
500% more landed pull requests. That's what OpenAI reported from internal teams in the first three weeks after deploying Symphony — and it's the number that sent 15,000+ developers to the GitHub repository within days of the April 27, 2026 release. Before you take that at face value or dismiss it, it's worth understanding exactly what Symphony is, what caveats attach to that number, and what it would actually take for your team to see results like that. The honest answer to all three questions is more interesting than the headline.
Symphony in One Paragraph
Symphony is an open-source specification — primarily a SPEC.md file — that describes how to turn a project management board into a continuous dispatch system for coding agents. Released April 27, 2026, by OpenAI engineers Alex Kotliarskyi, Victor Zhu, and Zach Brock, it ships alongside a reference implementation written in Elixir/BEAM. The spec is licensed Apache 2.0. The repository is explicitly labeled a "low-key engineering preview for testing in trusted environments" — those are the words in the GitHub README, not marketing copy. OpenAI has been equally explicit that it does not plan to maintain Symphony as a standalone product.
The Problem It Solves
Babysitting 3–5 Codex sessions in tabs
Before Symphony, OpenAI's own engineers were running Codex in parallel browser tabs and CLI sessions — one session per task, each requiring human attention to prompt the next step, approve tool calls, and redirect when the agent went sideways. Three to five sessions was roughly the limit a single engineer could supervise before context-switching itself consumed the productivity gains.
The engineers framing this are explicit about what they diagnosed: "The agents were fast, but we had a system bottleneck: human attention." The problem wasn't agent capability — it was that the coordination model was still human-centered. Every agent needed a human in its loop to dispatch, monitor, and merge.
Why interactive coding agents hit a context-switching ceiling
The ceiling is structural. Interactive coding agents — whether accessed through a web app or CLI — are designed around a human prompting them, reviewing their output, and deciding what comes next. Scaling from one agent to ten doesn't multiply output by ten; it multiplies the human coordination burden by ten. Symphony's design premise is that the dispatch and monitoring loops should be automated, leaving humans to review completed work rather than supervise in-progress work.
How Symphony Works
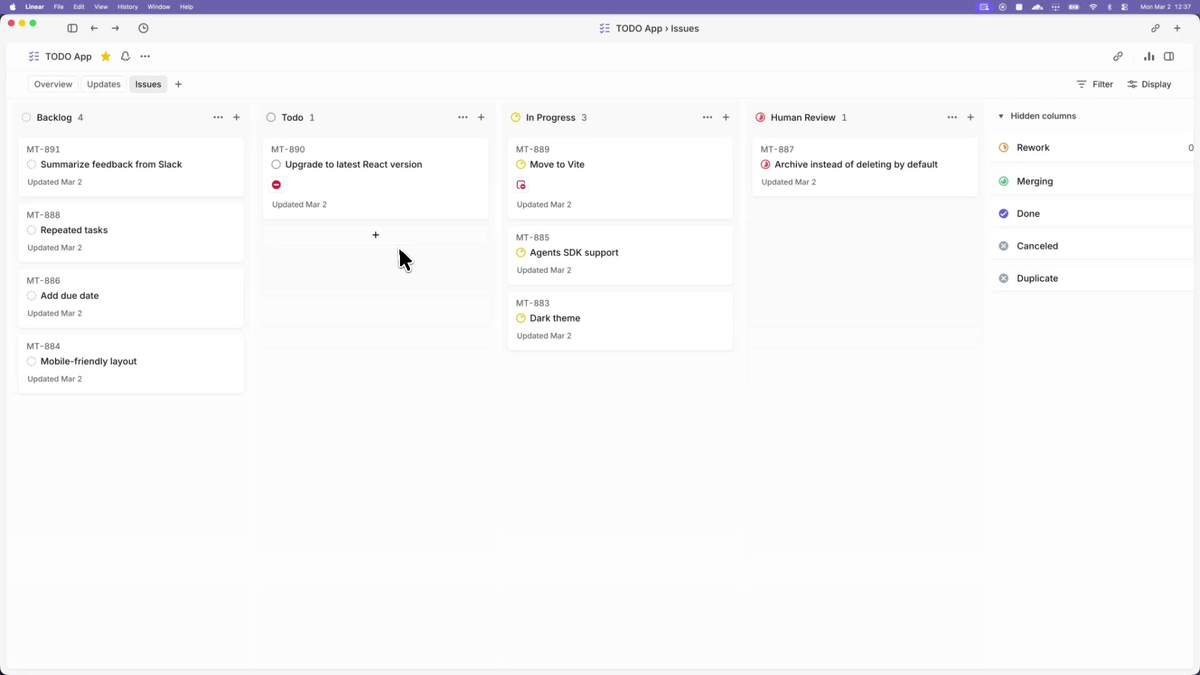
Issue tracker as the control plane (Linear in the reference implementation)
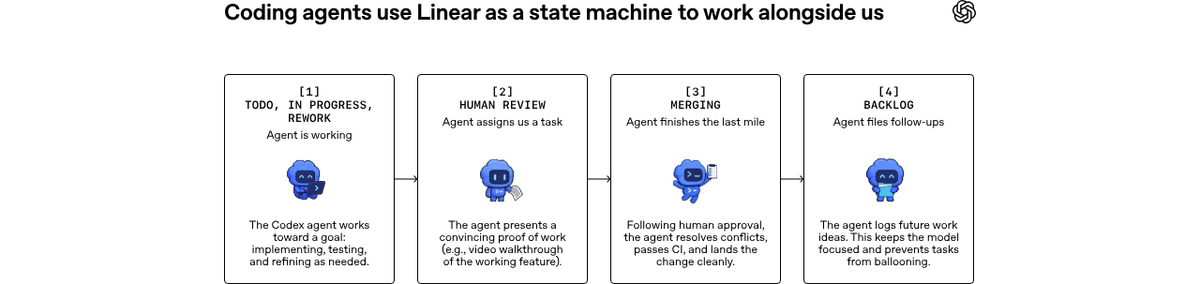
Symphony treats the issue tracker as a state machine. In the reference implementation, each Linear issue maps to one agent workspace. Symphony continuously polls the board, picks up eligible issues (those in an "active" workflow state), dispatches a Codex agent per issue, and tracks progress. If an agent crashes or stalls beyond a configurable stall_timeout_ms, Symphony terminates and restarts it. New issues get picked up automatically; completed issues transition to human review.
The SPEC.md defines the protocol — how to read from an issue tracker, how to manage agent lifecycle, how retries and backoff work, how workspaces are assigned and cleaned up. The spec uses MUST/SHOULD/MAY RFC language for implementation requirements, making it implementable in any language. Codex built the reference Elixir implementation itself, and OpenAI used parallel ports in TypeScript, Go, Rust, Java, and Python to stress-test the spec.
One agent per open issue, isolated workspace per run
Each issue gets its own filesystem workspace. Agents don't share state or interfere with each other's working trees. The SPEC.md defines a Run as "one execution attempt for one issue" and a Workspace as "filesystem workspace assigned to one issue identifier." If a run fails, Symphony queues a retry with exponential backoff (delay = min(10000 × 2^(attempt-1), max_retry_backoff_ms); default maximum backoff 300 seconds).
Plan → execute → "Proof of Work" → human review
The workflow Symphony describes: an agent analyzes the issue, generates an implementation plan (optionally decomposing it into subtasks with dependencies in a DAG), executes the work in its isolated workspace, opens a pull request, and moves the issue to a human review state. The "Proof of Work" concept in the announcement refers to the PR as the artifact — agents are measured by whether their output convinces a human to merge, not by how they produced it. Zach Brock described the goal shift directly: "changing their goal to 'convince a human to merge this code' is the clear next phase of software engineering."
What Symphony Is Not
Not a standalone product OpenAI plans to maintain
The GitHub README says it plainly: Symphony is "a low-key engineering preview for testing in trusted environments." OpenAI has stated explicitly it does not plan to maintain Symphony as a product. There's no roadmap, no support channel, no SLA. What exists is the spec, the Elixir reference implementation, and the expectation that the community forks, adapts, or reimplements it. Treat it accordingly.
Not a general workflow engine like n8n or Zapier
Symphony does one thing: dispatch coding agents from an issue tracker and manage their execution lifecycle. It doesn't have a visual workflow builder, doesn't connect to arbitrary services, and doesn't handle non-coding automation. The OpenAI team describes it explicitly as "a thin orchestration layer for Codex, designed to sit on top of existing tools rather than replace them."
Not the same as SymphonyAI (the enterprise AI company)
This distinction matters for search intent. SymphonyAI is a separate enterprise AI company unrelated to OpenAI or this project. If you found this article searching for "Symphony AI" or "Symphony enterprise AI" or "SymphonyAI platform," this is not what you're looking for. SymphonyAI is an industrial AI company; openai/symphony is an open-source Codex orchestration spec.
Other projects that also use "Symphony" in their names but are unrelated: Symphony Communications (messaging platform), Apache Symphony (retired project), Symphony OS. This article covers only openai/symphony.
Not recommended for production today
The engineering preview label is not hedging. The README adds: "Symphony works best in codebases that have adopted harness engineering." If your codebase doesn't have hermetic tests, automated CI guardrails, and issue hygiene that agents can act on without clarification, Symphony will surface those gaps immediately and expensively.
Is Symphony Open Source and Free?
Apache 2.0 license — yes, the spec and reference code are free
The spec (SPEC.md) and the Elixir reference implementation are both published under Apache License 2.0. You can use, modify, and redistribute both without restriction and without paying OpenAI. Community members have already published reimplementations that substitute Claude Code for Codex and GitHub Issues for Linear.
But running it costs Codex API tokens
The spec and code are free. Running agents is not — Codex API calls consume tokens, and Symphony running continuously against an active issue board generates a substantial token volume. Dan McAteer, who works on agentic AI at AnswerRocket, reported closing dozens of issues in a week using Symphony but noted explicitly that "the system consumes a large number of tokens during operation." Verify current Codex API pricing at openai.com/api/pricing before planning a budget; token rates change.
The "500% More PRs" Claim — Read Carefully

OpenAI's official blog post states: "a 500% increase in landed pull requests on some teams." That's the full quote with its qualifiers. Unpacked:
"500% increase" means the final volume was 6× the baseline — not that 500 PRs became 501. It's a meaningful absolute change, not a rounding artifact.
"on some teams" — not all teams, not the whole company. The figure comes from the teams that had already adopted harness engineering and had well-structured Linear boards. Teams without those preconditions are not represented in this number.
"in the first three weeks" — a short measurement window during a motivated internal experiment. Novelty effects, selection effects (teams chose to adopt Symphony partly because they expected it to work), and the absence of a published baseline methodology all apply.
No published baseline methodology. OpenAI has not released the measurement methodology, the baseline PR volume, or the team size context. "500% increase on some teams for three weeks under ideal internal conditions" is the honest description of what's documented.
What "harness engineering" means and why it gates the result
OpenAI's term for the preconditions: harness engineering — hermetic tests, automated CI that fails clearly on regressions, and issue descriptions specific enough that an agent can execute without clarification. Symphony without these doesn't produce 500% more PRs; it produces 500% more failed or incorrect agent runs that require human cleanup. The company documented the harness engineering investment in a February 2026 post that predates Symphony. That post is the prerequisite reading.
When Symphony Makes Sense for Developers
Scoped, well-specified issues
Symphony dispatches agents against issue text. If your issues say "fix the performance problem" or "look into the dashboard bug," agents will either fail silently or make expensive guesses. If your issues say "Add rate limiting to /api/users — return 429 with Retry-After header when >100 req/min from same IP; existing tests are in tests/api/test_users.py," agents can execute against that. Issue quality is the first constraint.
Repos already practicing harness engineering
If your CI passes on code that introduces regressions, Symphony will merrily merge those regressions. The automated test suite is the acceptance gate. Without it, human review has to catch everything — which is exactly the bottleneck Symphony is designed to remove. The prerequisite for Symphony producing the throughput gains OpenAI describes is having already done the harness engineering work.
Trusted environments, not multi-tenant
The README specifies "trusted environments" explicitly. Symphony gives agents filesystem access and the ability to open PRs against your repository. In a personal project or an internal monorepo with trusted contributors, this is manageable. In a multi-tenant environment, a shared codebase with contractors, or any context where agent blast radius is hard to bound, the risk profile is different.
FAQ
Is Symphony free?
The spec and code are free under Apache 2.0. Running Symphony requires Codex API access, which is billed per token. ChatGPT Plus/Pro subscription users get Codex access within plan limits; API usage is billed separately. Check openai.com/api/pricing for current rates before planning workload costs.
Do I need OpenAI Codex specifically?
The SPEC.md is technically model-agnostic — it specifies behaviors, not model names. The reference Elixir implementation invokes Codex through OpenAI's APIs. Community forks have already substituted Claude Code and other agents. If you implement the spec yourself (or use a community implementation), you can wire any agent that supports the targeted app-server mode. Using Codex is the path of least resistance; using another agent requires integration work.
Can I use it with Jira or GitHub Projects?
Linear is what the reference implementation uses. The spec doesn't hard-code Linear — it defines a normalized IssueRecord that any tracker can provide. Community ports to GitHub Issues already exist. Jira would require building the integration against the spec's tracker interface. The effort is proportional to how closely your tracker's API maps to the spec's state machine model.
Is the Elixir/BEAM stack a hard requirement?
No. The Elixir implementation is the reference — a demonstration of how the spec works end to end. Zach Brock's framing: "Instead of code, Symphony is first a Spec.md that you can materialize into any programming language you want by passing it to your coding agent of choice." OpenAI stress-tested the spec with parallel ports in TypeScript, Go, Rust, Java, and Python. The BEAM/OTP supervision tree is a good fit for managing flaky agent processes, but other runtimes can handle the same responsibilities differently.
Is Symphony the same as SymphonyAI?
No. SymphonyAI is an enterprise industrial AI company with its own products and platform, entirely unrelated to OpenAI. The name overlap is coincidental. openai/symphony is an open-source Codex orchestration spec. If you're evaluating enterprise AI for industrial operations, you're looking for SymphonyAI's website, not this GitHub repository.
Related Reading
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- Claude Code Routines Explained for Dev Teams
- What Is oh-my-codex (OMX)? Orchestration Layer for Codex CLI
- Superpowers vs Vibe Coding: Structured Agents vs Freeform Prompts
