
ByteDance launched Seed2.1 on June 23, 2026 with a bold framing: a model for "the Coding and Agent era," built for end-to-end engineering delivery — requirement analysis through implementation, bug fixing, environment setup, and validation. The launch demo showed it running for hours and producing working code. The temptation is to read "end-to-end delivery" as "this model ships software on its own." It doesn't — and the gap between what ByteDance officially claims and what's independently verified, plus the gap between a capable model and a complete coding-agent system, is exactly what a developer evaluating Seed2.1 needs to map. Here's that map.
Capabilities and benchmarks below reflect ByteDance/Volcano Engine's vendor-reported information as of June 2026 — independent verification was not yet broadly available at the time of writing. Confirm current specs, pricing, and access against the official ByteDance Seed site before relying on any specific.
What ByteDance Actually Released
Pro and Turbo in the Seed2.1 model family
ByteDance officially released Seed2.1 on June 23, 2026, positioning it as a next-generation model for coding and agent work. The family includes two main coding-relevant variants: Doubao-Seed-2.1-Pro, the flagship "deep thinking" model aimed at high-complexity work (complex coding, long-chain agents, multi-step engineering delivery), and Doubao-Seed-2.1-Turbo, a lower-cost, lower-latency variant for large-scale production that the company describes as having complete features with performance approaching Pro. There's also a continuously-updated Seed-Evolving variant. This guide is about Seed2.1's fitness as a coding-agent model in general, not about choosing between Pro and Turbo — that selection depends on your cost and latency needs, which is a separate question from whether the model can do the engineering work at all.
Current access through Doubao and Volcano Engine
Seed2.1 is accessed through ByteDance's channels: the Doubao app for interactive use, and the Volcano Engine (Volcano Ark) API platform for programmatic access. For builders, the API is the relevant surface — Volcano Engine reports the models are compatible with coding-agent frameworks including Claude Code and Codex, which means they can potentially slot into agent setups that accept a custom endpoint. Because access, regional availability, and the exact API terms are ByteDance-specific and subject to change, confirm the current access path and any data-handling terms in the official documentation for your situation rather than assuming, especially if you're outside ByteDance's primary market.
The End-to-End Coding Claim, Broken Down
ByteDance's headline claim is that Seed2.1 handles the full engineering chain. It's worth breaking that claim into its parts and reading each as an official capability statement — what the vendor says the model is built to do — rather than as independently confirmed fact.
Requirement analysis and architecture planning
The claim: Seed2.1 can take a requirement, analyze it, and plan an architecture before implementing. This is the "deep thinking" and "autonomous planning" the Pro variant is positioned around — turning a stated need into a structured plan. As a capability claim it's coherent (planning-before-execution is a known and valuable agent pattern), but how well it plans on your actual requirements, in your domain, is the empirical question the claim doesn't answer.
Multi-file implementation and bug fixing
The claim: Seed2.1 can implement features across multiple files and fix bugs, with "dynamic repair" capability — correcting its own work as it goes. ByteDance's launch demo illustrated this with a long-running task (a chip-design RTL case reported to run many hours across multiple iterations, producing working modules that passed verification). That demo is a vendor demonstration, not an independent benchmark — impressive as a showcase, but it shows what the model did in ByteDance's chosen scenario under ByteDance's setup, which is different from what it will do on your codebase.
Environment setup and result validation
The claim: Seed2.1 can set up the environment a task needs and validate its own results (running tests, checking outputs). This closes the "end-to-end" loop in the official framing — the model doesn't just write code, it sets up to run it and checks the outcome. The important caveat: a model validating its own work is only as trustworthy as the validation, and self-validation that isn't independently checked can confirm wrong results. Whether the model's self-validation actually catches its own errors is, again, something you verify rather than take on the vendor's framing.
Model Capability vs a Complete Coding-Agent System
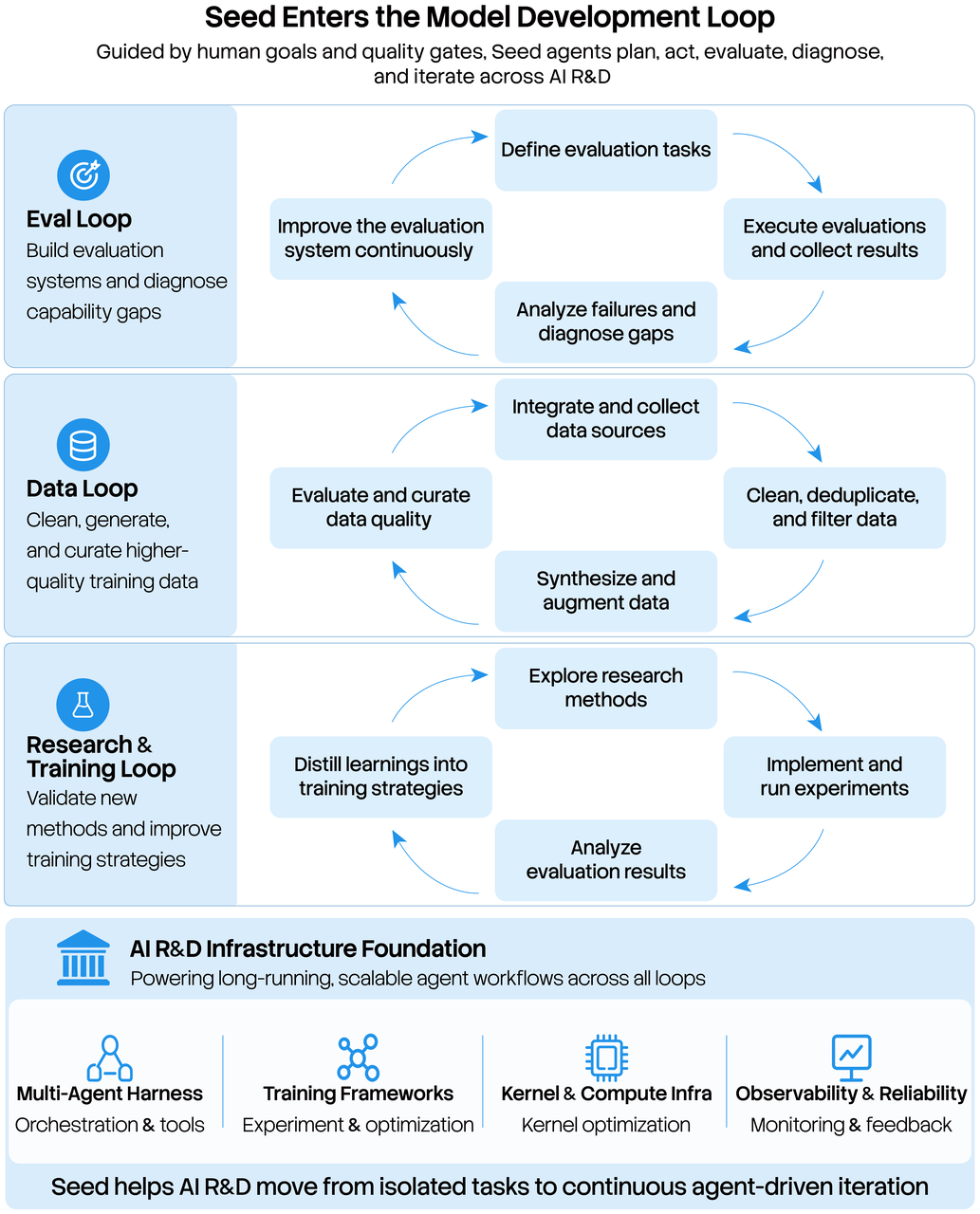
What Seed2.1 provides at the model layer
Here's the distinction the "end-to-end" framing blurs: Seed2.1 is a model, and a model is not a complete coding agent. What Seed2.1 provides is the model layer — the reasoning, the code generation, the planning ability, the tool-call outputs. That's the engine. But an engine isn't a car. The model's capabilities are necessary for coding-agent work, and genuinely the hard part to build, but they're not sufficient on their own to deliver software in your environment.
What still depends on the harness, tools, permissions, and repository context
Around the model, a working coding agent needs a system the model doesn't provide: the harness (which constructs prompts, parses the model's outputs into actions, and manages context across a long task), the actual tool execution (running the file edits and commands the model proposes), permission control (what the agent is allowed to touch), the test infrastructure (that independently validates results rather than trusting the model's self-check), and rollback (undoing changes when something goes wrong). These are system-layer concerns, and they're where a lot of real reliability lives. When ByteDance demos "end-to-end delivery," that demo includes a harness and environment ByteDance built around the model; reproducing end-to-end delivery in your context means building or adopting that surrounding system, not just calling the model. The model is one layer of the system that delivers software — a critical layer, but not the whole thing. This is also why the verification layer (planning, isolation, diff review, independent testing) that workflow tools like Verdent formalize sits separately from the model: it's the system-level discipline that a model, however capable, doesn't supply on its own.
What the Published Evidence Actually Shows
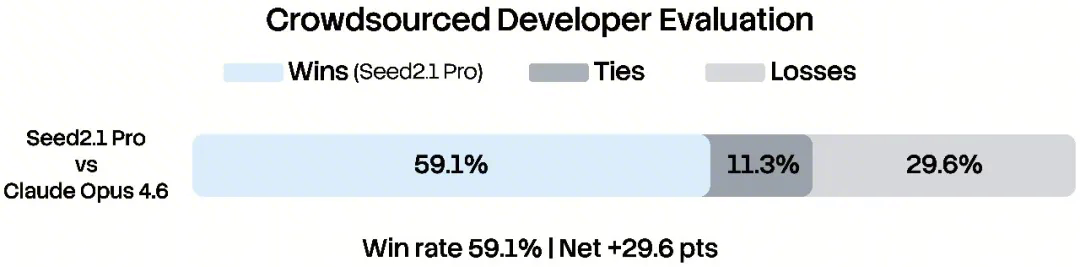
Long-horizon coding and debugging evaluations
ByteDance reports strong results on coding and agent benchmarks — top-tier placements on evaluations like Terminal-Bench, SWE-Pro, and SciCode for code, and leading results on agent/multimodal benchmarks — and claims parity with or advantage over frontier models like GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro on multiple metrics. Read every one of those as vendor-reported: they come from ByteDance's own evaluation and framing, not from independent third parties re-running the models under controlled, identical conditions. A separate third-party arena placement (a frontend coding leaderboard) put a Seed2.1 preview in the top ten, which is a useful external signal — but it's a preview, a single benchmark, and a narrow slice (frontend), not a broad independent validation of the full end-to-end claim.
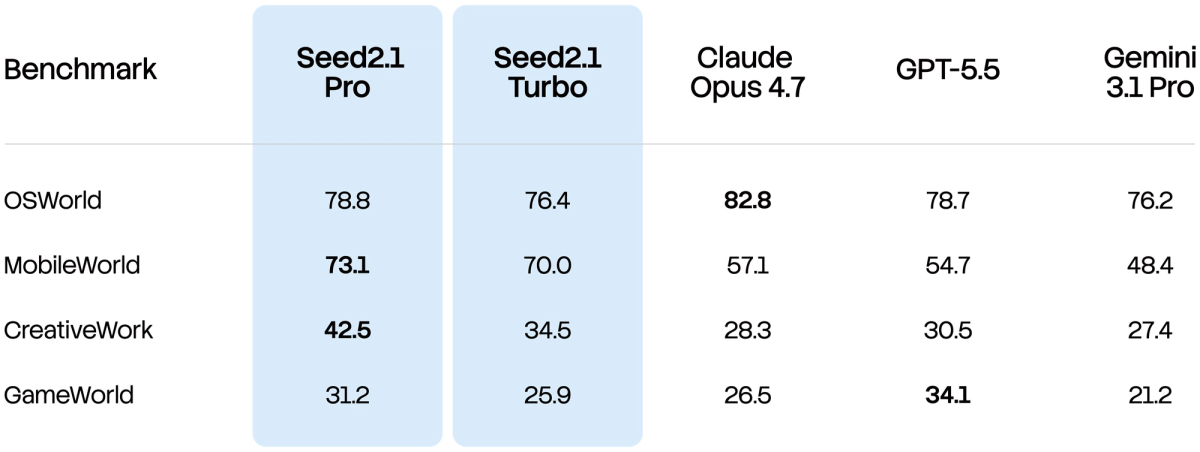
The limits of vendor-reported benchmarks and preference studies
The pattern to internalize: a vendor's benchmark numbers and a vendor's demos tell you what the model can do under conditions the vendor chose and optimized for. They're a legitimate signal of capability ceiling, not a measurement of how the model performs on your work. Crowd-preference comparisons and "comparable to [frontier model]" claims have the same limitation — they're directional, condition-dependent, and not a substitute for testing on your tasks. And community reactions calling it "Opus-class" are vibe checks, not measurements. None of this means the claims are false; it means the evidence published so far is vendor-reported or early, and the only evidence that predicts your results is your own evaluation on your own repository. Treat "production-level" as ByteDance's framing of its ambition, not a confirmed property you can assume for your use.
How to Evaluate Seed2.1 on a Real Repository
Choose a bounded but representative engineering task
The evaluation that actually decides it is one you run. Pick a task that's bounded enough to assess carefully but representative of your real work — a genuine bug fix, a multi-file feature, or a refactor drawn from your own codebase, not a toy problem and not an open-ended "build me an app." Representative-but-bounded is the sweet spot: small enough that you can scrutinize every part of the output, real enough that the result tells you something about how Seed2.1 handles your domain, conventions, and complexity.
Inspect patch quality, test behavior, and failure recovery
Run the task in an isolated copy of the repository and examine three things closely. First, patch quality: read the diff — does it do what was asked, only what was asked, in a way you'd accept in review? Second, test behavior: run your own test suite (not just the model's self-validation) and see whether the changes pass without breaking existing behavior, and whether the model's claimed "validation" matches your independent check. Third, failure recovery: deliberately let it hit a failure and watch whether it diagnoses and adapts or loops unproductively. These three — patch, independent tests, recovery — reveal far more than any benchmark about whether the model can do your engineering work.
Review maintainability before accepting the result
Before you count a task as "delivered," review the output for maintainability, not just correctness. Code that passes tests can still be poorly structured, hard to maintain, or subtly misaligned with your architecture — and a model optimizing to make tests pass can produce exactly that. Read the result as you'd review a colleague's PR: is it code you'd want to own and extend, or code that works today and becomes a liability later? Maintainability is the dimension benchmarks never measure and the one that determines whether "it delivered" is actually true over time. Only count it as delivered when it passes that review, not when the tests merely go green.
Where Seed2.1 Fits in Developer Workflows
API-backed coding-agent experiments
Seed2.1 fits naturally as a model to evaluate inside your own coding-agent experiments — accessed via the Volcano Engine API, slotted into a harness that accepts a custom endpoint, and tested on real tasks. For developers building or customizing agent setups, it's a capable model worth including in your evaluation set, especially if its cost profile is attractive for your volume. The fit here is "a model to test in your agent system," with you supplying the harness, tools, and verification around it.
When an established agent product may require less integration work
The alternative to consider: an established, integrated coding-agent product (one that ships the harness, tool execution, permission controls, and review workflow as a finished system) may require far less integration work than wiring a raw model into your own harness. If your goal is to get agent-driven coding working with minimal setup rather than to build and tune your own agent system, a finished product may fit better than a model-plus-API you assemble yourself. The trade-off is the familiar build-versus-adopt one: a raw model like Seed2.1 offers flexibility and control (and potentially cost advantages) at the cost of the integration and verification work you take on; a finished product offers less work at the cost of less control. Match the choice to whether you're building an agent system or just want one that works.
FAQ
How can an evaluation stay valid when the agent harness changes?
Tie your evaluation to a fixed harness configuration and re-run it when the harness changes, because the harness materially affects results — the same model produces different outcomes under different scaffolding. Practically, record which harness, tools, and settings you used for each evaluation run, treat a result as valid only for that configuration, and re-evaluate when you change the scaffold (new tools, different prompting, updated context management). An evaluation result is really a measurement of the model-plus-harness system, so a harness change invalidates the old number; version your harness alongside your eval tasks so you always know which configuration a given result belongs to. That way a result stays interpretable rather than silently going stale when the surrounding system shifts.
What delivery artifacts should be archived after a Seed2.1 task?
Archive enough to reconstruct and audit what happened: the input task and prompts, the model's output (the diffs/patches it produced), the test results from your independent validation, any logs of tool calls and the model's reasoning if available, and the final reviewed state you accepted or rejected. The point is a record that lets you later answer "what did the model do, what did it claim, what did we independently verify, and what did we accept" — which matters for debugging a bad outcome, for accountability on agent-generated changes, and for comparing runs over time. Treat agent-produced delivery like any change that needs an audit trail: the artifacts are what make a self-running task accountable rather than opaque.
When should Seed2.1 remain read-only during repository evaluation?
Keep it read-only — able to read and analyze code but not write or execute — until it has demonstrated it understands your repository and produces sound proposals. Start by having it explain code, locate implementations, or propose (not apply) changes, and review those proposals; only grant write and execute permissions once read-only work shows it reasons correctly about your codebase. This staged approach contains the risk while you're still learning whether to trust it: a model that misunderstands your code is harmless in read-only mode and potentially damaging with write access. Expand permissions as it earns trust on your tasks, not by default at the start.
What data controls matter before connecting private repositories to Seed2.1?
Before sending private code to Seed2.1, review the data-handling terms for the Volcano Engine API — what happens to the code and prompts you send, retention, whether inputs are used for training, and the regional data-residency implications, since it's a hosted service and your code transits ByteDance's infrastructure. For proprietary or regulated code, those terms determine whether the service is appropriate at all, and they're exactly the kind of policy detail that's specific and can change, so confirm the current official terms for your situation rather than assuming. If your code can't leave your environment under your compliance requirements, that's a gating constraint to resolve before any evaluation on real private repositories — verify it against ByteDance's current official documentation first.
Conclusion
Seed2.1 is a serious coding-and-agent model release from ByteDance, officially positioned for end-to-end engineering delivery and backed by strong vendor-reported benchmarks and an impressive launch demo. But read it precisely: the "end-to-end delivery" framing and the benchmark numbers are ByteDance's claims and demonstrations, not independently verified production-readiness, and a capable model is one layer of a coding-agent system — the harness, tool execution, permission control, independent testing, and rollback that actually deliver software in your environment sit around the model, not inside it. So evaluate Seed2.1 the way the claims can't substitute for: run a bounded, representative task from your own repository, inspect the patch quality and failure recovery, validate with your own tests rather than the model's self-check, and review for maintainability before calling anything delivered. Keep it read-only until it earns trust, confirm the data terms before connecting private code, and treat the vendor's numbers as a capability signal rather than a verdict. Do that, and you'll know what Seed2.1 actually does for your work — which is the only thing that matters.
Related Reading
