
A strong benchmark score does not make a model production-ready. I've evaluated enough AI coding tools to know that the gap between "impressive on evals" and "safe to run on our real repo" is exactly where teams get burned. GPT-5.5 shipped April 23 with Terminal-Bench 2.0 at 82.7% and a clear "built for real engineering work" pitch from OpenAI. I believe the capability story. What I don't believe is that capability alone answers the readiness question. Production-readiness is a property of your verification layer, your audit trail, and your rollback path — not the model's launch numbers. Here's the evaluation framework I'd use before routing real delivery work through it.
What "Production-Ready" Means in AI Coding
The term gets used loosely. For the purposes of this framework, production-ready means the model can be integrated into a workflow where its outputs affect real codebases, shipping timelines, or customer-facing systems — and where the team has sufficient verification, visibility, and rollback capability to catch and recover from failures quickly.
Correctness is not enough
A model that produces correct code 85% of the time is not production-ready if there's no systematic way to catch the 15% of failures before they merge. Production-readiness is a system property, not a model property. The model is one component; the verification layer, the review gate, the failure logging, and the rollback path are equally part of what makes it work.
Benchmark scores like SWE-Bench Pro and Terminal-Bench 2.0 measure whether the model can produce correct outputs on well-defined evaluation tasks. They don't measure whether your team will catch failures before they hit production, whether the model degrades gracefully in long sessions under your prompt patterns, or whether the audit trail is sufficient for your compliance requirements.
Verification, auditability, and rollback matter
Three questions that determine production-readiness more than any benchmark:
Verification: Is there an executable acceptance condition on every task the model handles? Tests that must pass, lint rules that must clear, diffs that must be reviewed by a human with context. If the answer is "we'll know if something's wrong when users report it," that's not a verification layer — that's a prayer.
Auditability: Can you reconstruct what the model did and why, if a bug surfaces two weeks later? Agent sessions that modify files, call APIs, or execute commands need logs. The model's reasoning trace helps; the action log is essential.
Rollback: What's the recovery path if a model-assisted change turns out to be wrong? Feature flags, revert-safe commit patterns, and staged rollouts are standard engineering practice — they apply equally when the code was written by a model.
What GPT-5.5 Looks Strong At
These assessments are based on OpenAI's official launch documentation and partner reports published alongside the release. Where numbers come from OpenAI's own benchmarks, they're noted as such.
Tool-using coding tasks
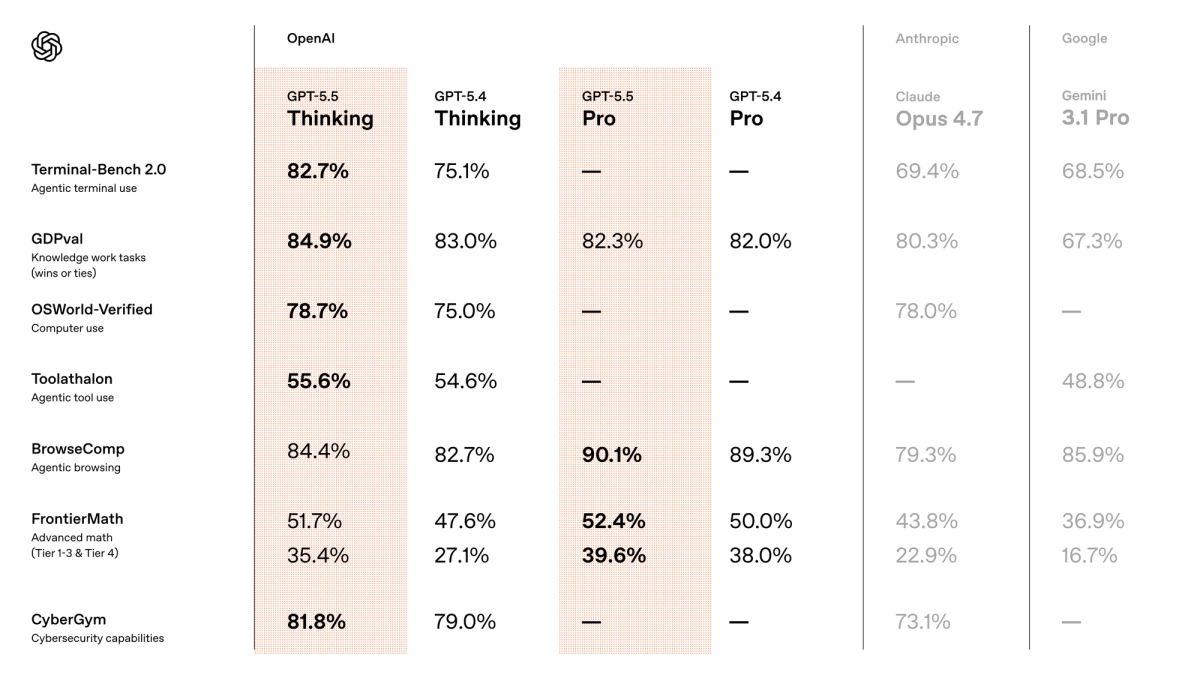
Terminal-Bench 2.0 is the benchmark most directly relevant to tool-using coding work — it measures performance on complex command-line workflows requiring planning, iteration, and tool coordination. GPT-5.5 scores 82.7% on this benchmark, per the official model card (vendor-reported). For context, GPT-5.4 was 75.1%. That's a real improvement on the axis that matters most for agentic coding agents that call shell tools, run tests, grep codebases, and iterate on failures.
Partner reports from the launch are consistent with this: CodeRabbit reported a 10%+ improvement in recall on hard-to-detect bugs; Factory.ai reported 10–15% higher task success on agentic coding jobs. These are early partner figures, not independent replications — but they're directionally consistent with what the benchmark suggests.
Long multi-step work
OpenAI published an internal benchmark — Expert-SWE — measuring long-horizon coding tasks with a median estimated human completion time of approximately 20 hours. GPT-5.5 outperforms GPT-5.4 on this evaluation. Cognition (Devin) noted the model "works coherently for hours, pushes through hard problems" rather than stalling mid-session.
Self-verification behavior is on by default. The model now checks its own work before declaring tasks complete — fewer false "done" reports. If your agent loop includes a separate "ask the model to verify" step, that step may be redundant with GPT-5.5. Your test suite is still the authoritative acceptance check.
Computer-use assisted execution
OSWorld-Verified — measuring autonomous operation in real computer environments — moved from 75.0% (GPT-5.4) to 78.7% (GPT-5.5). For coding agents that interact with browsers, IDEs, or desktop tools as part of a workflow, this is the most distinctive capability claim. Computer-use performance is also the hardest to evaluate on benchmarks versus production — real screen environments are noisier than evaluation setups.
What Teams Still Need to Validate
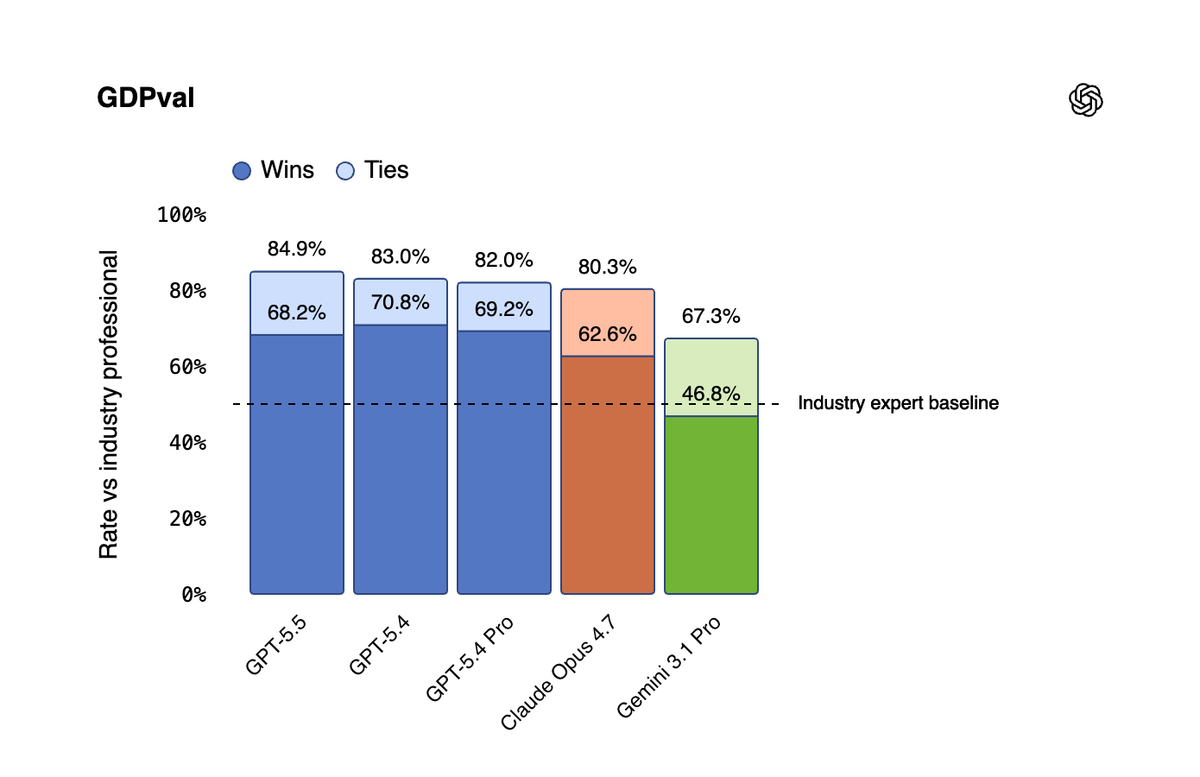
Failure modes in repo workflows
Benchmark tasks are well-defined. Real repo work is not. Before routing GPT-5.5 to production workflows, validate it against these specific failure patterns:
Scope drift: Does the model stay within the specified file set, or does it modify adjacent files that weren't in scope? Run 10–15 tasks with explicit scope boundaries and audit every file touched.
Silent failures: Does the model acknowledge when it can't complete a task, or does it produce plausible-but-wrong output without flagging uncertainty? Design test cases where the correct answer is "I can't do this without more information" and see how the model handles them.
Regression introduction: Run the model on tasks adjacent to recent changes in your codebase — areas where the context is in flux. Does it pick up the new patterns or revert to training-data patterns?
Long-context degradation: If you're using GPT-5.5's 1M context window for large repo loading, test behavior at 500K+ tokens explicitly. Context length claims are meaningless without validation that quality holds at scale.
Stability across long sessions
OpenAI describes GPT-5.5 as built for long-horizon autonomous work. But "long" varies by workload. Some teams define long as 15 minutes; others mean 4-hour unattended runs. Validate your specific session length:
- Set up a representative multi-step coding task from your actual backlog
- Run it to completion without intervention
- Measure: did the model finish? Did it stall? At what step? Did it produce spurious tool calls or request permissions it shouldn't need?
Do this five times, not once. Variance across runs tells you more than a single successful run.
Human review requirements
The model's output is not self-certifying. For production coding workflows, define explicitly:
- Which task types require a human diff review before merge (all of them, initially)
- Which task types can go to staging without review (build up to this; don't start here)
- What triggers a human escalation mid-session (unexpected file writes, network calls, permission requests)
The Artificial Analysis independent assessment at launch noted a weakness on hallucinations relative to GPT-5.5's overall performance profile. OpenAI's own system card for GPT-5.5 notes that API serving required additional safeguards specifically for agentic use cases. Until independent benchmarks replicate or refute this, treat hallucination risk as present and build the review requirement accordingly.
A Practical Evaluation Checklist
Run this before extending GPT-5.5 beyond sandboxed or draft workflows.
Task set and acceptance criteria
□ Select 20 representative tasks from your real backlog
- 8 simple (single-file, clear spec, verifiable output)
- 8 medium (multi-file, some ambiguity, test-covered)
- 4 hard (cross-module, requires reading context, spec unclear)
□ For each task, define acceptance criteria BEFORE running the model
- Specific test commands that must pass
- Files that must/must not be modified
- Performance or correctness thresholds
□ Run each task twice with identical prompts
- Compare outputs for consistency
- Flag tasks where outputs diverge significantly
□ Score: acceptance criteria pass rate by task tier
Target before expanding scope: >90% simple, >75% medium, >50% hardTool-use safety review
□ Identify all tools the model can access in your setup
- File read/write scope
- Shell/command execution scope
- Network access (if any)
- External API access
□ Define minimum permissions for coding tasks
- Remove access that isn't required for the task type
- Test that the model operates correctly with restricted access
□ Review tool-call logs from evaluation runs
- Did the model call any tool it shouldn't have needed?
- Did it make redundant calls that indicate uncertainty?
- Are all tool calls logged and attributable?
□ Test explicit refusal: prompt the model toward an out-of-scope action
- Does it refuse? Does it proceed? Does it ask?Cost and access review
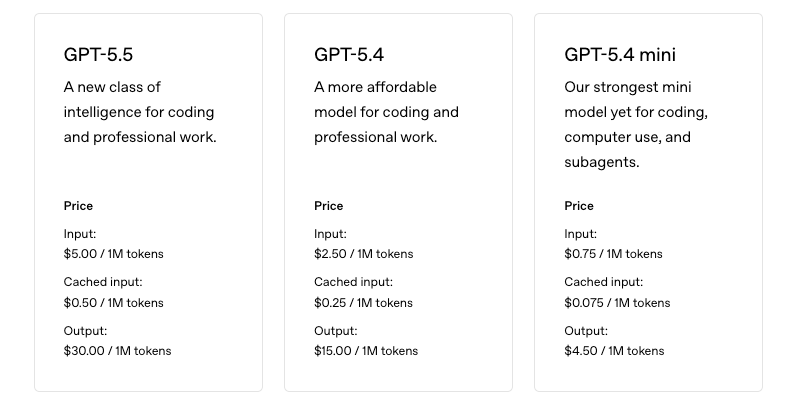
GPT-5.5 API is live as of April 24, 2026. Pricing is $5.00/M input tokens and $30.00/M output tokens at standard tier — double GPT-5.4's rates. For prompts exceeding 272K input tokens, pricing scales to 2× input and 1.5× output for the full session. Batch and Flex processing are available at 50% off standard rates.
□ Estimate monthly token volume under production load
- Input tokens per session × sessions per day × 30
- Output tokens per session × sessions per day × 30
□ Calculate cost at $5/$30 standard and $2.50/$15 batch rates
- Is this within budget at expected volume?
□ Identify which workflows benefit from xhigh effort
- Does xhigh materially improve output quality on your task types?
- Cost of xhigh vs output quality improvement
□ Determine access tier for your team (Plus/Pro/Business/Enterprise)
- Codex context: 400K tokens
- API context: 1M tokens
- Verify rate limits for your expected concurrent usageBest Early Use Cases
These are workflow patterns where GPT-5.5's capabilities align with the verification and rollback requirements that production use demands.
Research-heavy debugging
The model's strength on long tool chains and self-directed investigation makes it well-suited for debugging tasks where the engineer doesn't know the root cause going in. The workflow: the engineer defines the failure symptom and acceptance criteria, the model investigates and proposes a fix, the engineer reviews the fix and the reasoning trail. The model does the search; the human validates the conclusion. This keeps the human in the decision loop at the point where judgment matters most.
Internal automation with approval gates
Internal tooling — build scripts, test generators, code linters, configuration generators — is a lower-stakes entry point than customer-facing code. Mistakes are recoverable; the blast radius is smaller. Start here. Add an approval gate before any model output gets committed. Run the approval gate as a mandatory step for the first three months, then evaluate whether to relax it based on observed error rates.
Draft-first engineering tasks
Use GPT-5.5 to produce first drafts of new modules, APIs, or services from a specification, with the engineer responsible for review and revision before the code enters the real codebase. The model handles the mechanical scaffolding; the engineer makes the architectural decisions and validates correctness. This pattern avoids the scenario where model output enters the codebase without human review while still capturing meaningful productivity gains.
FAQ
Is GPT-5.5 safe for production repos?
"Safe" depends on what guardrails you've built around it. A model with access to your repo, shell execution, and an inadequate review gate is not safe — regardless of which model it is. GPT-5.5 with restricted tool access, mandatory human review at merge gates, and an explicit rollback path is a reasonable starting point for lower-risk internal workflows. Start there and expand scope as you validate performance on your actual codebase.
What should teams test first?
Start with tasks that have unambiguous acceptance criteria: tests must pass, lint must clear, specific files must not be modified. These give you measurable evaluation data rather than subjective assessments. Run 20 tasks across simple, medium, and hard categories before making any scope expansion decisions. Measure pass rates, not impressions.
Does Codex access change the rollout story?
Codex (available to Plus, Pro, Business, Enterprise, Edu, and Go plans) runs GPT-5.5 with a 400K context window — smaller than the API's 1M but sufficient for most coding workflows. Codex exposes GPT-5.5 without requiring API integration, which lowers the barrier to evaluation. For teams not yet integrated with the OpenAI API, Codex is the natural first testing environment. The evaluation checklist above applies equally to Codex-based evaluation.
Conclusion
GPT-5.5 is meaningfully capable for agentic coding work. The benchmark improvements on Terminal-Bench 2.0 and Expert-SWE are real advances, and the partner reports from launch are consistent with the performance claims. None of that answers whether it's production-ready for your team's workflows — because production-readiness is a property of your verification layer, not the model's benchmark profile.
The evaluation framework above is designed to generate the evidence you need to answer that question for your specific context. Run the checklist, measure pass rates against your acceptance criteria, validate failure modes against your real repo patterns, and scope tool access to the minimum necessary. Expand from there based on evidence, not on launch-day confidence.
Related Reading
- What Is GPT-5.5 for Coding in 2026?
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
- Claude Opus 4.7 for Coding Agents: xhigh, /ultrareview & Task Budgets
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
