
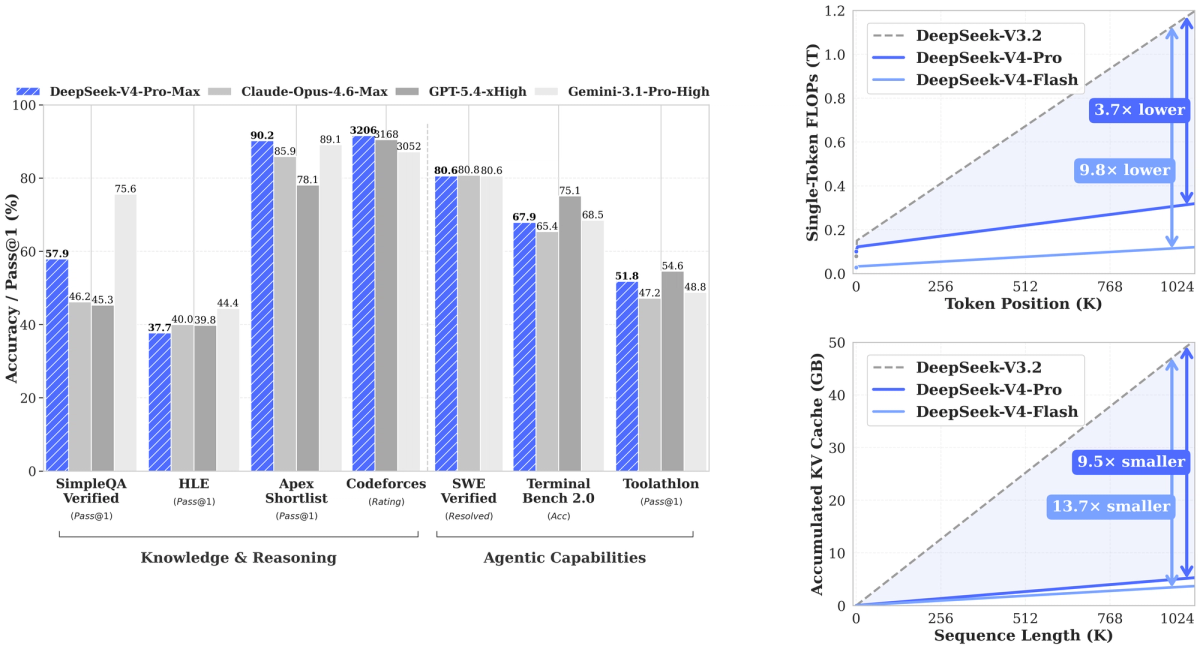
Three days after V4 dropped, a colleague pinged me: "MIT license, weights are out, we're moving our coding agent off the API." I asked one question — what GPU setup are you running? The answer was two A100 80GBs. That's when I said wait. Not because self-hosting V4 is wrong, but because two A100s and V4-Flash are a mismatch that will waste weeks. "Open weights are available" and "self-hosting is a good fit for your team" are two different sentences. This article is about the second one.
What DeepSeek Actually Open-Sourced
Open weights vs hosted API
Both V4-Pro and V4-Flash are MIT-licensed with weights publicly available on Hugging Face. MIT is as open as it gets — commercial use, modification, redistribution, fine-tuning, all permitted without restriction. There are no usage caps, no attribution clauses, and no revenue thresholds that trigger obligations. This is a genuine open-weight release, not a research-only or non-commercial drop.
What's not included: inference infrastructure, operational runbooks, SLAs, or guaranteed reproducibility of the hosted API's performance on your hardware. The weights are the model; the rest is your problem.
What is public today on Hugging Face
Three checkpoints matter for self-hosted coding teams:
deepseek-ai/DeepSeek-V4-Flash — the native FP4+FP8 mixed-precision build, approximately 146GB on disk. This is the most efficient checkpoint, but it requires NVIDIA Blackwell (B200) hardware for the FP4 expert weights. On Hopper-class GPUs (H100), the FP4 kernels don't run.
sgl-project/DeepSeek-V4-Flash-FP8 — the FP8-only quantized build for H100, approximately 284GB on disk. This is what teams with H100s should actually download, not the native checkpoint. Requires 8× H100 80GB to fit the weights and maintain usable KV cache headroom.
deepseek-ai/DeepSeek-V4-Pro — the flagship, approximately 865GB. Requires Blackwell (B300/B200) for native FP4 execution at single-node scale; two-node H200 clusters for full 1M-token context on Hopper.
The official DeepSeek V4 Hugging Face collection has all three, with model cards that specify which inference engines are supported for which hardware.
Why Open Weights Matter for Coding Teams
Control, privacy, and model routing
Three things that open weights unlock that the hosted API cannot provide:
Data sovereignty. For teams in regulated industries — healthcare, finance, defense, legal — where code and business logic cannot leave the network perimeter, the hosted API is a non-starter regardless of quality or price. Open weights under MIT remove both the licensing and the data-residency problem simultaneously.
Model routing control. With self-hosted V4-Flash, you control the routing logic. You can run V4-Flash for 90% of requests and call the hosted API for the remaining 10% that need V4-Pro's reasoning depth — without a vendor dependency deciding when the model scales up or what it costs when it does.
Fine-tuning surface. The Base checkpoints (not Instruct) enable fine-tuning on domain-specific coding tasks. Standard LoRA pipelines via TRL or Axolotl work; the MoE routing architecture doesn't change the fine-tuning math. For teams with proprietary coding patterns, internal APIs, or domain-specific languages, fine-tuning is the path to quality that the hosted API can't match.
When open weights change ROI
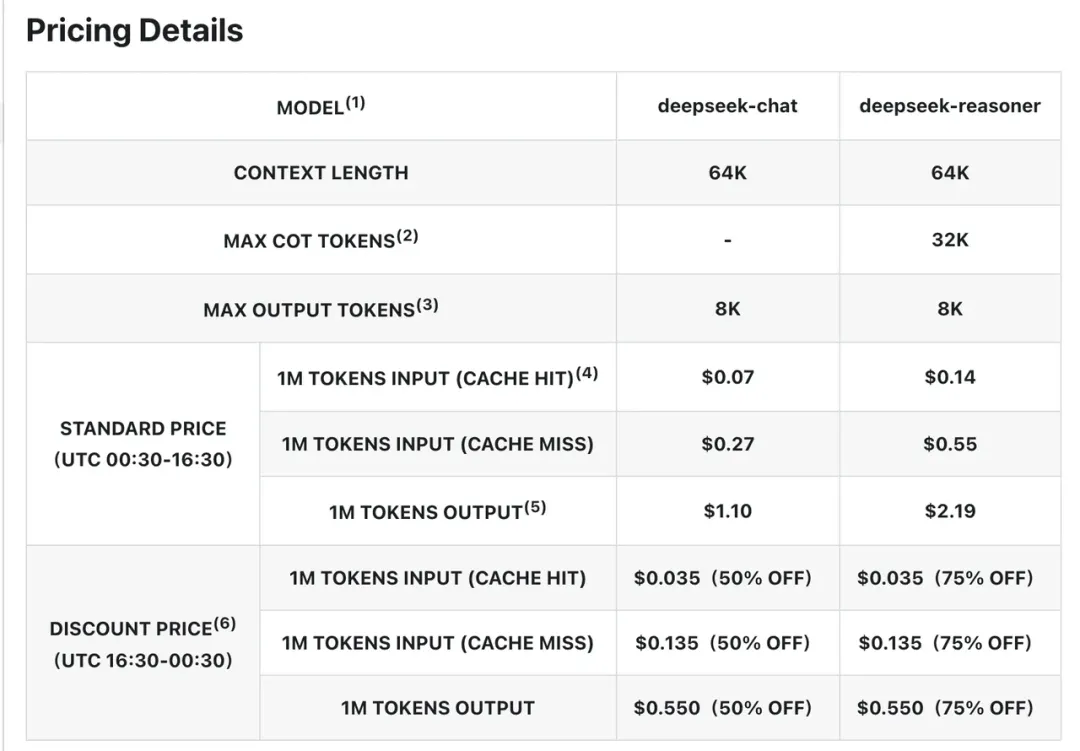
The hosted V4-Flash API costs $0.14/M input and $0.28/M output per the official pricing page. Self-hosting a 2× H200 instance on RunPod costs approximately $7.18/hour, or roughly $5,170/month at continuous operation. The break-even calculation:
| Monthly token volume | Hosted API cost | 2× H200 self-hosted | Verdict |
|---|---|---|---|
| 10M tokens/month | ~$3–$4 | $5,170 | API wins |
| 100M tokens/month | ~$35–$42 | $5,170 | Close — API still cheaper |
| 200M tokens/month | ~$70–$84 | $5,170 | Self-hosted starts to win |
| 500M tokens/month | ~$175–$210 | $5,170 | Self-hosted clearly wins |
The break-even for V4-Flash sits at approximately 200M+ tokens per month with reserved instances (which reduce costs roughly 40% versus on-demand). Below that threshold, the hosted API is cheaper and carries zero infrastructure overhead. If data sovereignty is the driver rather than cost, this math is irrelevant — self-hosting wins regardless of token volume.
What Self-Hosted Teams Must Verify First
Hardware and serving requirements
The single biggest mismatch risk: assuming that "fits on H100s" means "fits on your H100s." The hardware requirements break into two separate questions — does the model fit in VRAM, and does the VRAM leave room for KV cache at the context length you actually need?
V4-Flash on H100 (Hopper): Must use the FP8-quantized build (sgl-project/DeepSeek-V4-Flash-FP8, ~284GB). This requires 8× H100 80GB with tensor parallelism across all eight cards just to load the weights. The remaining VRAM headroom for KV cache at that configuration supports context lengths up to approximately 256K tokens comfortably. Full 1M-token context requires more — either 4× H200 or a configuration with additional VRAM.
V4-Flash on Blackwell (B200): The native FP4+FP8 checkpoint (~146GB) runs on 4× B200 with full 1M context and room for KV cache. NVIDIA's Blackwell platform is the clean deployment path; H100 is the available-hardware path with meaningful constraints.
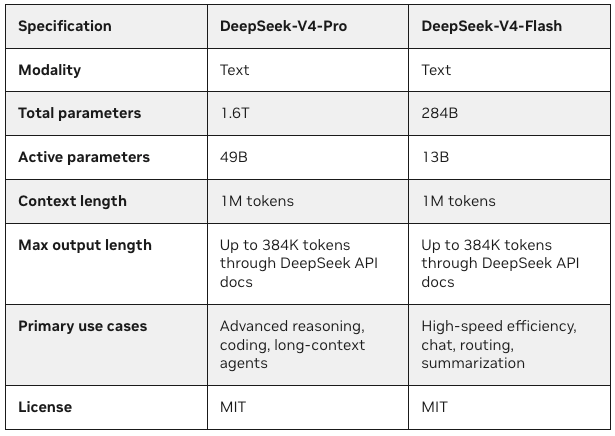
V4-Pro: Single-node Blackwell (8× B300) for native FP4 at full scale. Two-node H200 cluster for Hopper-based full 1M context. Running V4-Pro on anything smaller means compromised context length, not just reduced throughput.
Inference frameworks at launch: vLLM 0.9.x and SGLang have Day-0 official support per the release note. TGI has no V4 support as of this writing. Ollama and llama.cpp have community GGUFs but these are unverified against DeepSeek's official checkpoints. For production coding agents, vLLM or SGLang are the only validated paths.
Latency vs hosted API trade-offs
The hosted DeepSeek V4-Flash API runs at approximately 83.8 tokens per second output throughput per the Artificial Analysis data. Self-hosted V4-Flash on 2× H200 with SGLang and speculative decoding can match or exceed this — but only if your configuration is tuned for your request mix. Misconfigured tensor parallelism, suboptimal batch sizes, or insufficient VRAM for your actual context lengths will produce throughput significantly below the hosted API baseline.
First-token latency (time to first token) is where self-hosted deployments often underperform API access, particularly for small batches and shorter contexts. The hosted API benefits from batching across thousands of concurrent users; your self-hosted instance batches only your own traffic. For interactive coding agents where per-request latency matters more than throughput, this is a real trade-off.
Tool-calling and agent workflow compatibility
Both V4-Pro and V4-Flash are OpenAI ChatCompletions-compatible. Any existing OpenAI SDK integration points at your self-hosted endpoint with a base URL change — no code modification beyond the endpoint and model parameters.
Tool-calling behavior is supported, but "interleaved thinking across tool calls" is a new capability in V4 that is explicitly preview-stage behavior. RunPod's deployment analysis noted this directly: tool-calling with concurrent thinking traces is new enough that subtle behavior changes before final release are expected. For coding agents that chain tool calls with reasoning — web search, file operations, code execution — verify your specific workflow before committing to self-hosted V4 in production.
The reasoning effort modes (non-thinking, thinking, thinking-max) work locally via the thinking_mode parameter in vLLM and SGLang. Verify against your serving framework version; the parameter was documented at Day 0 but behavior consistency across framework versions hasn't been tested at scale.
Where Open Weights Help
Internal evaluation and sandboxed workflows
The strongest immediate use case: running V4-Flash in a sandboxed internal environment for evaluation against your actual coding workloads before committing to the hosted API at scale. You get the real model, not a demo, at infrastructure cost rather than per-token cost. Run your benchmark tasks, tune your prompts, measure task completion rates. If V4-Flash meets your quality bar, you have two deployment paths — self-hosted at scale or hosted API — and the evaluation cost doesn't change which one you pick.
For teams building coding agents on sensitive codebases, internal evaluation is the only evaluation that matters. Benchmark scores on public repositories don't predict performance on your internal codebase.
Multi-model routing and cost control
An emerging pattern: self-host V4-Flash for the high-volume, latency-tolerant work (batch refactoring, documentation generation, test generation), and route hard reasoning tasks to either hosted V4-Pro or a higher-tier closed model. You control the routing logic, the cost cap per request, and the fallback behavior when V4-Flash fails verification. This is architecture that the hosted API doesn't enable because you don't control the routing.
The MIT license means you can modify the model weights for routing decisions — for example, fine-tuning a smaller router model to classify requests before dispatching to V4-Flash or a more capable model. This degree of control is only available with open weights.
Where the Risks Still Are
Deployment complexity
DeepSeek V4's hybrid attention architecture (CSA + HCA) and MoE structure are newer than what vLLM and SGLang have been optimized against for years. Day-0 support means the serving recipes work; it does not mean they've been hardened against edge cases. The engineering overhead of maintaining a V4-Flash deployment — monitoring, version updates, serving framework upgrades, quantization testing as tooling matures — is real and tends to be underestimated in the first month after an open-weight release.
Teams that have operated self-hosted LLMs before will find the V4 deployment familiar. Teams running their first self-hosted model will discover that "download the weights and run vLLM" is the easy part.
Benchmark claims vs real engineering tasks
DeepSeek's official technical report shows V4-Flash in Think Max mode matching V4-Pro on LiveCodeBench (91.6% Pass@1) and HMMT 2026. RunPod's deployment analysis flagged a harder-to-verify data point: long-context retrieval at 1M tokens hits approximately 66% in real workloads, not the near-perfect performance the benchmark conditions produce. At 1M token context — the use case most likely to drive teams toward V4 in the first place — retrieval quality degrades at the practical ceiling.
For coding workflows that depend on accurate long-context retrieval (loading full repo history, multi-file dependency analysis, long accumulated tool-call chains), verify retrieval accuracy on representative examples before treating the 1M context as reliable for production.
Maintenance burden after launch hype fades
Preview-stage models update. The behavior that works today may not be the behavior in the final release. For self-hosted teams, this means tracking DeepSeek's model updates, validating that your serving framework version stays compatible, and re-testing your agent workflows when behavior changes. The hosted API absorbs this maintenance silently; the self-hosted path does not.
Three months after a major open-weight release, the teams that regret self-hosting are typically the ones that underestimated ongoing maintenance versus the ones that underestimated initial setup. Price the maintenance cost honestly before the infrastructure decision.
FAQ
Is DeepSeek V4 fully open source?
The model weights and architecture are MIT-licensed — fully open for commercial use, modification, and distribution. The training code, training data, and RLHF pipeline are not public. "Open-weight" is the accurate term; "open-source" in the sense that includes training infrastructure is not. For deployment and fine-tuning purposes, the distinction rarely matters. For research reproducibility, it does.
Can self-hosted teams match the hosted experience?
On throughput: yes, with the right hardware and serving configuration. On latency for small-batch interactive workloads: often no — the hosted API batches across thousands of users, which reduces per-request latency below what a private deployment achieves. On reliability: depends on your infrastructure investment. On long-context behavior at 1M tokens: the 66% retrieval ceiling appears consistent across hosted and self-hosted configurations — it's a model limitation, not an infrastructure limitation.
Is V4 a good fit for enterprise coding workflows?
V4-Flash is a strong fit for high-volume, cost-sensitive enterprise coding tasks where the hosted API's per-token pricing is a constraint and internal deployment is acceptable. V4-Pro is the fit for complex reasoning-intensive coding tasks where GPT-5.5 or Claude Opus 4.7 pricing is prohibitive and self-hosted infrastructure is available. Neither is a fit for enterprises without GPU infrastructure investment or without engineering teams experienced in serving MoE models. The "enterprise fit" question is really a question about internal infrastructure capability, not model quality.
Conclusion
DeepSeek V4's open weights under MIT are a meaningful shift in what's possible for self-hosted coding teams. The license is genuinely permissive, the hardware requirements are documented, and the inference ecosystem has Day-0 support. None of that makes self-hosting the right call for most teams today.
The teams that should move now: compliance-constrained organizations where the hosted API is not an option, and teams running 200M+ tokens per month where the break-even math is already clear. The teams that should wait: anyone whose GPU setup is below the hardware requirements, anyone who hasn't run the token volume math, and anyone who hasn't evaluated whether V4-Flash's quality actually meets their coding workflow requirements on their own codebase.
The weights being available is the starting condition, not the conclusion.
Related Reading
- DeepSeek V4 Preview for Coding: What Actually Changed
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
- What Is Kimi K2.6? Moonshot AI's Open-Weight Agent Model Explained
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
