizer pode usar de aproximadamente 1x a 1,35x mais token ao processar texto comparado a modelos anteriores (até ~35% a mais, variando conforme o conteúdo)."
A faixa não é uniforme entre tipos de conteúdo:
| Tipo de conteúdo | Multiplicador aproximado | Implicação prática |
|---|---|---|
| Prosa em inglês | 1,00–1,05× | Impacto desprezível pra workload de chat |
| Código limpo (identificadores em inglês) | 1,05–1,10× | Aumento pequeno em codebase típico de API |
| Conteúdo técnico/misto | 1,10–1,20× | Arquivo de config, log, mistura de inglês com código |
| Texto multilíngue (CJK, árabe, cirílico) | 1,20–1,35× | Aumento relevante pra produto não-inglês |
| Dado estruturado (JSON, XML) | 1,10–1,25× | Varia com a verbosidade do schema e profundidade do nesting |
Nota: essas faixas são inferidas a partir do range geral de 1,0–1,35× declarado pela Anthropic e do padrão de comportamento por tipo de conteúdo. O multiplicador real pro seu conteúdo específico exige medição direta com /v1/messages/count_tokens.
Exemplo prático: 1.000 tarefas de codificação/mês
Premissas:
- Input médio por tarefa: 8.000 tokens (system prompt 2K + contexto de código 4K + mensagem de usuário 2K)
- Output médio por tarefa: 3.000 tokens (alteração de código + explicação)
- Tipo de conteúdo: código em inglês + contexto técnico → multiplicador estimado de tokenizer de 1,10× no input
Custo mensal Opus 4.6:
- Input: 1.000 × 8.000 = 8.000.000 tokens → 8M × $5/M = $40,00
- Output: 1.000 × 3.000 = 3.000.000 tokens → 3M × $25/M = $75,00
- Total: $115,00/mês
Custo mensal Opus 4.7 (mesmo volume de tarefa):
- Input: 8.000.000 × 1,10 = 8.800.000 tokens → 8,8M × $5/M = $44,00
- Output: 3.000.000 tokens (impacto do tokenizer no output é mais difícil de isolar; assume similar) → $75,00
- Total: $119,00/mês
- Aumento: $4,00 (+3,5%)
Pra conteúdo multilíngue no teto de 1,35×:
- Input: 8.000.000 × 1,35 = 10.800.000 tokens → 10,8M × $5/M = $54,00
- Total: $129,00/mês vs $115,00 (+$14,00, +12,2%)
O verdadeiro driver de custo pra maior parte dos times não é o tokenizer — é o esforço xhigh** gerando mais token de pensamento em tarefa complexa.** Se você rodava em max no 4.6 e troca pra xhigh no 4.7, o token de output por tarefa pode aumentar. Mede em tráfego representativo antes de comprometer em volume.
Onde o caching compensa a inflação
System prompt estável e definição de tool em cache via prompt caching ganham até 90% de redução de custo independente da mudança de tokenizer. Se seu system prompt tem 4.000 tokens no 4.6 e 4.400 tokens no 4.7 (10% de inflação do tokenizer), o custo do cache hit ainda é 90% mais barato que a tarifa sem cache. Pra arquitetura onde o system prompt é estático na maior parte das requisições, o caching neutraliza praticamente todo o impacto do tokenizer no custo de input.
Riscos de Migração
Prompt escrito pra interpretação solta do 4.6 pode produzir saída diferente
Padrões específicos pra auditar antes de migrar:
- Bullet list usada como guia em vez de requisito estrito — o 4.7 trata como spec hard
- Prompt que funcionava fornecendo restrição parcial e contando com o modelo pra preencher os buracos
- Prompt de tool use que esperava o modelo chamar tool de forma proativa — o 4.7 "usa tool com menos frequência que o Opus 4.6 e usa raciocínio mais" nos níveis de esforço padrão; sobe pra
highouxhighse a frequência de tool call cair - Padrões de prefill: prefill de mensagem do assistant retorna erro 400 desde o Opus 4.6 e continua no 4.7 — confirma que isso já foi tratado na sua migração pro 4.6
Re-medição de token budget obrigatória em tráfego real
/v1/messages/count_tokens retorna valor diferente pro 4.7 em comparação com o 4.6 no mesmo input. Qualquer estimativa de custo, planejamento de rate limit ou roteamento baseado em token na sua infra precisa ser re-calibrado contra tráfego real do 4.7. A recomendação da Anthropic: roda uma amostra representativa de tráfego de produção pelo 4.7 no seu nível de esforço alvo e compara o total de token de input+output direto.
Framework de Decisão: Quando Dividir o Tráfego
Pra time que não consegue se comprometer com migração total, rotear um subset de tráfego pro 4.7 faz sentido quando:
| Condição | Recomendação de roteamento |
|---|---|
| Agentes de codificação autônomos (trabalho de feature nova) | Roteia 100% pro 4.7; ganho consistente nas avaliações de partner |
| Workflow pesado em computer use / screenshot | Roteia 100% pro 4.7; salto de capacidade em visão é hard |
| Pesquisa agêntica na web (workload tipo BrowseComp) | Mantém no 4.6 ou testa GPT-5.4; o 4.7 regrediu 4,4 pontos |
| Execução de comando shell / terminal | A/B test; o 4.7 supera o 4.6 em 4pp mas fica 5,7pp atrás do GPT-5.4 |
| Conteúdo multilíngue (CJK, árabe) | A/B test com monitoramento de custo; impacto do tokenizer é maior aqui |
| Prompt de produção com formatação rígida | Testa primeiro num subset de 10%; mudança de rigor na instrução afeta esses mais |
| Processamento em batch (não-time-sensitive) | Roda A/B completo na Batch API com 50% de desconto pra medir delta de qualidade antes de comprometer |
FAQ
O 4.7 compartilha rate limit com o 4.6?
Rate limits são por modelo na API da Anthropic. Opus 4.6 e 4.7 têm alocação de rate limit separada. Confere os limites do seu tier atual em platform.claude.com se você tá perto da capacidade — migrar pro 4.7 não herda a folga de rate limit do 4.6.
A mudança no tokenizer é maior pra código ou pra linguagem natural?
Com base no range de 1,0–1,35× da Anthropic e nos padrões por tipo de conteúdo, código em inglês com identificador em inglês fica na ponta de baixo (aproximadamente 1,05–1,10×). Prosa em inglês é parecido. Texto multilíngue e dado estruturado (JSON, XML) tendem pra ponta de cima. A recomendação oficial da Anthropic é medir direto: /v1/messages/count_tokens no seu input real é o único número confiável.
Devo testar o 4.7 num subset antes da migração total?
Sim, principalmente se algum desses casos se aplica: você tem prompt afinado pra interpretação solta do 4.6, processa conteúdo multilíngue em volume, depende de um padrão específico de frequência de tool call, ou seu workflow faz pesquisa agêntica na web relevante onde tarefa tipo BrowseComp importa. Trocar o ID do modelo é trivial; o trabalho real de migração tá na auditoria de impacto em prompt e custo. O guia de migração da Anthropic em platform.claude.com/docs/en/about-claude/models/migration-guide cobre as breaking changes específicas e os passos recomendados de validação.
Artigos relacionados
Claude AI: Acesso Gratuito 2026
Windsurf: Preços e Planos 2026
