
Sakana Fugu Ultra launched with a striking coding number — a SWE-Bench Pro score ahead of Opus 4.8, GPT-5.5, and Gemini 3.1 Pro — and the temptation is to read that as "Fugu Ultra is better at coding." That reading skips every question that actually matters: who measured it, under what scaffold, against what baselines, and whether a benchmark on curated tasks predicts anything about your repository. Fugu Ultra is also architecturally unusual — it's an orchestration system wearing a single model's API — which changes how you should read its scores again. This guide is about reading those benchmarks correctly, and about what they can't tell you that your own evaluation must.
All benchmark figures below are Sakana AI vendor-reported data as of June 2026, with competing-model baselines provider-reported (not independently re-run in the same environment). Independent third-party verification was not yet available at the time of writing. Always confirm current figures and details against the official Sakana AI announcement before relying on them.
What Sakana Fugu Ultra Actually Is

How Fugu presents multi-agent orchestration as one model
The first thing to understand about Fugu changes how you read everything else. Released by Tokyo-based Sakana AI on June 22, 2026, Fugu presents itself as a single foundation model behind an OpenAI-compatible API — but internally it's a multi-agent orchestration system that coordinates a pool of expert models. You send one request; Fugu decides whether to answer directly or assemble a team of specialist models to handle it. Sakana describes Fugu as itself an LLM trained to call other LLMs in an agent pool (including, recursively, instances of itself), grounded in two of its 2026 research papers — TRINITY (which assigns Thinker, Worker, and Verifier roles to delegate work) and a learned-orchestration approach called the Conductor.
This matters for reading the benchmarks: a Fugu score isn't one model's capability, it's the output of an orchestrated system that may route a task across several models and verify the result. That's a fundamentally different thing to benchmark than a single model, and it's the lens to keep in mind for every number.
Where Fugu Ultra differs from standard Fugu
Fugu comes in two variants: standard Fugu and the higher-tier Fugu Ultra. Ultra is positioned for the harder end of the work — tasks that benefit from deeper analysis and more extensive orchestration, where the system invests more in coordinating and verifying across its model pool. Standard Fugu targets lighter, more interactive use where that extra depth isn't needed. For a builder, the practical distinction is that Ultra's reported advantages show up most on the demanding benchmarks (and, presumably, the demanding real tasks), while standard Fugu may be sufficient — and more economical — for routine interactive work. The reported scores below are Fugu Ultra's unless noted.
Read the Coding Benchmarks Correctly
What each reported benchmark evaluates
Several distinct coding and reasoning benchmarks appear in Sakana's reporting, and they measure different things — conflating them is the first mistake:
- SWE-Bench Pro — resolving real, multi-file GitHub issues validated by test suites; the closest to repository engineering work, and Fugu Ultra's headline coding number (a reported 73.7, ahead of the listed publicly-available baselines).
- LiveCodeBench / LiveCodeBench Pro — contest-style and competitive programming problems (reported in the low-to-mid 90s); these measure algorithmic problem-solving, not repository work.
- TerminalBench 2.1 — completing tasks in a terminal environment (reported around 82); an agentic capability distinct from writing code.
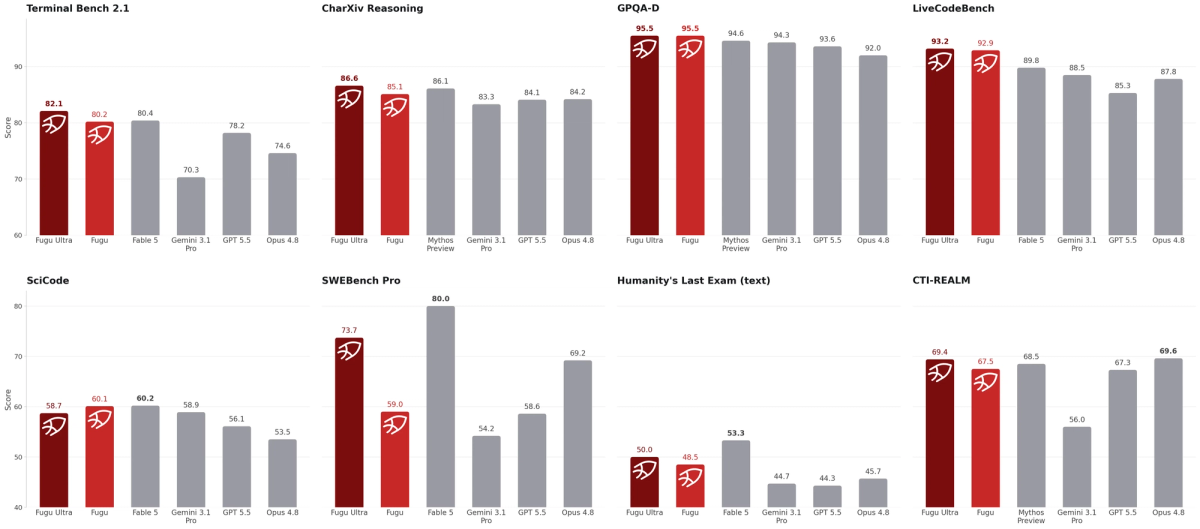
These aren't interchangeable. A high LiveCodeBench score says the system is strong at self-contained algorithmic problems; it says little about navigating a large codebase, which is what SWE-Bench Pro probes. When you read "Fugu Ultra leads on coding," check which coding benchmark — they reward different abilities, and only the repository-style one (SWE-Bench Pro) resembles most real engineering.
Which results use Fugu scaffolding or provider baselines
This is the critical caveat, and the one most coverage omits. Two things shape every comparison number. First, the SWE-Bench Pro results use a specific scaffold — Sakana reports running it with the mini-swe-agent harness — and as with any agentic benchmark, the harness materially affects the score; a different scaffold would produce different numbers. Second, the baseline scores for the competing models (Opus 4.8, GPT-5.5, Gemini 3.1 Pro) are provider-reported, meaning they come from each vendor's own reporting rather than being re-run by Sakana in an identical environment. So the comparison stacks Sakana's scaffolded Fugu result against numbers other vendors produced under their own conditions — not a controlled head-to-head.
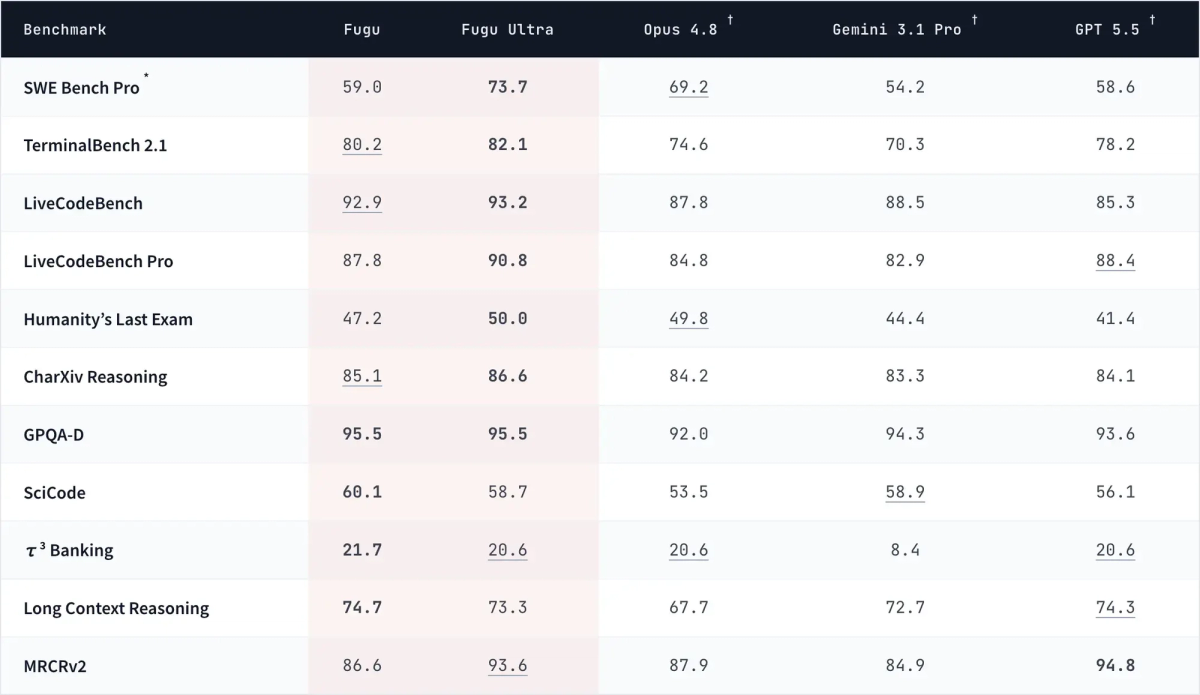
There's a further honesty point Sakana itself notes: Fugu Ultra trails Anthropic's Fable 5 on SWE-Bench Pro — and Fable 5 is precisely the model Fugu cannot include in its pool, because it became inaccessible to most of the world under export controls. So the "leads the field" framing applies to the publicly-accessible models Fugu can orchestrate, not to the very top of the benchmark. Read the leaderboard with both caveats — vendor-reported, scaffold-dependent baselines, and a top-of-table model excluded — firmly in mind.
What Benchmarks Miss About Repository Work
Multi-file consistency and dependency awareness
Even SWE-Bench Pro, the most realistic of these, doesn't fully capture what repository work demands. Real changes ripple: a fix in one file assumes something about another, touches a shared dependency, or interacts with code the benchmark task doesn't include. A benchmark task is bounded; your repository isn't. So a strong SWE-Bench Pro score indicates the system can resolve contained, test-validated issues — it doesn't establish that it maintains consistency across the sprawling, interdependent files of your actual codebase, or that it understands dependencies the benchmark never exercises. Multi-file coherence on real repositories is exactly the kind of thing a benchmark score can't promise.
Test interpretation, rollback, and review quality
Benchmarks score the outcome (did the tests pass?), not the qualities that determine whether you can trust the system in practice. Whether it interprets test failures correctly (versus making tests pass the wrong way), whether its changes can be cleanly rolled back, and whether its output survives a careful code review — none of these is captured by a pass-rate. A patch can pass the benchmark's tests while being poorly designed, hard to maintain, or subtly wrong in a way the test suite doesn't catch. The benchmark measures one dimension of correctness; the dimensions that matter for production trust — reviewability, maintainability, safe failure — sit outside it, and they're the ones your own evaluation has to assess.
Evaluate Fugu Ultra on Real Engineering Tasks
Build a representative repository task set
The benchmark you should trust most is the one you build from your own work. Assemble a set of tasks drawn from your actual repositories — a mix of bug fixes, feature additions, refactors, and the multi-file changes that represent your real distribution. This is the evaluation that vendor benchmarks can't substitute for, because it measures the system on the code, conventions, and problem types you actually face rather than a curated public set. Make it representative of the hard cases, not just the easy ones, since the easy cases rarely reveal where a system breaks.
Compare patches rather than final answers
When you run Fugu Ultra (or any candidate) on those tasks, evaluate the patches, not just whether something "worked." Read the diffs: does the change do what was asked, only what was asked, and in a way you'd accept in review? Two systems can both make a test pass while producing patches of very different quality — one clean and minimal, the other sprawling and fragile. Comparing the actual patches surfaces that difference; comparing only final pass/fail hides it. The patch is the artifact you'll live with, so the patch is what to judge.
Record failures, retries, and human corrections
Keep a structured record of where the system fails, how often it needs retries, and how much human correction its output requires before it's mergeable. This log is the real performance signal — far more decision-relevant than any vendor benchmark, because it measures the system on your tasks and counts the hidden cost (the corrections and retries) that a pass-rate omits. A system with an impressive benchmark score but a high human-correction rate on your work is more expensive than its score suggests; only your own record reveals that.
When Fugu Ultra Fits
Complex work that benefits from deeper analysis
Fugu Ultra's orchestration premise — assembling and verifying across a pool of models — is aimed at hard problems where that extra coordination pays off. For complex, multi-step engineering work that genuinely benefits from deeper analysis and cross-checking (the kind of task where a single model's first answer often isn't enough), Ultra's design is built to help. If your hardest tasks are where you most want stronger results, that's where to test whether Ultra's orchestration delivers a real advantage over a single capable model — on your tasks, measured by your evaluation, not by the reported scores.
Interactive tasks where standard Fugu may be sufficient
The flip side: orchestration has overhead, and not every task needs it. For lighter, interactive work — quick edits, straightforward generation, fast back-and-forth — the deeper analysis of Ultra may be more than the task warrants, and standard Fugu (or simply a single fast model) may be sufficient and more economical. Matching the variant to the task matters: reserving Ultra for the genuinely complex work, and using the lighter option for routine interaction, avoids paying orchestration cost where it doesn't buy you anything. As always, test which variant actually fits each part of your workload rather than defaulting to the top tier.
FAQ
How should developers reproduce vendor-reported coding results?
You generally can't, and that's the point to internalize. Rather than trying to match the headline figure, run the system on a representative sample of your own tasks and measure what you actually care about: resolution rate, patch quality, and correction cost. The goal isn't to confirm the vendor's number — it's to generate your own number on your own work, which is the only one that predicts your results.
What repository tasks expose gaps benchmarks can miss?
Tasks that stress the things a bounded benchmark can't: changes spanning many interdependent files, modifications touching shared dependencies, and scenarios where the test suite is incomplete — revealing whether the system makes tests pass correctly or just superficially. Failure-recovery tasks, where you deliberately introduce a broken state and observe how the system responds, also expose behavior that pass-rates don't capture.
When should Fugu Ultra output require another review pass?
Always treat review as a required step, not an optional one — and weight it most heavily where stakes or complexity are highest. Output headed for production, changes touching security-sensitive paths, and large multi-file patches all warrant careful human review regardless of benchmark score, because a pass-rate doesn't certify that a specific patch is correct, safe, or maintainable. Make review proportional to risk; never let a strong number substitute for it.
Can users inspect which models handled each request?
Confirm this directly against Sakana's current official documentation. Reporting indicates Fugu offers some ability to control which models participate in the pool, but the degree of per-request visibility — and regional availability — should be verified with Sakana before adoption if it matters for your compliance or debugging needs.
Conclusion
Sakana Fugu Ultra is a genuinely interesting system — an orchestration model that routes and verifies across a pool of frontier LLMs behind a single API, with reported coding benchmarks that land near the top of the publicly-accessible field. But read those benchmarks for what they are: Sakana vendor-reported figures, run under a specific scaffold (mini-swe-agent for SWE-Bench Pro), against provider-reported baselines, with the actual top-of-table model (Fable 5) excluded from comparison because Fugu can't access it. A strong benchmark score is a directional signal, not a production guarantee — it doesn't establish multi-file consistency, review quality, or safe-failure behavior on your codebase. So evaluate Fugu Ultra the only way that decides it: build a representative task set from your own repositories, compare the actual patches, record the corrections and retries, and review the output proportional to its risk. Let that evaluation — not the launch numbers — tell you whether Fugu Ultra fits your work.
Related Reading
