
Most MiniMax M3 coverage rehearses the same three bullet points: 1M context, multimodal, open weights. That tells you what the spec sheet says, not whether you should wire it into your coding agent. The more useful question for a builder is: in a real coding-agent loop — reading across a repo, calling tools, running multi-step tasks — what does M3 actually change? The honest answer involves one genuinely interesting architectural bet (sparse attention that makes long context cheap), a set of vendor-reported benchmarks you shouldn't fully trust yet, and a non-standard license that a lot of articles skip. Here's the engineering read.
Verified against MiniMax's official model card, technical report (arXiv:2606.13392), and reporting as of June 2026. Benchmarks are vendor-reported; pricing and license terms change — confirm at the official Hugging Face model card before building.
MiniMax M3 in One Paragraph
An open-weight frontier model built for coding and agentic work
MiniMax M3 is an open-weight model from Shanghai-based MiniMax, released June 1, 2026, aimed squarely at coding and agentic workloads. The pitch MiniMax makes is that it's the first open-weight model to combine frontier-level coding, a 1M-token context window, and native multimodality (text, image, video) in one system. For builders, the relevant framing isn't the "first to combine three things" marketing — it's that you now have a self-hostable, open-weight option for long-context agentic coding, which is a genuinely different position from the API-only closed models.
The headline spec for builders
The architecture: M3 is a 428B-parameter Mixture-of-Experts model with roughly 22B parameters active per token, built on a Grouped-Query Attention backbone with MiniMax Sparse Attention layered on top. Context runs up to 1M tokens, with the platform guaranteeing a minimum of 512K (worth noting the official framing is "up to 1M, minimum 512K," not a flat 1M). It's natively multimodal. The open weights are available on Hugging Face (MiniMaxAI/MiniMax-M3), with a technical report on arXiv. Standard API pricing is $0.60 per million input tokens and $2.40 per million output (a launch-week promo at half that has likely expired — verify current pricing).
Why this is framed as a first
The "first open-weight model to combine frontier coding + 1M context + multimodality" claim is the marketing hook. It's worth treating skeptically as a superlative but seriously as a position: each of those three capabilities exists separately in other models, and combining them in an open-weight model that you can self-host is a real and useful combination for certain workloads — specifically, long-context repo work where you want to keep data local. The combination matters more than the "first" claim.
What MSA (Sparse Attention) Actually Changes for Repo-Scale Work
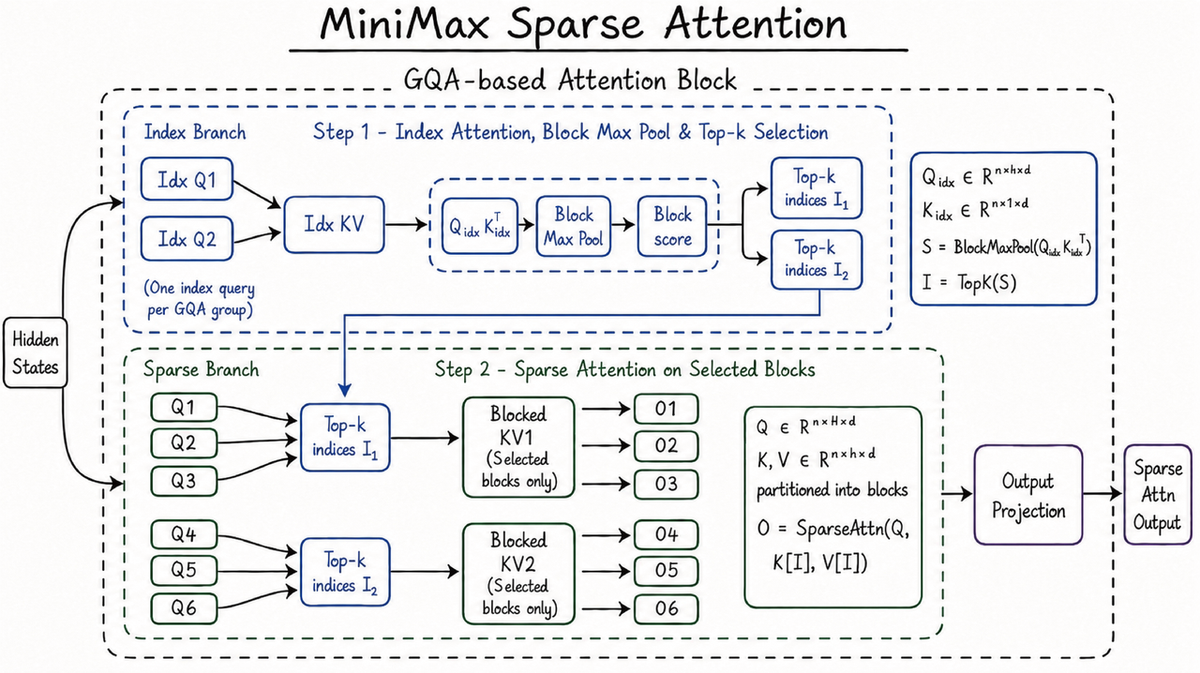
How MSA pre-filters relevant context blocks
Standard transformer attention is quadratic: every token attends to every other token, so doubling the context roughly quadruples the attention compute. That's the wall that makes long context expensive. MiniMax Sparse Attention (MSA) sidesteps it by doing block-level selection — instead of attending to the full context, it pre-filters and attends to the relevant blocks. Crucially, MSA does this selection on real, uncompressed key-values (detailed in the technical report), which is a different bet than approaches that compress the KV state and trade off some long-context precision.
The practical payoff
The payoff is cost. MiniMax reports MSA cuts per-token compute to roughly one-twentieth of the previous generation at long context, with substantially faster prefill and decode at 1M context (reported at roughly 9.7× faster prefill and 15.6× faster decoding versus M2). For a builder, the headline number is the compute reduction: holding a large context becomes far cheaper than quadratic attention would make it. (These are vendor-reported figures — directional, not independently verified.)
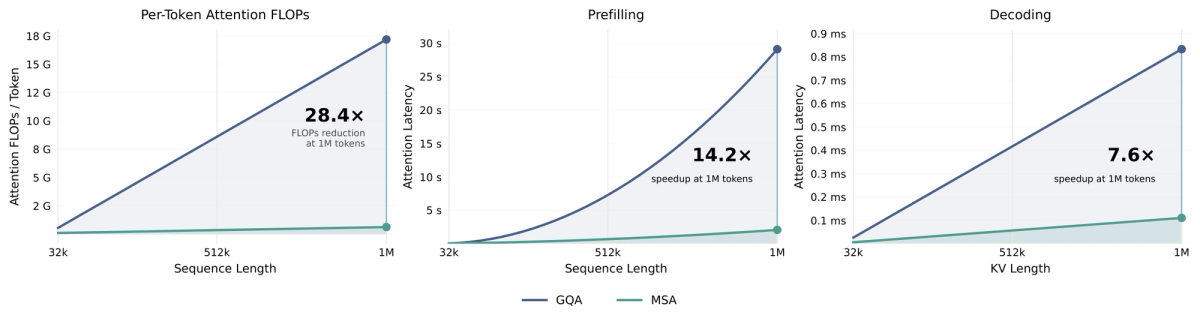
Why this matters for holding a codebase in context
This is the actual engineering significance for repo-scale work. The reason "1M context" is usually more marketing than utility is cost: filling a million-token window with quadratic attention is prohibitively expensive per call. MSA is the mechanism that's supposed to make large context economically usable — you can hold a large chunk of a codebase in context without the per-call cost exploding. If MSA delivers as claimed, the value isn't the 1M number itself; it's that long context becomes cheap enough to actually use in an agent loop that makes many calls. That causal chain — sparse attention → cheap long context → usable repo-scale work — is the real reason M3 is interesting for coding agents.
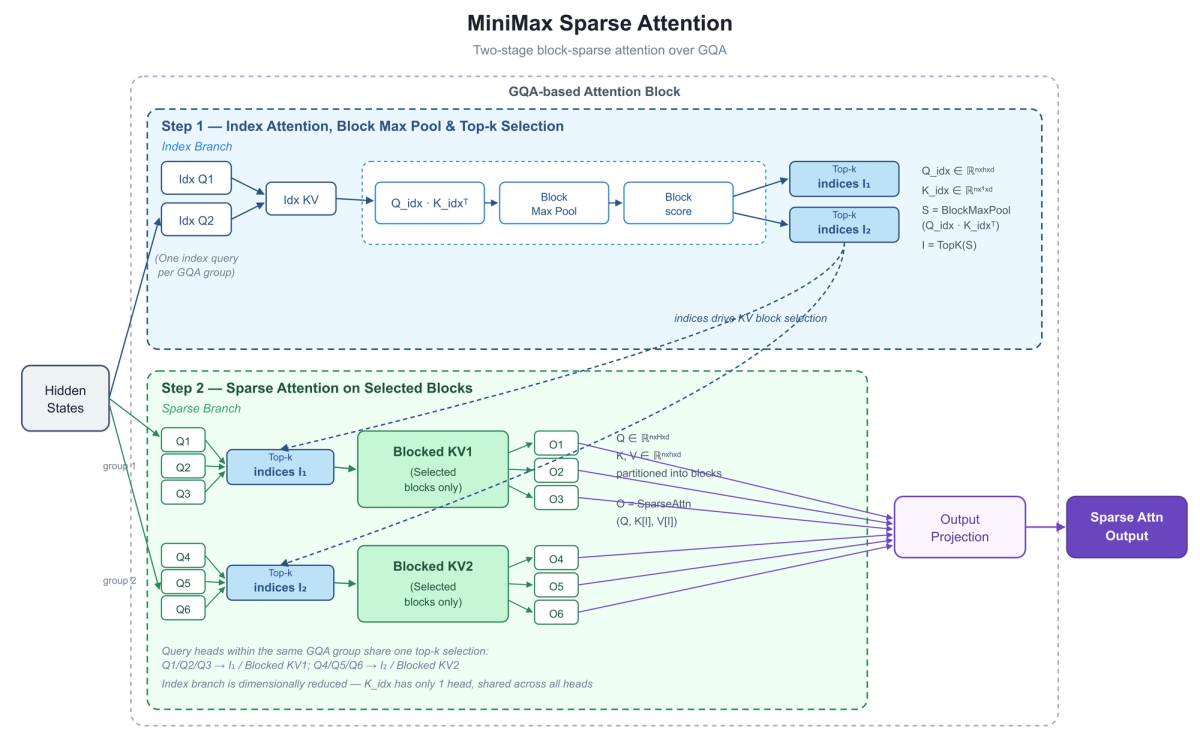
M3 Inside a Coding Agent: Where the Value Shows Up
Long-context repo work
The clearest fit: tasks that need to read across many files at once. A migration touching dozens of files, debugging that requires correlating logs with source with test output, or understanding an unfamiliar codebase — these benefit from holding everything in one context window rather than chunking it. M3's large, (claimed) economical context is built for exactly this. If your agent work is bottlenecked by context limits — constantly re-loading files, losing track across chunks — this is where M3's design targets the problem.
Tool use and invocation
Coding agents don't just answer; they act — calling tools, running terminal commands, reading results, iterating. M3 is built for this agentic loop, with tool-calling and function invocation as core capabilities (MiniMax reports 74.2% on the MCP Atlas tool-use benchmark, vendor-reported). For a builder, what matters is whether it reliably calls the right tools with the right arguments in your harness — something to test on your actual tool set rather than infer from a benchmark.
Multi-step reasoning and autonomous task decomposition
M3 is positioned for long-horizon coding — decomposing a task into steps and working through them autonomously. MiniMax claims it supports 8+ hour autonomous coding sessions (a vendor claim; treat the duration figure as a capability assertion, not a verified guarantee of output quality). The relevant point for builders: long-horizon capability means more autonomous output per invocation, which raises both the potential value and the verification burden — more unreviewed work to check.
The Producer + Verifier loop in MiniMax Code
MiniMax Code (the first-party agent product) implements a Producer + Verifier loop — one part generates, another checks, enabling continuous self-correction during execution. This is a sensible design pattern (self-verification within the loop catches errors before they propagate), and it's worth knowing if you use MiniMax Code directly. The caveat is the familiar one: in-loop self-verification is a useful signal, not a replacement for your own review of the output before it merges.
Where M3 Fits vs Closed Models (Claude, GPT)
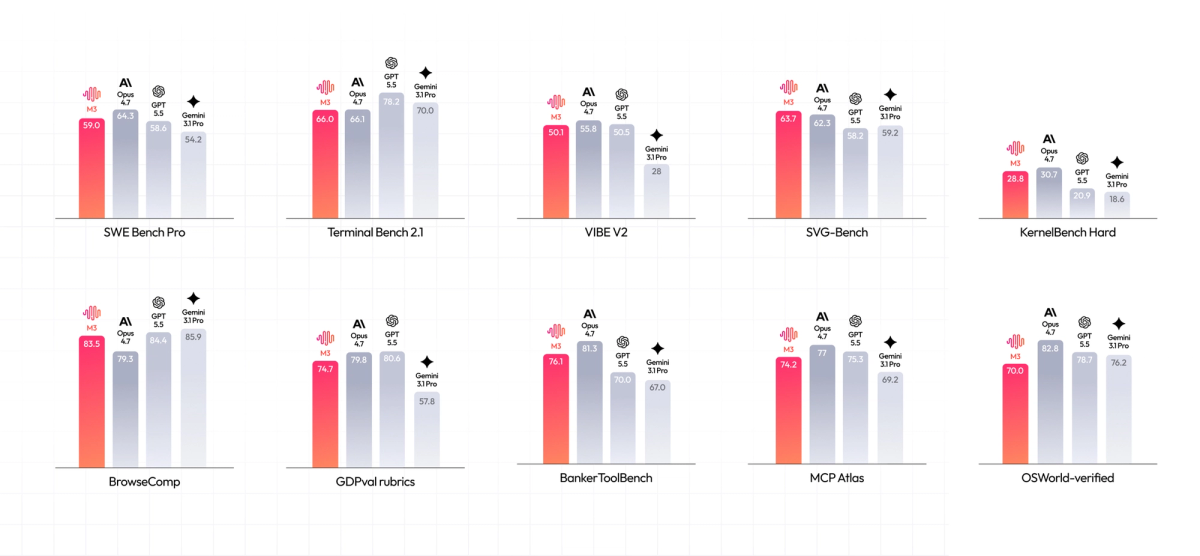
The open-weight angle
The clearest differentiator from Claude and GPT is that M3's weights are open — you can self-host. For teams with data-residency requirements (code can't leave your infrastructure), this is the deciding factor: M3 can run inside your perimeter where API-only closed models can't. That's a categorical difference, not an incremental one. If self-hosting matters to you, M3 is in a different category than the closed frontier models regardless of benchmark scores.
Cost-per-task framing
On cost, M3 is dramatically cheaper per token than closed frontier models — its API pricing is a fraction of Claude Opus or GPT-class pricing, and self-hosting removes per-token cost entirely (for the cost of compute). For high-volume agent loops where token cost dominates, this is a real advantage. The right way to evaluate it isn't raw benchmark comparison but cost-per-successful-task: a cheaper model that completes the task is better value than an expensive one, even if the expensive one scores higher in the abstract.
What you give up and what's unproven
What you give up is certainty: M3's performance claims are vendor-reported and not yet validated on neutral boards (more below). Against the newest closed releases (Claude Opus 4.8, the latest GPT and Gemini), M3's standing is genuinely unproven — the comparisons MiniMax publishes are against specific versions under its own testing. So the honest position is: M3 offers open weights and low cost with competitive vendor-reported performance, but whether it matches the best closed models on your work is something only your own testing can answer.
Limits and What's Still Unverified
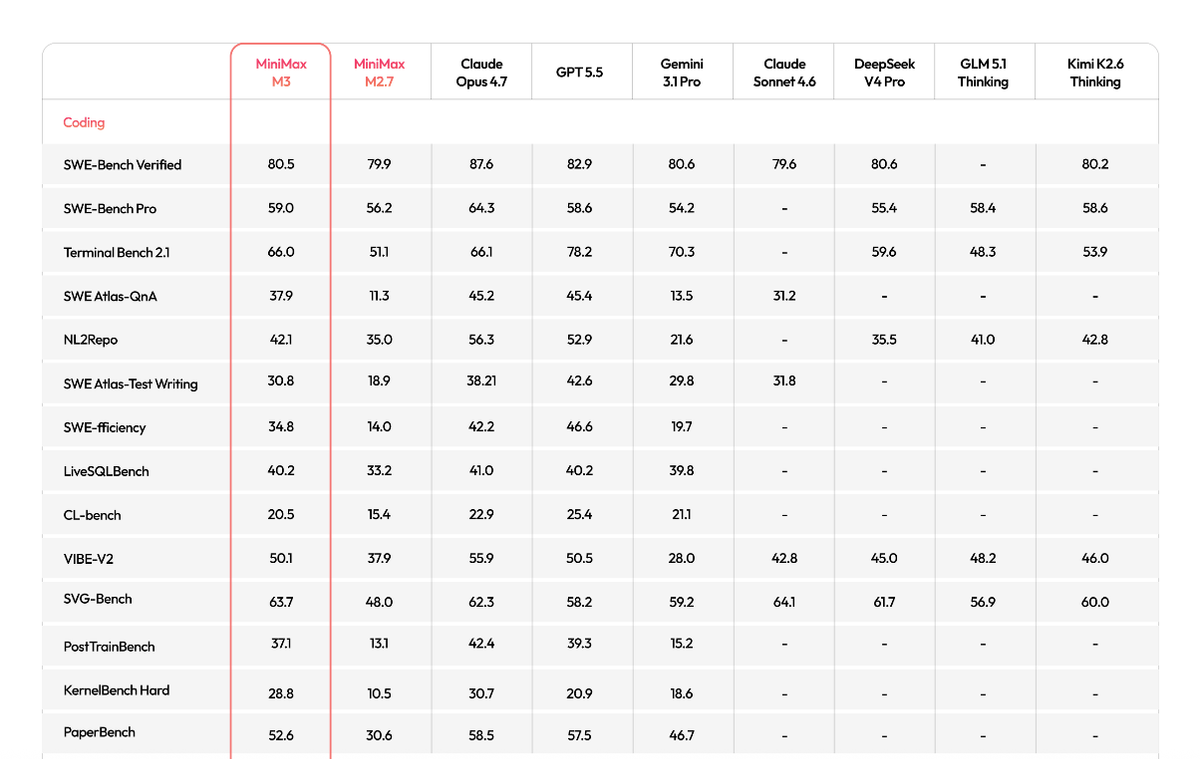
Benchmarks are vendor-reported
Every M3 benchmark figure (SWE-Bench Pro, Terminal-Bench, MCP Atlas, BrowseComp) comes from MiniMax, run on its own infrastructure, reportedly with Claude Code scaffolding around the model. This isn't unusual for a launch, but it means the numbers reflect MiniMax's best-case setup, not a neutral comparison. Treat them as vendor claims indicating the model is competitive, not as established facts about how it performs against other models.
Not yet on neutral long-horizon boards
As of this writing, M3 hadn't yet appeared on neutral evaluation boards like DeepSWE that would strip away the vendor's own scaffolding. This is the key thing to watch: independent benchmark runs and neutral-board placement are what would turn the vendor claims into verified performance. Until those arrive, the performance picture is MiniMax's own.
License is the MiniMax Community License
The detail many articles miss: M3's weights are released under the MiniMax Community License, not a standard permissive open-source license (like Apache 2.0 or MIT). "Open weights" does not automatically mean "free for any commercial use." Before building anything commercial on M3, read the actual license terms — there may be restrictions on commercial use, scale, or redistribution that a standard open-source license wouldn't impose. This is a real compliance step, not a formality; verify the current terms directly.
Self-host reality
"Open weights" doesn't mean "runs on your laptop." M3 is a 428B-parameter model — self-hosting the full weights requires serious hardware (community estimates put it around 214GB+ at 4-bit quantization, so multiple high-memory GPUs). Self-hosting is viable for teams with the infrastructure (NVIDIA has published deployment guidance for serving the model), but it's a server-class deployment, not a local-dev convenience. For most, the practical path is the API; self-hosting is for teams with specific data-residency or cost reasons and the hardware to back it.
Who Should Test M3 (and Who Shouldn't Yet)
Good fit
Test M3 if you're doing long-context repo work (large codebases, migrations, multi-file reasoning) where its context design targets a real bottleneck; if you're running cost-sensitive agent loops where its low per-token cost matters; or if you have open-weight or compliance requirements (data residency, self-hosting) that closed API models can't meet. For these cases, M3 addresses a real need that the closed alternatives structurally can't, and it's worth evaluating on your actual tasks.
Hold off
Hold off if you need neutral-board-verified performance before procurement — the vendor-reported benchmarks aren't enough for a decision that requires independent validation, and the neutral-board data isn't in yet. Also hold off if you need a model that runs locally on modest hardware (M3 is server-class), or if your use case is squarely in the closed-model comfort zone (API-only is fine, cost isn't a constraint, and you want the most proven performance). For those, waiting for independent benchmarks or staying on a proven closed model is the more conservative call.
FAQ
What is MiniMax M3 and why are people talking about it for coding?
MiniMax M3 is an open-weight model from Shanghai-based MiniMax, released June 1, 2026 — a 428B-parameter MoE (~22B active per token) with up to 1M-token context (minimum 512K guaranteed), native multimodality, and a sparse-attention architecture (MSA) designed to make long context economical. It's discussed for coding because it combines frontier-level coding claims, a large context window, and open weights you can self-host — a combination the closed API-only models don't offer. The benchmarks are vendor-reported, so the interest is in the position (open + long-context + cheap) more than proven supremacy.
Does MiniMax M3 actually have a usable 1 million token context window?
The official framing is "up to 1M tokens, with a minimum of 512K guaranteed" — so 1M is the ceiling, not a flat guarantee. More importantly, a large context window is only useful if the model reasons well across it and the cost is economical. M3's MSA architecture is specifically designed to make long context cheaper (reportedly ~1/20 the per-token compute of the prior generation), which is what makes the large window potentially usable rather than just a spec. But "longer" isn't automatically "better" — test whether M3 actually reasons well across your real long-context tasks rather than assuming the full window is useful.
How good is MiniMax M3 for real coding agent work and large repositories?
On vendor-reported benchmarks, M3 is competitive for coding and agentic tasks, and its design (large economical context, tool use, long-horizon decomposition) targets real coding-agent needs — especially large-repo work that benefits from holding many files in context. But the benchmarks are MiniMax's own, run with its scaffolding, and not yet validated on neutral boards. The reliable way to gauge it for your repos is to test it directly: run it on representative tasks from your codebase and measure completion, correctness, and cost. Its design fits large-repo work; whether it delivers on yours is an empirical question.
Is MiniMax M3 better than Claude or GPT models for coding tasks right now?
There's no neutral answer available yet. The only performance data is vendor-reported (MiniMax's own benchmarks, run with its scaffolding), and M3 hasn't appeared on neutral evaluation boards that would allow an independent comparison. So the honest statement is: on its self-reported benchmarks, M3 is competitive with closed models, but there's no neutral-board data to confirm whether it matches or beats the latest Claude or GPT releases on real work. Anyone claiming M3 definitively beats (or loses to) the closed models is going beyond the available evidence. Test on your own tasks.
Are the open weights for MiniMax M3 available to download yet?
Yes — the open weights are available on Hugging Face (MiniMaxAI/MiniMax-M3), with a technical report published. The important caveat: they're released under the MiniMax Community License, which is not a standard permissive open-source license. "Available to download" does not mean "free for any commercial use" — before building anything commercial on M3, read the actual license terms, as there may be restrictions on commercial use or scale. Also note that self-hosting requires server-class hardware (a 428B model, roughly 214GB+ at 4-bit per community estimates), not a laptop.
Conclusion
MiniMax M3 is best understood as a serious open-weight option for long-context, cost-sensitive coding-agent work — not a proven Claude/GPT killer. Its real engineering value is the MSA architecture that makes large context economical, which targets a genuine bottleneck in repo-scale agent work; its real limitation is that the performance claims are vendor-reported and not yet neutral-board-verified, and the license is non-standard. The conservative judgment for builders: if you have a long-context, cost, or self-hosting need that closed models can't meet, test M3 now on your actual tasks (and check the license before commercial use). If you need independently verified performance before committing, wait for neutral-board data rather than acting on vendor benchmarks. Either way, the decision should rest on your own repo-level evaluation, not the launch numbers.
Related Reading
