
You're building a multi-agent coding pipeline. You've got budget for one flagship open-weight model. And everyone on the team has a different opinion.
I've been testing both of these since launch, and I'll be straight with you — this isn't a clean win for either side. Nemotron 3 Super dropped on March 11, 2026 with numbers that made me double-check the source. DeepSeek V3.2 has been quietly earning its spot in production agent stacks since December 2025. Both deserve serious consideration. The real question is: for your workflow, which one actually fits?
Let's get into it.
How Each Model Approaches Agent Work

These two models were both built with agents in mind — but the philosophy behind each is pretty different.
Long-Horizon Planning
Nemotron 3 Super is a 120B total / 12B active parameter hybrid Mamba-Transformer MoE model trained specifically for agentic reasoning. NVIDIA baked in 15 distinct reinforcement learning environments covering software engineering, terminal use, and general tool use — which means the model wasn't just fine-tuned on chat data and then pointed at agents. It was trained to complete long-horizon tasks from the ground up.
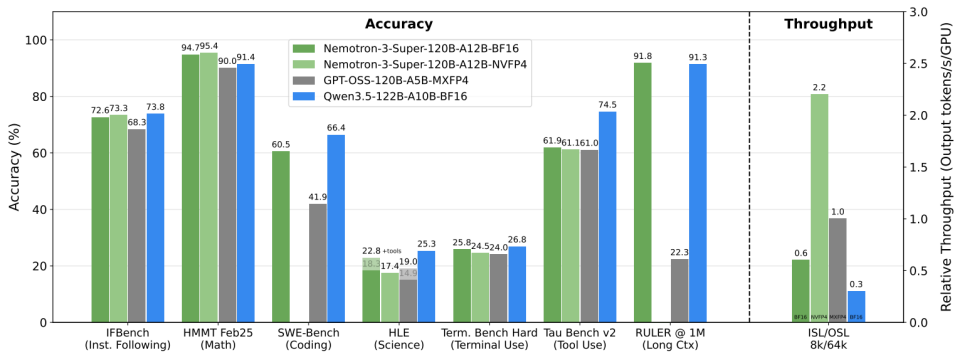
DeepSeek V3.2 took a different approach. The agentic task synthesis pipeline created over 1,800 synthetic environments and 85,000 complex prompts specifically for tool-using agents. On top of that, V3.2 introduced "Thinking in Tool-Use" — where the model maintains an internal chain-of-thought while calling tools. That's not a small thing. It means multi-step plans stay coherent across tool invocations rather than resetting after each function call.
Both approaches work. But they work differently: Nemotron bets on a specialized architecture, DeepSeek bets on post-training scale.
Tool Use and Orchestration
This confused the hell out of me at first, because the benchmarks don't tell the full story here.
On PinchBench (NVIDIA's new benchmark for evaluating models as agent "brains"), Nemotron 3 Super scores 85.6% — the best result for any open-weight model in its class. On SWE-Bench Verified, it hits 60.47% using the OpenHands harness, compared to GPT-OSS-120B at 41.90%. That's a meaningful gap.
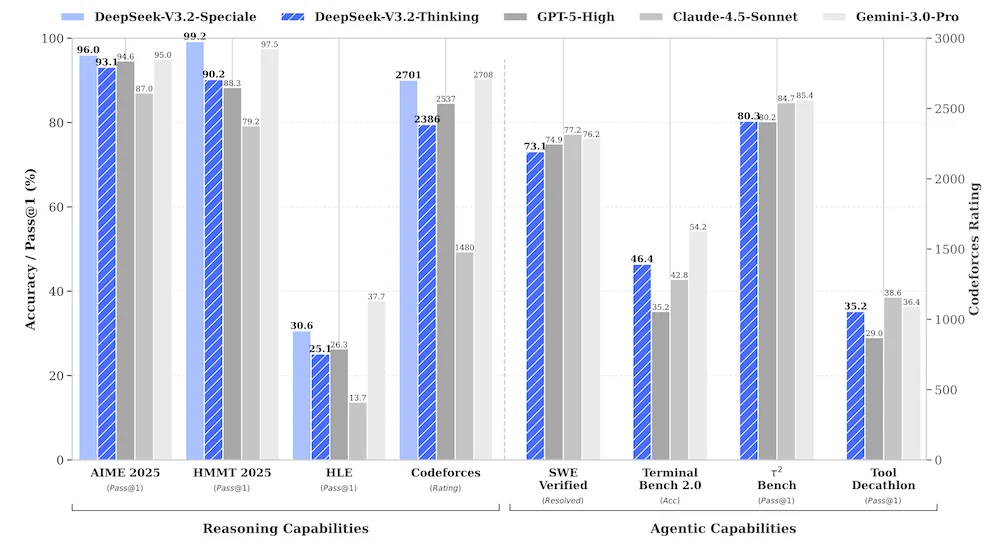
DeepSeek V3.2, meanwhile, was post-trained on combined RL that consumed more compute than its pre-training phase — with explicit focus on tool invocation quality. The V3.2-0324 update further improved tool-calling reliability and role-conditioned behavior, making it noticeably more stable in structured agent pipelines with defined SOPs.
Here's a quick side-by-side of what each model does well in orchestration contexts:
| Capability | Nemotron 3 Super | DeepSeek V3.2 |
|---|---|---|
| SWE-Bench Verified | 60.47% | Not independently verified (V3.2 parity claims vs GPT-5) |
| Tool use training | 15 RL environments | 1,800+ synthetic environments |
| Thinking while using tools | Via reasoning mode | Native "Thinking in Tool-Use" feature |
| Best hardware target | NVIDIA Blackwell (NVFP4) | Runs well across hardware |
| Open license | NVIDIA Open Model License | MIT (Apache 2.0 for V3.2) |
Throughput vs Raw Capability
Why Throughput Matters in Agent Pipelines
Here's something that's been bugging me about how people compare these models: they focus on benchmark scores and completely ignore throughput. In a single-model chatbot, sure, throughput is a secondary concern. But in multi-agent pipelines, where you're running dozens of concurrent agent calls, throughput is everything.
Each agent turn generates tokens. Multiple agents running in parallel multiply that load. If your model is slow, your agents queue up, latency compounds, and user experience degrades — even if the individual outputs are excellent.
Nemotron 3 Super is genuinely fast. Artificial Analysis independently measured 478 output tokens per second — the fastest they've recorded at this model class as of March 2026. GPT-OSS-120B, the next fastest in the class, clocks 264 tokens/sec. That's a 1.8x real-world gap.
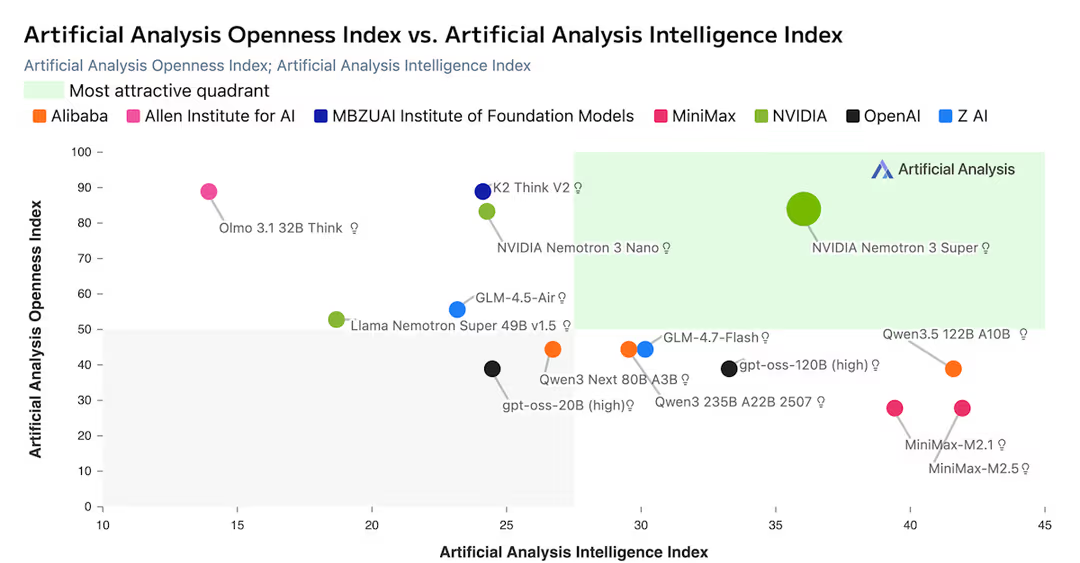
NVIDIA reports up to 2.2x higher throughput than GPT-OSS-120B and 7.5x higher than Qwen3.5-122B in high-volume settings (8K input / 16K output). But — and I want to be clear here — these comparisons are against those specific models, on NVIDIA Blackwell with NVFP4 optimization. On Hopper or AMD hardware, you won't see those same numbers. The throughput story is real, but it's hardware-dependent.
DeepSeek V3.2 is not slow, but it's not optimized for throughput in the same way. It's a 685B-parameter model with ~37B active parameters per token. The DeepSeek Sparse Attention (DSA) mechanism reduces long-context compute costs — which helps at scale — but raw token generation speed is not its headline claim.
If you're running high-concurrency agent workflows where hundreds of calls happen in parallel, Nemotron 3 Super has a real structural advantage. If you're running a smaller orchestration setup where output quality per step matters more than aggregate throughput, the gap narrows considerably.
Context Handling in Practice
When Long Context Actually Helps
Nemotron 3 Super has a 1M-token context window. That's not marketing — the Mamba-2 layers give it linear-time complexity with respect to sequence length, which makes 1M tokens practical rather than theoretical. For software engineering agents that need to load an entire codebase at once, this is a genuine unlock. No chunking, no re-reasoning across segmented documents, no context drift mid-task.
DeepSeek V3.2 supports 128K context. That's sufficient for most real-world agent tasks — but it's a hard ceiling. If your agent pipeline involves reasoning over full transaction histories, large codebases, or thousands of pages of documents in a single pass, you will hit it.
When It Doesn't
Here's the plot twist: long context isn't always an advantage.
Nemotron 3 Super is verbose. During Artificial Analysis's Intelligence Index evaluation, the model generated 110M tokens — against an average of 7.3M across comparable models. At scale, that verbosity translates directly to output token costs. If your agent tasks involve frequent short tool calls rather than deep analysis, you're paying for context capacity you're not using.
DeepSeek V3.2's 128K window with DSA is actually better-suited for the middle tier of tasks — complex enough to need serious reasoning, not so sprawling that they need a million tokens. For most production coding agents, document processors, and research pipelines, 128K is workable.
Deployment and Cost Reality
This is where the two models diverge most sharply — and where your infrastructure matters.
Nemotron 3 Super:
- Open weights under NVIDIA Open Model License (commercially usable, attribution required for derivatives)
- Best performance on NVIDIA Blackwell GPUs with NVFP4; FP8 and BF16 checkpoints available for other hardware
- Available via API on DeepInfra ($0.10/1M input, $0.50/1M output), as well as build.nvidia.com
- Inference tooling is still maturing — the hybrid Mamba-Transformer architecture requires inference infrastructure that not all providers have fully optimized yet
DeepSeek V3.2:
- MIT licensed (Apache 2.0) — genuine open source, no attribution clause
- 685B parameters requires significant GPU memory for self-hosting; 37B active per token via MoE
- Available via DeepSeek's API, Google Vertex AI, AWS Bedrock, and multiple third-party providers
- Mature ecosystem — more providers, more tooling, more production validation
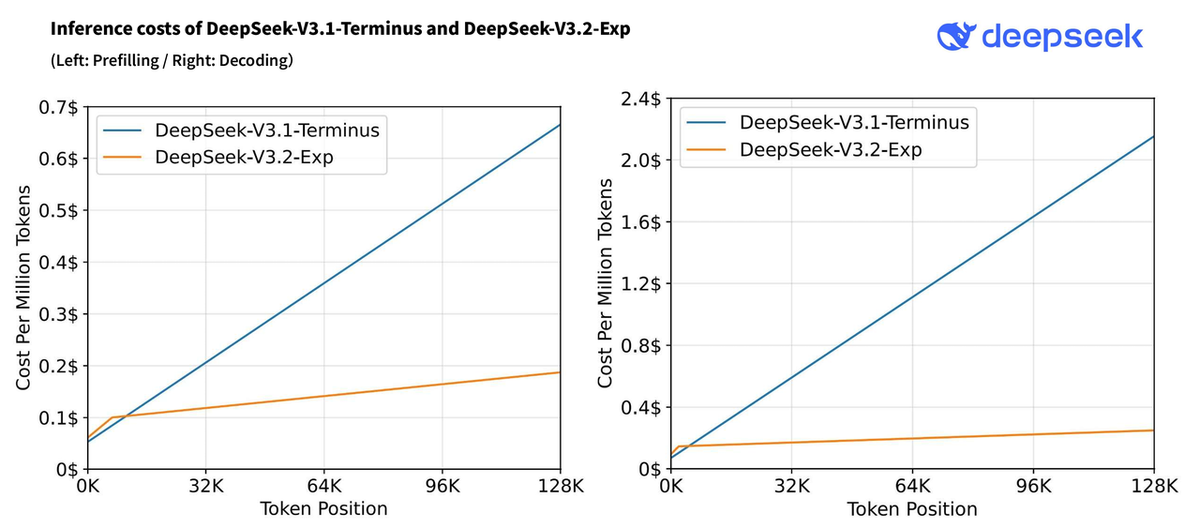
Here's a practical cost comparison for a mid-scale agent deployment (assuming ~50M input tokens and ~20M output tokens per month):
| Nemotron 3 Super (DeepInfra) | DeepSeek V3.2 (DeepSeek API) | |
|---|---|---|
| Input cost | ~$5 | ~$28 (at $0.56/1M) |
| Output cost | ~$10 | ~$33.6 (at $1.68/1M) |
| Total estimated | ~$15/month | ~$61.6/month |
| Self-host viable? | Yes (Blackwell preferred) | Yes (large GPU requirement) |
| License | NVIDIA OML | MIT / Apache 2.0 |
Note: Pricing varies by provider. Verify current rates before committing a production budget.

If you're on NVIDIA Blackwell infrastructure already, Nemotron 3 Super's cost-per-token is significantly lower. If you're on a mixed or cloud-agnostic stack, DeepSeek V3.2's broader provider support gives you more flexibility — and MIT licensing means fewer legal reviews for enterprise teams.
Best Fit by Workflow Type
Okay, so what's the bottom line?
I've been running both in different pipeline configurations, and here's where each model actually earns its keep:
Nemotron 3 Super is the better choice if:
- You're running high-concurrency multi-agent systems where throughput directly impacts cost and user experience
- You need to load large codebases or long document sets into a single context (>128K tokens)
- You're already on NVIDIA Blackwell and want to extract maximum efficiency from your hardware
- Your workflow is software engineering, terminal automation, or cybersecurity triage — the specific RL environments Nemotron was trained on
DeepSeek V3.2 is the better choice if:
- You're building agents that need strong reasoning while using tools — the native Thinking in Tool-Use feature is genuinely useful for complex orchestration
- You need MIT/Apache 2.0 licensing for enterprise legal compliance or open-source redistribution
- You're on cloud-agnostic infrastructure and want maximum provider flexibility (Vertex AI, Bedrock, DeepSeek API)
- Your agent tasks fit within 128K context and you'd rather have deeper reasoning per step than raw throughput
Worth noting: these models aren't necessarily in direct competition for every use case. Teams running the Verdent multi-agent stack have experimented with routing time-sensitive, high-volume orchestration tasks to Nemotron 3 Super while using DeepSeek V3.2 for the deeper reasoning steps that require coherent tool-use chains. That kind of hybrid routing is increasingly practical as both models become available through common inference APIs.
Maybe I'm overthinking this, but the "which model wins" framing misses something real: the answer is almost always "it depends on your pipeline architecture." Benchmark wars are fun. But what matters is which model makes your specific agent stack faster, cheaper, and more reliable.
Both of these do that. Just for different parts of the stack.
Related resources:
